这个项目,也不难,但有一点我真的不太明白,搞了半天也没搞懂,就是发送post请求的这个地址,是怎么找到的,我玩了一上午的network,各种博客翻了一遍,也没找到,希望有缘人可以给我解释一下,同时我自己也不放弃追求真理,日后有所领悟,会在底部最下方,添加解决方案。
-
创建新项目
如何创建的废话,我就不说了,直接给出我创建后的结构图。
start_renren.py是我创建的启动项。
配置setting
# -*- coding: utf-8 -*-
# Scrapy settings for renren_login project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'renren_login'
SPIDER_MODULES = ['renren_login.spiders']
NEWSPIDER_MODULE = 'renren_login.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'renren_login (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'renren_login.middlewares.RenrenLoginSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'renren_login.middlewares.RenrenLoginDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'renren_login.pipelines.RenrenLoginPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
- renren.py
这部分是这次学习的重点内容:
我们先看看源文件start_request函数的调用方法吧!
查看函数源文件的方法是:按住ctrl然后点击目标函数即可查看。

我们把注意力放在else之后这部分函数:

显然yield函数是遍历start_ur里面的一切url且dont_filter = true不过滤重复的url,默认使用get的方法,故不符合我们发送的post请求,我们想要发送post请求可以重写start_url去覆盖原有的start_url。
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'#搞不明白这个网址哪里找到的
data = {
'email':'[email protected]',
'password':'pythonspider'
}
request = scrapy.FormRequest(url,formdata=data,callback=self.parse_page)
yield request
为了证明证明我们已经登录成功,我们查看一下一个就郑晴的美女的主页,我们将网页信息保存一下:
def parse_page(self,response):
url = 'http://www.renren.com/970771065/profile?ref=hotnewsfeed&sfet=701&fin=1&fid=28280773367&ff_id=970771065&platform=10&expose_time=1564124401'
request = scrapy.Request(url,callback=self.parse_text)
yield request
def parse_text(self, response):
with open('renren.html','w',encoding='utf-8')as fp:
fp.write(response.text)
得到的数据对比一下证明抓取无误:
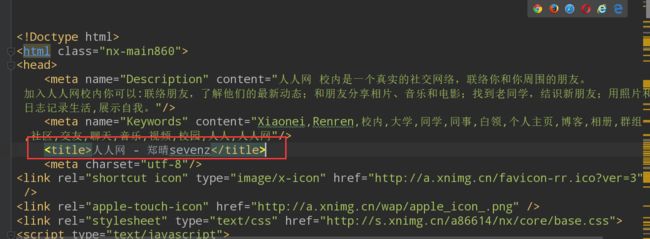
下面给出完整代码:
renren.py:
# -*- coding: utf-8 -*-
import scrapy
class RenrenSpider(scrapy.Spider):
name = 'renren'
allowed_domains = ['renren.com']
start_urls = ['http://renren.com/']
def start_requests(self):
url = 'http://www.renren.com/PLogin.do'#搞不明白这个网址哪里找到的
data = {
'email':'[email protected]',
'password':'pythonspider'
}
request = scrapy.FormRequest(url,formdata=data,callback=self.parse_page)
yield request
def parse_page(self,response):
url = 'http://www.renren.com/970771065/profile?ref=hotnewsfeed&sfet=701&fin=1&fid=28280773367&ff_id=970771065&platform=10&expose_time=1564124401'
request = scrapy.Request(url,callback=self.parse_text)
yield request
def parse_text(self, response):
with open('renren.html','w',encoding='utf-8')as fp:
fp.write(response.text)
总结一下:
- 要发送post请求,推荐使用'scrapy.FormRequest'方法,可以方便的指定表单数据。
- 如果想一开始就发送post请求,就要重写‘start_request’方法,在这个方法中发送post请求。
欢迎路过的朋友点个喜欢,也请路过的朋友们留下宝贵的意见和建议