
一、Zookeeper的安装和配置
1.解压文件
2.进入解压目录,配置相关文件
2.1 修改conf文件夹下的zoo_sample.cfg,重命名为zoo.cfg
打开进入,修改Datadir,并添加如下语句
dataDir=/usr/share/zookeeper-3.5.0-alpha/data
dataLogDir=/usr/share/zookeeper-3.5.0-alpha/logs
server.0=Master:2888:3888
server.1=Slave1:2888:3888
server.2=Slave2:2888:3888
记得”3888”后不要有空格!然后我们创建设置的文件夹
最后再在data下创建myid文件,值设为0
最后把主节点的zookeeper复制到从节点,并修改myid分别为1, 2

2.2 启动zookeeper集群
移动到解压目录下的bin文件夹
在三个节点上执行./zkServer.sh start

最后用./zkServer.sh status命令查看


三个节点查看后,一共两个follower,一个leader,配置成功。(leader不一定是在master上,因为它有自己的选举机制)
二、Hbase的安装与配置
Hbase是一种非关系型数据库,NoSQL,但其实是有两种解释的:not sql 和 not only sql,怎么说呢,应该是介于两者之间的。NoSQL的特点是使用键值对存储数据和分布式,并且读写性能很高,适合我们大数据下的工作。接下来是具体的配置过程。
1.解压文件
2.为.bashrc文件添加环境变量
然后source一下
1.进入解压目录下的conf文件,配置相关信息
3.1 编辑hbase-site.xml,添加如下信息

其中hbase.rootdir端口必须与你的Hadoop集群的core-site.xml文件配置保持完全一致
(这里的Mastre打错了,应该是Master)
3.2 编辑hbase-env.sh,在末尾添加如下
因为hbase运行在zookeeper的基础之上,这个东西就是告诉它我们配置了zookeeper,你用我们配置的,而不是你自带的。
3.3 编辑regionservers,添加从节点

4.通过scp命令把hbase发送到从节点上,并为从节点配置环境变量
5.先启动hadoop,然后再启动zookeeper集群
6.进入hbase文件bin目录下,执行 ./start-hbase.sh
再用jps命令分别查看主节点和从节点,启动成功。


三、Hive的安装与配置
Hbase是一种数据库,而Hive则是一种数据仓库,建立在Hadoop的基础上,提供了一系列工具可供数据的提取转化和加载,这是一种的存储、查询、分析存储在Hadoop中的大规模数据的机制。
具体安装流程如下:
1.解压,设置环境变量并随手source一下
2.进入hadoop目录下,修改etc下的配置文件hadoop-env.sh,添加如下
3.进入解压目录的conf文件夹下
3.1 把hive-default.xml.template重名命为hive-site.xml
3.2 把hive-env.sh.template重命名为hive-env.sh,并添加如下内容
4.进入解压目录的bin文件夹下,修改hive-config.sh文件

4.接下来是和MySQL的连接(之前已经安装好了)
5.1先从官网上下载驱动包

将mysql-connector-java-5.1.43-bin.jar包解压到hive目录下的lib文件夹中
5.2修改 conf文件夹下的hive-site.xml文件,只需修改如下四个点
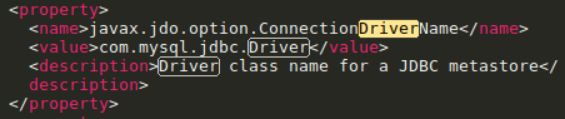



这一个value值为你root下MySQL的真实密码
*5.3 有些可能还需要修改另三个属性hive.exec.scratchdir,hive.exec.local.scratchdir,hive.downloaded.resources.dir,把他们的值设置为绝对路径,否则后面启动会出错
6.通过mysql给hive权限,登录mysql
5.1执行
GRANT ALL PRIBILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '**your password**' WITH GRANT OPTION;
flush privileges;
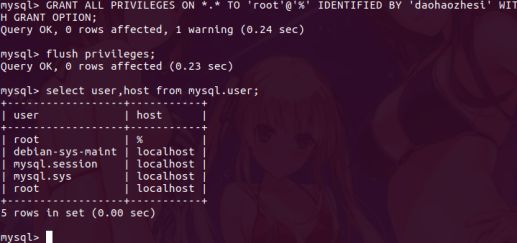
select user,host from mysql.user;
6.2修改/etc/mysql/mysql.conf.d/mysqld.cnf 文件,注释掉如下这一行
6.3 重启mysql服务sudo /etc/init.d/mysql restart
7.启动hadoop,再进入hive进行操作
执行hive
执行CREATE TABLE test2(id int,name string); 创建一个新表
执行SHOW TABLES; 可以看到我们创建的表已经在里面了

四、Sqoop 1.99.7的安装与配置
Sqoop是一个转换工具,用于在关系型数据库与HDFS之间进行数据转换。
1.解压,设置环境变量并随手source一下
2.进入解压目录下的conf文件夹下
2.1 配置sqoop.properties
org.apache.sqoop.submission.engine.mapreduce.configuration.directory=/home/ubuntu17/hadoop-3.0.0-alpha4/etc/hadoop
org.apache.sqoop.security.authentication.type=SIMPLE
org.apache.sqoop.security.authentication.handler=org.apache.sqoop.security.authentication.SimpleAuthenticationHandler
org.apache.sqoop.security.authentication.anonymous=true
3.配置Hadoop代理访问
找到Hadoop的core-site.xml配置文件
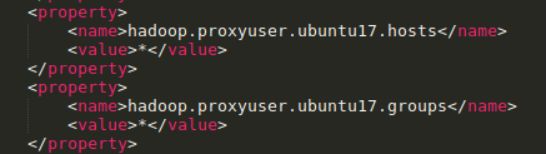
这里的ubuntu17是指你用什么用户在访问,如果你使用root的话,就把ubuntu17修改为root
4.配置驱动文件
一般我们使用的数据库驱动包都没有随着Sqoop一起释出,多半是因版权问题,所以将这些包放置在这个第三方组件下。再在配置一个SQOOP_SERVER_EXTRA_LIB系统变量即可,指定路径为$SQOOP_HOME/extra,最后把mysql的驱动jar文件复制到这个目录下。


5.启动sqoop服务
在解压目录的bin文件夹下执行
./sqoop2-tool upgrade
./sqoop2-tool verify
./sqoop2-server start
出现了SqoopJettyServer则成功。
6.执行
sqoop2-tool upgrade 初始化
sqoop2-tool verify 检查是否配置正确
sqoop2-shell 进入shell操作界面
至此结束,如果有错误的话欢迎指出(~ ̄▽ ̄)~