5.1 WebKit缓存概述
WebKit缓存包含MemoryCache、DiskCache和PageCache三种。
MemoryCache是WebKit最早实现且相对成熟的缓存机制。MemoryCache,顾名思义,就是将资源缓存到内存中,等待下次访问时不需要重新下载资源,而直接从内存中获取。这种缓存方式常用在浏览网页返回上一页操作,当用户浏览器跳转另一个页面时,会缓存上一个页面(缓存空间足够的话可以缓存更多页面资源)的资源,当再次返回上一个页面时,WebKit对已经缓存的资源不再通过网络渠道下载,而是直接从内存中获取数据,大大提高了网页加载的效率。但存在的局限是只能缓存“派生资源”。
DiskCache,顾名思义,就是将资源缓存到磁盘中,等待下次访问时不需要重新下载资源,而直接从磁盘中获取。DiskCache的实现跟平台息息相关,由于本文使用的第三方网络库为curl,所以之后讲解的代码也是curl port代码,它的直接操作对象为CurlCacheManager类。DiskCache与MemoryCache最大的区别在于,当退出进程时,内存中的数据会被清空,而磁盘的数据不会,所以,当下次再进入该进程时,该进程仍可以从DiskCache中获得数据,而MemoryCache则不行。WebKit早已经存在DiskCache代码,但这个功能默认是关闭状态,官方解释,这段代码存在不定性的问题,请慎用!确实,本人曾经研究过DiskCache代码,并使用它,经常会出现一些莫名其妙的错误。或许是现在DiskCache本身机制还存在问题,或许是代码本身逻辑有问题。但不管怎么说,研究这一块对了解WebKit一些缓存机制还是很有帮助的。
PageCache,顾名思义,就是将page描述文档缓存到内存中,解决了MemoryCache的弊端。由于本人对这方面还未曾研究,所以后续也不作详细讲解,感兴趣的朋友可以在网上搜索一些关于这方面的博客。
5.2 MemoryCache详解
由于MemoryCache流程繁多,通过时序图描述太过复杂,所以本人决定用文字描述一下整个缓存步骤。这里我们还是以image为例,大家也可以参考一下在第四章的image加载时序图。
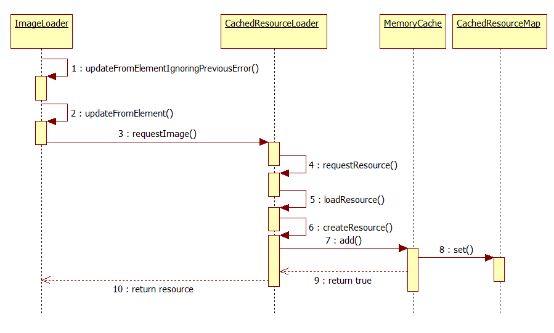
1.解析html页面的时候,解析到img标签,调用
HTMLImageElement::create创建HTMLImageElement对象,该对象包含HTMLImageLoader对象m_imageLoader
2.解析到img的src属性,调用ImageLoader::updateFromElementIgnoringPreviousError
3.调用ImageLoader::updateFromElement
4.调用CachedResourceLoader::requestImage
5.调用CachedResourceLoader::requestResource,根据缓存的情况policy字段确定是否可以从缓存获取(use),或者需要revalidate,或者需要直接从网络获取(load)
6.调用CachedResourceLoader::loadResource
7.根据Resource的类型调用createResource创建对应的CachedResource
8.调用MemoryCache::add在cache中查找是否有对应的cache条目,如果没有创建之
9.调用CachedImage::load
10.调用CachedResource::load
11.调用CachedResourceLoader::load
12.调用CachedResourceRequest::load
13.创建CachedResourceRequest 对象,它将作为SubresourceLoader的client
14.调用ResourceLoaderScheduler::scheduleSubresourceLoad
15.调用SubresourceLoader::create
16.调用ResourceLoadScheduler::requestTimerFired
17.调用ResourceLoader::start
18.调用ResourceHandle::create 发起请求
19.收到HTTP响应头部,调用ResourceLoader::didReceiveResponse
20.调用SubresourceLoader::didReceiveResponse处理响应头部,特别是同缓存相关的头部,比如304的status code。如果是304则直接向缓存获取,如果是200则通过网络加载
21.调用ResourceLoader::didReceiveResponse
22.收到体部数据,调用ResourceLoader::didReceiveData
23.调用SubresourceLoader::didReceiveData
24.调用ResourceLoader::didReceiveData
25.调用ResourceLoader::addData将数据存储到SharedBuffer里面
26.调用CachedResourceRequest::didReceiveData
27.数据获取完毕,调用ResourceLoader::didFinishLoading
28.调用SubresourceLoader::didFinishLoading
29.调用CachedResourceRequest::didFinishLoading
30.调用CachedResource::finish
31.调用CachedResourceLoader::loadDone
