java2之前
枚举(Enumeration)接口:定义了一种从数据结构中取回连续元素的方式。
位集合(BitSet)类:实现了一组可以单独设置和清除的位或标志。
向量(Vector)类:相当于动态数组,可以动态改变数组大小。
栈(Stack) Vector子类:实现了一个后进先出(LIFO)的数据结构。
字典(Dictionary)抽象类:定义了键映射到值的数据结构(作用和Map类相似)。
哈希表(Hashtable)类:提供了一种在用户定义键结构的基础上来组织数据的手段(已被继承到集合框架中)。
属性(Properties)Hashtable.Properties子类:表示了一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。
缺点:缺少核心,统一的主题
java2新引入
集合框架(Collection)
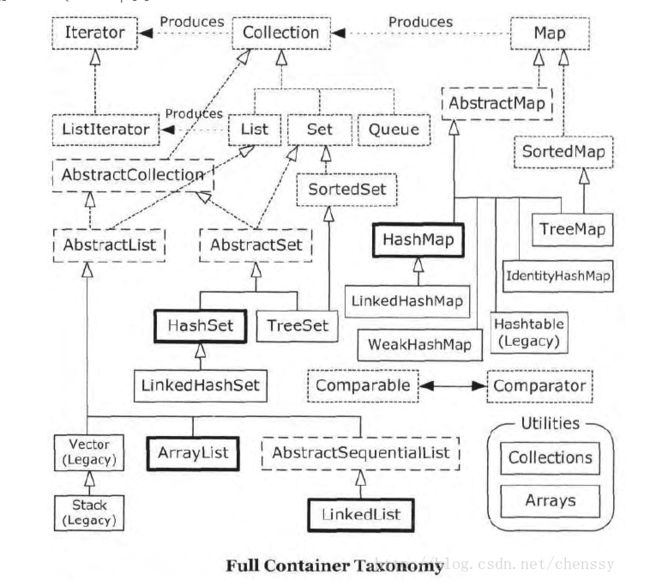
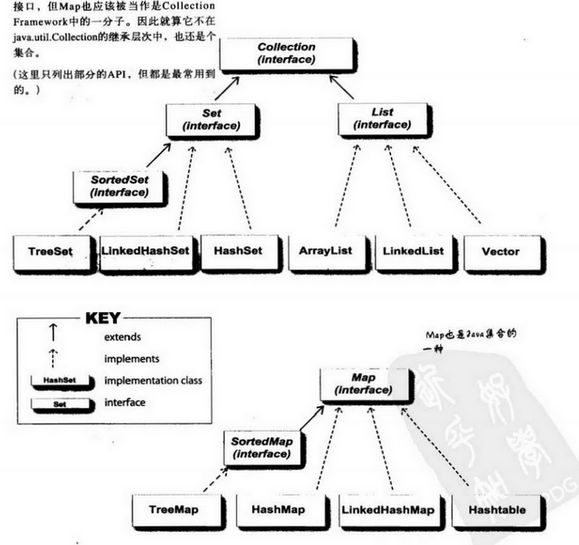
Collection接口:
Collection接口是最基本的集合接口,它不提供直接的实现,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。它代表的是一种规则,如是否允许重复,是否支持排序等。
使用场景
List VS Set VS Map
List:1.元素有放入顺序,元素可重复;
2.查找元素效率高,插入删除元素效率低(会引起其他元素位置改变);
Set:1.元素无放入顺序,元素不可重复,重复元素会覆盖掉;
2.检索元素效率低,删除和插入效率高(插入和删除不会引起元素位置改变);
Map:适合储存键值对的数据;
ArrayList VS LinkedList
ArrayList:1.基于 动态数组 的数据结构,地址连续(在内存里是连着放的)
2.查询效率高,插入和删除操作效率低(要移动数据)
LinkedList:1.基于 链表 的数据结构,地址任意(开辟内存空间时不需要等一个连续的地址)
2.查询效率低(要移动指针),插入删除效率高,适合头尾操作(双链表)或插入指定位置
注:实际还需看情况,单条数据插入或删除:ArrayList > LinkedList ;
批量随机的插入删除:LinkedList > ArrayList;
HashSet VS Treeset
HashSet:1.基于HashMap实现
2.无序
3.可以放入null,但只能有一个null,值不能重复
4.性能通常优于TreeSet(因为基于Hash算法实现),适合快速查找
TreeSet:1.基于二叉树(红黑树结构)
2.有序
3.不可以放入null值,值不能重复
4.适用于需要排序的功能时
HashMap VS TreeMap VS HashTable
HashMap:1.基于哈希表实现(底层实现是数组,数组每一项是链表)
2.无序(是指插入k1,k2,k3,遍历时顺序未必是k1,k2,k3)
3.key,value允许为空
4.适用于Map中插入、删除和定位元素
TreeMap:1.基于红黑树的数据结构
2.有序
3.不允许键对象为 null 或是 基本数据类型(因为 TreeMap 中的对象必须是可排序的)
4.适用于按自然顺序或自定义顺序遍历键(key)
HashTable:与HashMap相似的实现
区别:1.key,value不允许为空
2.线程安全
性能:HashMap > HashTable > TreeMap (因素:基于hash算法和线程安全)
线程安全对比
非线程安全:LinkedList,ArrayList,HashSet,HashMap,TreeMap,StringBuilder
线程安全:Vector,HashTable,StringBuffer
集合的有序、无序、排序性质
