现在的我:很幸福的在追逐自己的梦想,不管前路如何,先走着
我们曾经如此渴望生命的波澜,到最后才发现:人生最曼妙的风景,竟是内心的淡定与从容;我们曾是如此期盼外界的认可,到最后才知道:世界是自己的,与他人毫无关系。-------杨绛先生
第一弹:英语
1.Boy,I know they say you can't change your parants... 常言道 父母是无法交换的
2.As smeone who's recently been dumped.
dump:倾倒,抛弃,被甩
3.Oh,man I never thought I'd be here... 没想到自己会沦落到这个地步。
4.Sorry,I'm late ,I was stuck at work. 抱歉,我迟到了,工作太忙。
be stuck at work 工作太忙
5.Give me a 'for instance' 举个栗子
6.I believe Julia's on the table...? 茱莉亚 可以作为备选吗?
7.My maid of honour. 我的伴娘。
8.I ever imagined this moment in my life being.
我从没想过自己会沦落到这步田地。
第二弹:日语:
1.まさか 金目当ての女だったとは。
没想到你竟然是冲着钱去的女人。
2.返す気のない 金を借りるのは 詐欺ですよ。
没有还的打算向别人借钱,这是欺骗呦。
3.一度 尾行を見破らせれば 警戒は解ける。
跟踪被发现一次,警戒就解除了。
4.また お越しいただけるよう 心より お待ち申し上げます。
诚心恭候您下次来访。
5.見たくもないようなもん 結構見るしね。
不想看的东西,倒是见了不少。
第三弹:
《1》笨办法学Python的课本:python练习13和练习14(没有在IDLE上运行的玩意儿)
这就是传说中的横竖都是错,已经疯了
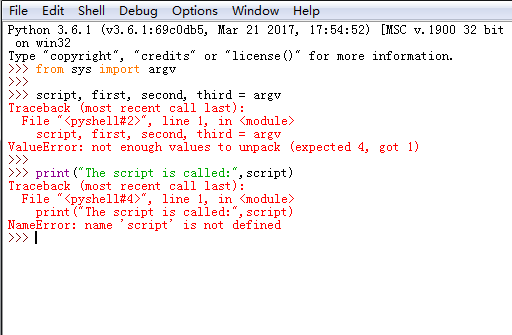
笔记:练习13:参数、解包、变量
1.一开始,真心不会啊,不知道怎么会缺少参数数量(默默的查解决办法去)

笔记:
1.百度+知乎:解决问题的办法:
1).先在编辑器写好代码:
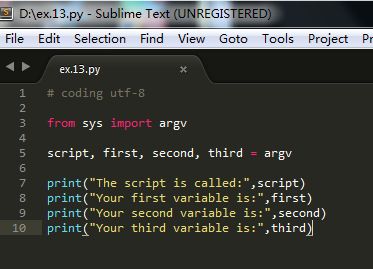
2)以“ex.13.py”的名字保存到某个目录下,我保存到了D盘目录里

3)启动cmd,因为CMD是默认的C盘
需要先输入:D:
然后,再输入:Python ex.13.py first second third(菜鸟的我,又一次在这里犯了符号写错的错儿,操作了三遍才成了)

2.Argv:参数变量(argument variable)
编码器里的第三行:script,first, second,third = argv,是将argv"解包"(unpack),与其将每个参数放到同一个变量下面,不如将每个参数赋值给一个变量:script....third。
3.错误:
not enough values to unpack (expected 4, got 1)参数数量不足,少三
4.argv 和 raw_input()有什么不同
不同点在于用户输入的时机。
如果参数是在用户执行命令时就要输入,那就是argv
如果是在脚本运行中需要用户输入,那就是raw_input()。
练习14:提示和传递
在编辑器写好的代码:

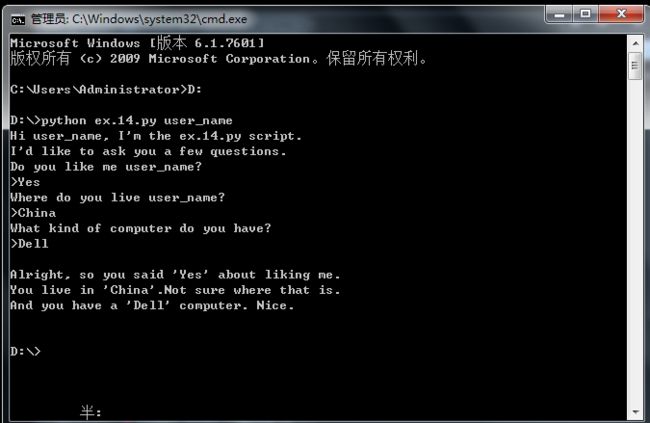
我师父已经教我看视频弄到2.7版本了,可是,我不知道是什么覆盖了,只能用3.6版本,把raw_input()改成input()使用。
笔记:
1.三个"""可以定义多行字符串,而%是字符串格式化的工具
2.user_name可以改成自己的名字,我怕我以后看笔记时傻眼,就没改。
3.错误:NameError:name 'prompt' is not defind。
还真是书里觉得我会犯啥错我就真的犯啥错,我把prompt 写成了“promot”,拼写错误。
4.在练习14的末尾课本里说,不要使用IDL运行本课的代码。其实,你用powershell,cmd.exe就行了,我就喜欢cmd,因为现在还不没研究powershell。
《2》视频课,接盗字4,requests库的get()
1.获得一个网页最快的方法就是:
1)r = requests.get(url)-------构造一个向服务器请求资源的Request对象
注意:Python是大小写敏感的玩意,Request的“R”是大写的
r = requests.get(url)-----------返回一个包含服务器的Response对象
2)requests.get的完整使用方法有三个参数包括:
requests.get(url,params=None,**kwargs)
url: 拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数

3)Requests库的2个重要对象
r = requests.get (url)------Response和Request两个
Response对象包括爬虫返回的全部内容(获得网络内容相关)
>>>import requests
>>>r = requests.get("http://www.baidu.com”)
>>>print(r.status_code) #r.status_code检测请求的状态码,状态码是200就是成功
200
>>>type(r)
>>>r.headers #返回get页面请求头部信息
5.务必要牢记的Response的五个属性(哎,啥时候记得住?)
属性 说明
r.status_code HTTP请求的返回状态,200表示成功,404就是失败
r.text HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTPheader中猜测的响应内容编码方式
r.apparent_encoding 从内容分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
使用顺序:
----r.status_code---200-----r.text r.encoding r.apparent_encoding r.content
先 检查response对象用r.status_code,随后用后边的的解析访问的内容
看例子吧:


7.区别一下:r.encoding和r.apparent_encoding的区别
属性 说明
r.encoding 从HTTPheader中猜测的响应编码方式
r.apparent_encoding 从内容分析出的响应内容编码模式(备选编码模式)
r.encoding:如果header中不存在charset,则默认编码为ISO-8859-1(不能解析中文)
r.apparent_encoding:(相对准确)根据网页内容分析,并找到期中可能的编码(所以,当用r.ecoding不能正确解码返回内容时,要用r.apparent_encoding来解出相关的编码信息,这也是为啥在例子下半段当把 r.apparent_encoding赋予 r.encoding 之后,就能读到r.text 中的中文了)
8.自己练习爬取取的网页(坏笑脸)
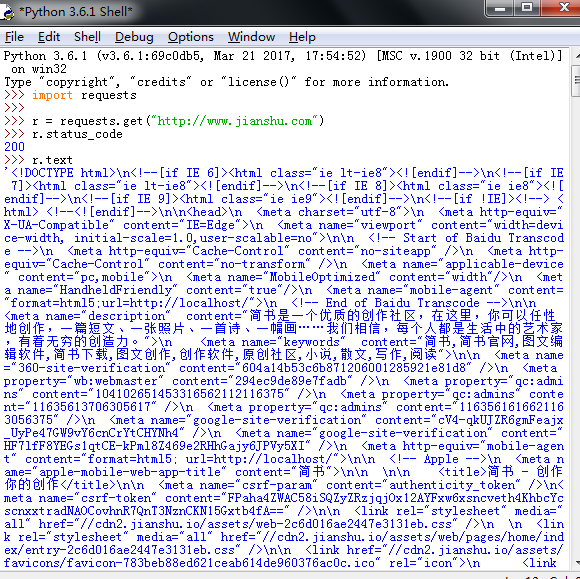
下半部分:我的Dell电脑实在是不给力,不过,结果是这样的
>>>r.encoding
'utf-8'
这是直接弹出的,说明中存在:charset,直接就能解析中文。
爬了这点东西电脑都快崩溃了,下半部分再输入:r.apparent_encoding之后没判断,,买电脑之后再弄吧。