Keras是一个高级别的神经网络库,其中包括一些类似于Scanoit学习的API在Theano或TensorFlow后端。
由于与scikit学习的相似之处,并且强调神经网络设计和测试现在可供大家访问,我将给您一个关于如何使用Keras的快速教程,将其与scikit-learning
Scikit学习是Python开发人员使用的最受欢迎的功能完整的古典机器学习库。在Scikit学习的许多伟大的事情中,我最喜欢的是它的简单,一致和一致的API,它围绕“Estimator”对象构建。 API是对许多工程师已经熟悉的机器学习工作流程的一个很好的描述,并且在整个包装中始终如一地应用。
我们开始导入我们需要的库:scikit-learn,Keras和一些绘图功能
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.utils import np_utils
iris数据
着名的iris数据集(由Ronald Fisher于1936年出版)是展示机器学习框架API的好方法。 在某些方面,这是机器学习的“Hello world”。数据很简单,我们的目标是探索从数据到工作分类器所需的代码,而不是模型设计和选择的细节。
虹膜数据集内置于许多机器学习库中。
iris = sns.load_dataset("iris")
iris.head()
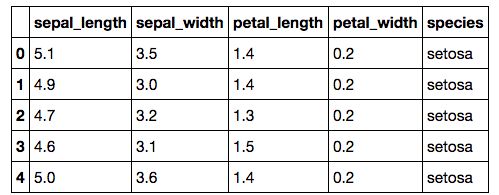
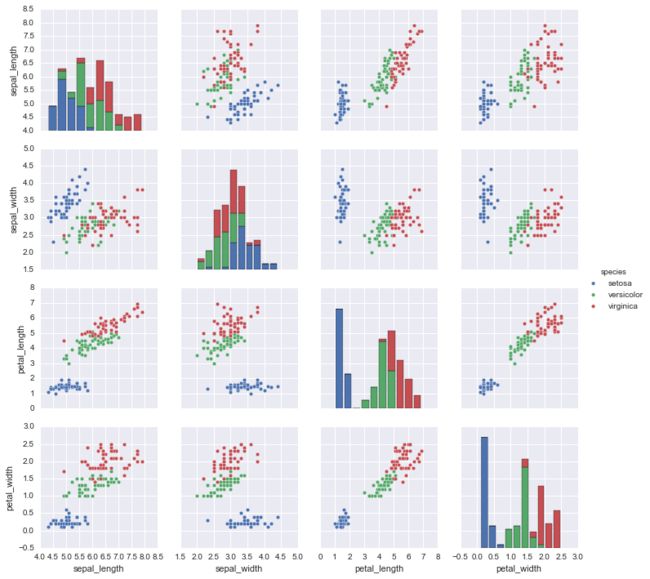
对于每个示例(即,花),存在五个数据。 四个是花的尺寸(厘米)的标准尺寸,第五是iris的种类。 有三种:setosa,verscicolor和virginica。 我们的工作是建立一个分类器,给定两个花瓣和两个萼片测量,可以预测虹膜的种类。 在开始模型构建之前,让我们浏览一下数据情况:
sns.pairplot(iris, hue='species');
拆分数据进行训练和测试
首先我们需要将原始数据从“iris”数据帧中拉出来。 我们将花瓣和萼片数据保存在数组“X”中,并将物体标签保存在相应的数组“y”中。
X = iris.values[:, :4]
y = iris.values[:, 4]
按照监督机器学习的标准,我们将训练一些数据,并用剩余的数据来衡量我们的模型的性能。 这是很简单的手工做,但也被内置在scikit学习作为train_test_split()功能。
train_X, test_X, train_y, test_y = train_test_split(X, y, train_size=0.5, random_state=0)
训练一个scikit学习分类器
我们将训练一个逻辑回归分类器。 这样做,内置的超参数交叉验证,是scikit学习中的一条线。 像所有scikit学习“Estimator”对象一样,LogisticRegressionCV分类器具有一个.fit()方法,可以处理最适合训练数据的学习模型参数的gory数值细节。 所以我们需要做的方法是:
lr = LogisticRegressionCV()
lr.fit(train_X, train_y)
评估分类器准确性
现在我们可以计算训练分类器正确分类的测试集的分数(即精度)。
print("Accuracy = {:.2f}".format(lr.score(test_X, test_y)))
Accuracy = 0.83
keras登场
Keras是由FrançoisChollet在Google创建的高级神经网络库。去年3月27日,公开的Github资料库的初始承诺是一年之久。
正如我们刚刚看到的,scikit学习使得构建分类器非常简单:
- 一行实例化分类器
- 一行训练
- 和一行来衡量其表现
建立分类器在keras也不复杂。数据更新有点变化,我们必须做一些工作来定义网络,然后再将其实例化为分类器,否则与使用scikit学习非常相似。
首先有一点数据显示:scikit-learn的分类器接受字符串标签,例如“setosa”。但是keras要求标签是一个热编码的。这意味着我们需要转换类似的数据
setosa
云芝
setosa
弗吉尼亚
...