32.调用CachedImage::data,创建对应的Image对象,解码
很清楚的看到,MemoryCache涉及到一个关键的类就是“MemoryCache”。在MemoryCache.cpp中可以看到如下代码:
MemoryCache* memoryCache()
{
static MemoryCache* staticCache = new MemoryCache;
ASSERT(WTF::isMainThread());
return staticCache;
}
你会发现MemoryCache是标准的单例模式!如果想了解MemoryCache相关功能,研究MemoryCache.cpp已经完成足够。
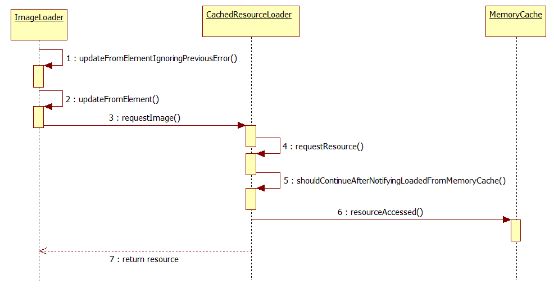
MemoryCache时序图:
MemoryCache为了避免内存溢出,除了可以缓存资源以外,还提供了一套清理缓存资源的机制。这部分实现也在MemoryCache.cpp可以找到,下面我们通过文字的形式来看看这个流程。
调用MemoryCache::prune()清理缓存入口函数
调用MemoryCache::pruneDeadResources()首先清理Dead的缓存,这里Dead的缓存代表页面已经销毁,但还保留其数据的缓存
调用MemoryCache::deadCapacity()计算dead缓存容量大小,返回capacity
计算targetSize=capacity * cTargetPrunePercentage;将targetSize传给下面函数
调用MemoryCache::pruneDeadResourcesToSize()开始清理Dead缓存
调用MemoryCache::pruneLiveResources()清理Live的缓存,这里的Live缓存指页面加载完,保留的缓存
调用MemoryCache::liveCapacity()计算live缓存容量大小,返回capacity
计算targetSize=capacity * cTargetPrunePercentage;将targetSize传给下面函数
调用MemoryCache::pruneLiveResourcesToSize()开始清理Live缓存
注:在清理Dead或者Live缓存时,存在一个关键参数cTargetPrunePercentage,初始值被设置为0.95,targetSize=capacity * cTargetPrunePercentage,当清理的m_deadsize(或m_livesize) <=targetSize,就不在清理;所以其实清理只清理了要清理capacity的5%,剩下的95%都未清理。当判断需要再清理时,还是走以上流程,只清理5%。
5.3 DiskCache详解
前面已经简单介绍过了DiskCache。DiskCache与MemoryCache相似之处就是也只能存储一些派生类资源文件。它的存储形式为一个index.dat文件,记录存储数据的url,然后再分别存储该url的response信息和content内容。Response信息最大作用就是用于判断服务器上该url的content内容是否被修改。具体详见:
http://baike.baidu.com/link?url=n5nx7f8fGB_-B3OieAvMvJIGeBNvipb9qGQhYO0YwwBLg6oxqv_05Up3JUJk4jZyAd-KiCM1Hmg4nR23B5BhSq
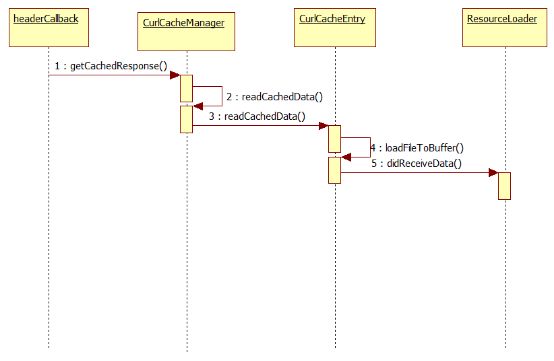
下面我们简单讲解一下DiskCache的流程:
1.webkit已启动,就会创建CurlCacheManager对象
2.CurlCacheManager构造函数会调用CurlCacheManager::setCacheDirectory
3.调用fileExists判断文件夹是否存在,如果存在继续,否则调用makeAllDirectories创建文件夹
4.调用CurlCacheManager::loadIndex(),如果本地有缓存文件,它就会从磁盘读取出来,并将数据保存在m_index这个变量中,该变量类型为HashMap>,分别对应url和数据内容。
5.调用headerCallback函数,返回code status为304未修改,就会去调用CurlCacheManager::getCachedResponse(),如果是200,就会下载数据,并将数据的url保存在一个m_LRUEntryList中
6.调用CurlCacheManager::readCachedData()
7.调用CurlCacheEntry::readCachedData()
8.调用CurlCacheEntry::loadFileToBuffer()将文件中的内容读取出来保存在一个buffer中
9.调用ResourceLoader::didReceiveData()将数据获取,此时数据没有通过网络下载,直接从本地获取
10.Webkit退出时,调用CurlCacheManager::~CurlCacheManager()
11.调用CurlCacheManager::saveIndex(),该函数会去将m_LRUEntryList中的url获取并写入index.dat文件中
5.4 本章小结
本文讲解了MemoryCache和DiskCache的功能以及一些方法实现,帮助大家了解WebKit缓存机制。这里强调一下,WebKit的缓存机制算法主要是“最近使用算法”。当然,本文并未完全剖析WebKit的缓存机制一些细节处理,感兴趣的朋友可以自己研究一番!