1.补充视频
1.1 Computing minimal cover
Steps to produce Functions:
1.ReduceRight: ensure all functional dependencies have one attribute on right hand side;
2.ReduceLeft: remove redundant attributes on left hand side;
3.RemoveRedundant: eliminate redundant functional dependencies
例题:
R = {ABCDEG}
F = {A—>BCD, B—>CDE, AC—>E}
After step 1:
A—>B, A—>C, A—>D, B—>C, B—>D, B—>E, AC—>E
After step 2:
consider AC—>E, if remove A, it will be C—>E, while in step 1, C cannot produce anything; if remove C, A—>E, based on step 1, A—>B, B—>E, so A—>E, it works.
A—>B, A—>C, A—>D, B—>C, B—>D, B—>E, A—>E
After step 3:
consider A—>B, if we delete it, based on the rest, A—>C, A—>D, A—>E, but C/D/E cannot produce B, so it cannot be removed.
consider A—>C, if we delete it, based on the rest, A—>B, B—>C, so it can be removed.
A—>B, A—>D, B—>C, B—>D, B—>E, A—>E
consider A—>D, if we delete it, based on the rest, A—>B, B—>D, so it can be removed.
A—>B, B—>C, B—>D, B—>E, A—>E
consider B—>C, it cannot be removed.
consider B—>D, it cannot be removed.
consider B—>E, it cannot be removed.
consider A—>E, if we delete it, based on the rest, A—>B, B—>E, so it can be removed.
A—>B, B—>C, B—>D, B—>E
This is the minimal cover, and the primary key should be AB
1.2 BCNF normalisation
Inputs: a schema R, a set Functional Dependencies(FDs)
Output: a set Res of BCNF schemas
BCNF requirement:
for all FDs X —> Y
either
X —> Y is trivial
or
X is a (super)key
method:
Res = {R}
while (any schema S in Res is not in BCNF) {
choose an fd X —> Y on S that violates BCNF
Res = (Res - S) U (S - Y) U XY
}
Res - S含义是出去S关系的剩余schema,S - Y 同理
例题:
R = ABCDEFGH
FDs = ABH—>C, A—>DE, BGH—>F, F—>ADH, BH—>GE
解法:
(1)找key
关系中F—>ADH是影响最广的,而推出F的是BGH,在BGH三者间,BH—>GE,所以BH更重要,而BH二者间没有推出关系,所以尝试从BH作为key推导。
BH—>GE(BEGH), BGH—>F(BEFGH), F—>ADH(ABDEFGH), ABH—>C(ABCDEFGH),推导出完整的R,所以key是BH。
(2)根据FDs寻找违背BCNF的关系
A—>DE最明显,因为A不是key,BCNF不允许A和其他element建立关系。根据上述方法
Res = {ABCDEFGH}
Fix A—>DE
XY = ADE, S - Y = ABCFGH
Res = {ADE, ABCFGH}
ADE commits with BCNF
(3)根据FDs寻找违背BCNF的关系
R1 = ABCFGH
FDs = ABH—>C, BGH—>F, F—>AH, BH—>G(因为DE被放置在上一步的符合关系中,所有右侧涉及DE的都删除,剩余关系成立)
再次选择key,尝试继续从BH推导:
BH—>G(BGH), BGH—>F(BFGH), F—>AH(ABFGH), ABH—>C(ABCFGH),成立
Key = BH
这次发现F—>AH违背BCNF关系
Fix F—>AH
XY = FAH, S - Y = BCFG
Res = {ADE, FAH, BCFG}
ADE, FAH commit with BCNF
对于剩下的BCFG而言,剩下的所有关系都不成立,ABH—>C中H不在,BGH—>F中H不在,F—>AH中AH都不在,BH—>G中H不在
所以BCFG commits with BCNF
最后结果是{ADE, FAH, BCFG}
1.3 3NF normalisation
Inputs: a schema R, a set F of Functional Dependencies(FDs)
Output: a set Res of 3NF schemas
3NF requirement:
for all FDs X—>Y
either
X—>Y is trivial
or
X is a (super)key
or
Y is a single attribute and Y is in the key
methods:
F’ = condensed minimal cover of F
Res = {}
for each fd X—>Y in F’ {
if (no schema S in Res contains XY)
Res = Res U XY
}
if (no schema S in Res contains key(R))
Res = Res U key(R)
例题:
R = ABCDEFGH
F = ABH—>C, A—>D, C—>E, BGH—>F, F—>AD, E—>F, BH—>E
(1)minimal cover:
ABH—>C, A—>D, C—>E, BGH—>F, F—>A, F—>D, E—>F, BH—>E
BH—>C, A—>D, C—>E, BH—>F, F—>A, F—>D, E—>F, BH—>E