有序、无序:是指插入元素时,保持插入的顺序性,也就是先插入的元素优先放入集合的前面部分。
排序:是指插入元素后,集合中的元素是否自动排序。(例如升序排序)
有序集合:集合里的元素可以根据key或index访问(有序集合在属性的增加,删除及修改中拥有较好的性能表现)
无序集合:集合里的元素只能遍历。
HashMap、 HashSet、 HashTable 等 基于哈希存储方式的集合是无序的。其它的集合都是有序的。
TreeMap TreeSet 等集合是排序的。
对集合的选择
对List的选择 :
1.对于随机查询与迭代遍历操作,数组比所有的容器都要快。所以在随机访问中一般使用ArrayList
2.LinkedList使用双向链表对元素的增加和删除提供了非常好的支持,而ArrayList执行增加和删除元素需要进行元素位移。
3.对于Vector而已,我们一般都是避免使用。
4.将ArrayList当做首选,毕竟对于集合元素而已我们都是进行遍历,只有当程序的性能因为List的频繁插入和删除而降低时,再考虑LinkedList。
对Set的选择:
1、HashSet由于使用HashCode实现,所以在某种程度上来说它的性能永远比TreeSet要好,尤其是进行增加和查找操作。
2、虽然TreeSet没有HashSet性能好,但是由于它可以维持元素的排序,所以它还是存在用武之地的。
对Map的选择:
1、HashMap与HashSet同样,支持快速查询。
虽然HashTable速度的速度也不慢,但是在HashMap面前还是稍微慢了些,所以HashMap在查询方面可以取代HashTable。
2、由于TreeMap需要维持内部元素的顺序,所以它通常要比HashMap和HashTable慢。
fail-fast机制( throw ConcurrentModificationException)
简介:“快速失败”是Java集合的一种错误检测机制。
eg:当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。
作用:不用等迭代完再告诉你出错了
解决:使用CopyOnWriteArrayList来替换ArrayList
CopyOnWriteArrayList
简介:ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
适用场景:1.在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时;
2.当遍历操作的数量大大超过可变操作的数量时;
原理:任何对array在结构上有所改变的操作(add、remove、clear等),都会copy原有数据,在copy的数据上修改,不会影响原有数据,修改 完成后改变原有数据的引用。
缺点:开销大,产生大量对象,copy数组损耗大
集合使用细节
关于Array.asList:
1.在使用asList时不要将基本数据类型当做参数;
(asList参数接收泛型,基本数据类型无法泛型化,若传int[],则是将数组这个对象泛型化,永远size只有1,需要用Integer[])
2.Arrays.asList()返回的ArrayList是Arrays类的一个内部类(不是java.util.ArrayList),不具备add,remove,长度不可变;
关于subList:
1.subList返回的只是原列表的一个视图,它所有的操作最终都会作用在原列表上;
2.生成子列表后,不要试图去操作原列表,否则会造成子列表的不稳定而产生异常;(Collections.unmodifiableList(list)//将原列表设为只读)
(推荐:使用subList处理局部列表)

Collections集合工具类:comparable接口(只能bean内部实现排序规则),compator(独立bean外部做排序规则)