看起来像一张桌子
西葫芦
1 0 0
0 1 0
1 0 0
0 0 1
有很多方法可以做到这一点。如果你熟悉pandas,那么那里有pandas.get_dummies(),而一个热编码是在scikit学习。我们只是使用Keras实用程序和一些麻烦。
def one_hot_encode_object_array(arr):
'''One hot encode a numpy array of objects (e.g. strings)'''
uniques, ids = np.unique(arr, return_inverse=True)
return np_utils.to_categorical(ids, len(uniques))
train_y_ohe = one_hot_encode_object_array(train_y)
test_y_ohe = one_hot_encode_object_array(test_y)
构建神经网络模型
除了在这种特殊情况下需要的数据外,使用Keras最重要在于您必须在实例化和使用之前指定模型的结构。
在scikit学习,这些模型是现成的。但是keras是一个神经网络库。因此,虽然数据中的特征/类别数量提供了约束,但您可以确定模型结构的所有其他方面:层数,层的大小,层之间的连接的性质等
因此,建立一个最小的分类器比scikit学习所需的一个工作要多一些。
在我们的例子中,我们将建立一个非常简单的网络。其中两个选择是由我们的数据。我们有四个特征和三个等级,所以输入层必须有四个单位,输出层必须有三个单位。我们只需要定义隐藏层。我们只有这个项目有一个隐藏层,我们给它16个单位。从GPU的角度来看,16是一个整数!当您使用神经网络时,您将看到很多2倍数的值。
我们将以最常见的方式定义我们的模型:作为序贯模型的层。后面的文章我们介绍计算图
model = Sequential()
接下来的两行定义了输入层的大小(input_shape =(4,)),隐藏层的大小和激活功能
model.add(Dense(16, input_shape=(4,)))
model.add(Activation('sigmoid'))
...下一行定义输出层的大小和激活功能。
model.add(Dense(3))
model.add(Activation('softmax'))
最后我们指定优化策略和损失函数进行优化。 我们还定义模型计算准确性。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])
使用神经网络分类器
现在我们已经定义了结构模型并对其进行了编译,我们有一个对象,其API与scikit-learn中的分类器几乎相同。特别是它有.fit()和.predict()方法。我们来训练神经网络通常涉及“小型化”的概念,这意味着向网络显示数据的一个子集,调整权重,然后再显示数据的另一个子集。当网络看到所有的数据一次,这被称为“epochs”。
model.fit(train_X, train_y_ohe, nb_epoch=100, batch_size=1, verbose=0);
编译的keras模型和scikit学习分类器之间唯一的语法API差异是Keras与scikit-learn .score()方法的等价物称为.evaluate()。
evaluate()返回损失函数以及编译模型时我们要求的其他指标。 在我们的例子中,我们要得到精度,我们可以比较我们从scikit学习LogisticRegressionCV分类器的.score()方法得到的精度。
loss, accuracy = model.evaluate(test_X, test_y_ohe, verbose=0)
print("Accuracy = {:.2f}".format(accuracy))
Accuracy = 0.99
如您所见,神经网络模型的测试精度优于简单逻辑回归分类器。
这是令人放心的,但并不奇怪。即使我们非常简单的神经网络具有比logisitic回归学习更复杂的分类表面的灵活性,所以当然它比logisitic回归更好。
而且它隐含了神经网络的一个危险:过度拟合。后文中我们介绍如何防止神经网络过拟合。