BH—>C, BH—>E, F—>A, F—>D, E—>F
(2)key:
key = BHG
(3)F’:
F’ = BH—>CE, E—>F, F—>AD
BHCE(key = BH), EF(key = E), FAD(key = F), BHG(key = BHG)
2. Week9 Continue
继续上周的normal forms,重点是BCNF和3NF。简述如下:
2.1 BCNF
对于所有的FDs X-->Y
(1)要么X是superkey
(2)要么Y是X的子集
做BCNF decomposition的时候,从全集R开始,对于任意一个不符合BCNF的FD关系,拆解出来,更新FDs,直到全部符合BCNF。
2.2 3NF
对于所有的FDs X-->Y
(1)要么X是superkey
(2)要么Y是X的子集
(3)或者Y是candidate key的一个attribute
做3NF decomposition的时候,从空集开始。先把所有的FDs做minimal cover,过程是先拆解右侧FDs,再拆解左侧FDs,最后检查有没有任何FD是冗余的。将所有minimal cover组合成table,如果其中未包括candidate key,要加入candidate key形成一个table。
3. DBMS Architecture
DBMS应用中常见的technique有两类:query processing(QP)用来提升查询效率,transaction processsing(TxP)用来保障数据库安全。
在数据库效率考量中:
join比子查询效率高,如果subquery中包括外层查询的信息,那么效率更低;
要尽可能先筛选filter后输出返回;
减少在where和group by语句中的函数使用;
如果已有的数据很少做更新,那么可以建立indexes提升查询效率,代价是每次update都要同时update真实关系和index。
例如:
select name from Employee
where salary > 50000 and
empid in (select empid from WorksIn
where dept = 'Sales')
使用了subquery效率低,可以更新为:
SalesEmps = (select empid from WorksIn where dept='Sales')
foreach e in Employee {
if (e.empid in SalesEmps && e.salary > 50000)
add e to result set
}
或者写成:
select name
from Employee join WorksIn using (empid)
where Employee.salary > 5000 and
WorksIn.dept = 'Sales'
还可以更新为:
SalesEmps = (select * from WorksIn where dept='Sales')
foreach e in (Employee join SalesEmps) {
if (e.salary > 50000)
add e to result set
}
DBMS的构成如下:
--File manager: manages allocation of disk space and data structures
--Buffer manager: manages data transfer between disk and main memory
--Query optimiser: translates queries into efficient sequence of relational operations
--Recovery manager: ensures consistent database state after system failures
--Concurrency manager: controls concurrent access to database
--Integrity manager: verifies integrity constraints and user privileges

4. Relational Algebra
Relational Algebra (RA)通常包括:
--operands: relations, or variables representing relations
--operators that map relations to relations
--rules for combining operands/operators into expressions
--rules for evaluating such expressions
4.1 Selection
可以理解为筛选tuples,减少rows,课上使用的表达法是Sel[expr](Rel),标准表达法是σexpr(Rel)。
例如:SelC,从关系r(R)中选择一个条件为C的子集tuples。
4.2 Projection
可以理解为筛选attributes,减少columns,课上使用的表达法是Proj[A, B, C](Rel),标准表达法是ΠA,B,C(Rel)。
例如:Proj[X](r),从关系r(R)中选择attributes X。
4.3 Product
课上使用的表达法是Rel1 Join[expr] Rel2。
例如:r ✖️ s,要注意r和s可能有attribute命名相同,为了避免名字的冲突,要对一些attribute重命名。
4.4 Join
(1)Natural Join: r Join s,选取r和s中attribute一致的所有tuples。
r Join s = Proj[R U S](Sel[match](r ✖️ s))
(2)Theta Join: r JoinC s,在条件C下join,如果条件C是True,则与笛卡尔积一致(r ✖️ s)
4.5 Union
r1 U r2,与集合关系一致,但是和sql不同,RA不允许重复element。
4.6 Intersection
r1 ∩ r2,与集合关系一致,但是和sql不同,RA不允许重复element。
4.7 Difference
r1 - r2,代表只属于r1,不属于r2的所有elements。
4.8 Division
r/s,显示的column是r - s的attributes,显示的tuples是所有在r中包含全部s的tuples value的value。
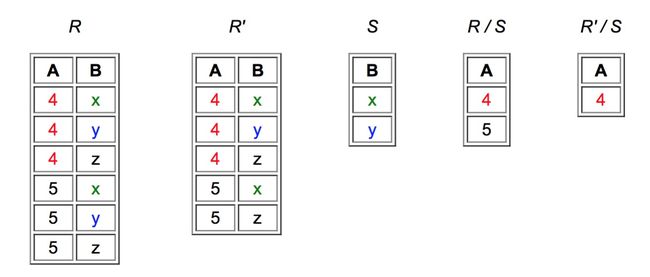
4.9 Rename
课上使用的表达法是Rename[schema](Rel)。
例如:如果expression E returns a relation R(A1, A2...An),那么Rename[S(B1, B2...Bn)](E)。tuples还是E,但是Ai改名为Bi