最近重新梳理了我职业生涯规划,其中人工智能是我最重要的一个职业方向,所以就开始了人工智能的学习,其中Tensorflow是机器学习中一个很热门的框架,是由Google开源的,是一个不错的方向。由于学习新的技术没有应用到实际项目,所以要留下点博客和github,不然到头来也不知道自己学过什么。
有人说:Tensorflow可能会比 Android 系统更加深远地影响着世界!
学习过程
安装
我是通过Docker镜像安装,安装非常简单了,加上通过Docker安装可以不用污染我们的电脑环境,不需要时直接删除实例即可,我的电脑是Macbook Pro,我使用的Docker可视化工具为Kitematic,输入Tensorflow就可以搜索到,点击CREATE,稍等片刻即可安装完毕。
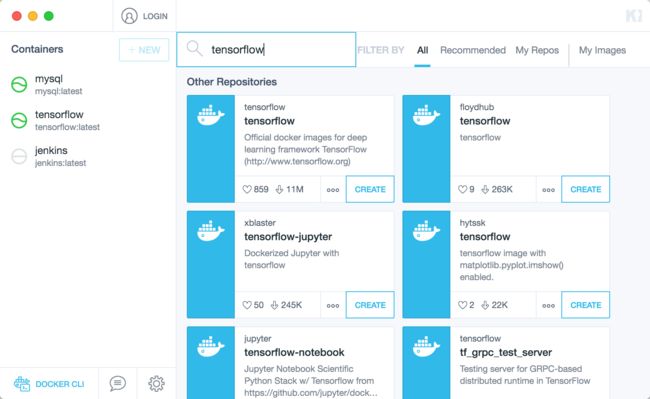
安装完毕后,点击
START即可启动实例,命令行中便会显示一个网址

需要注意的是,这个端口号是Docker实例Linux系统的端口号,必须改成映射本地电脑的端口号。
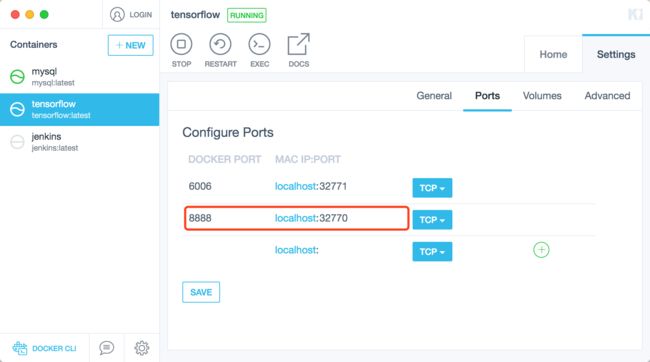
那么我的Tensorflow控制台的访问地址为:
http://localhost:32770/?token=fc9e43daca92166cf756f84695e71d300f26df757207ad03
控制台
输入网址就可以访问Tensorflow的web控制台了,我们编写的代码就可以在控制台上执行,当然也可以直接点击Docker上的EXEC,通过命令行访问
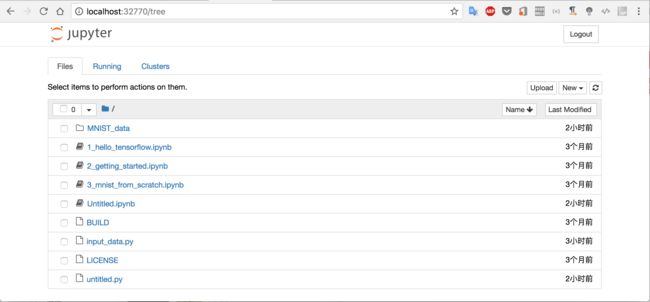
命令行

HelloWorld实验
通过Web控制台,点击New-Python2
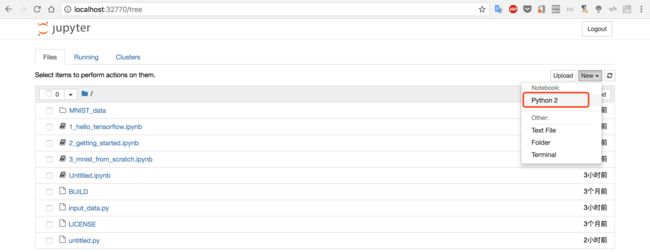
输入Python代码,点击
Run,那么HelloWorld就完毕啦
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print sess.run(hello)
a = tf.constant(10.)
b = tf.constant(32.)
print sess.run(a+b)
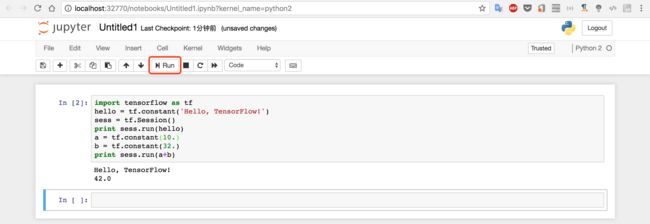
至于代码什么意思,就自己体会吧,我也没有看出这个HelloWorld有多个的意义,起码表明你已经走出HelloWorld这一步啦。[笑哭表情]
MNIST机器学习(图片数字识别实验)
MNIST的全称是Mixed National Institute of Standards and Technology database,是一系列带标记的数字图片。该实验其实就是识别图片中的数字,是机器学习最经典的案例之一。
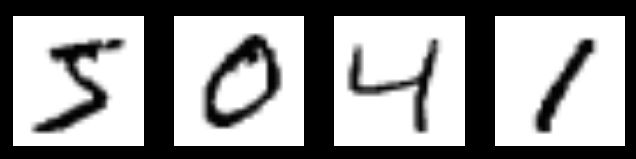
这个实验就是需要把上述的图片分别识别出
5,
0,
4,
1。
创建input_data.py文件
创建input_data.py文件,复制以下代码到该文件夹,也可以先在电脑创建文件然后通过控制台上传
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tensorflow.python.platform
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
def maybe_download(filename, work_directory):
"""Download the data from Yann's website, unless it's already here."""
if not os.path.exists(work_directory):
os.mkdir(work_directory)
filepath = os.path.join(work_directory, filename)
if not os.path.exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
return filepath
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def extract_images(filename):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
def dense_to_one_hot(labels_dense, num_classes=10):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
def extract_labels(filename, one_hot=False):
"""Extract the labels into a 1D uint8 numpy array [index]."""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels)
return labels
class DataSet(object):
def __init__(self, images, labels, fake_data=False, one_hot=False,
dtype=tf.float32):
"""Construct a DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`.
"""
dtype = tf.as_dtype(dtype).base_dtype
if dtype not in (tf.uint8, tf.float32):
raise TypeError('Invalid image dtype %r, expected uint8 or float32' %
dtype)
if fake_data:
self._num_examples = 10000
self.one_hot = one_hot
else:
assert images.shape[0] == labels.shape[0], (
'images.shape: %s labels.shape: %s' % (images.shape,
labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2])
if dtype == tf.float32:
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1] * 784
if self.one_hot:
fake_label = [1] + [0] * 9
else:
fake_label = 0
return [fake_image for _ in xrange(batch_size)], [
fake_label for _ in xrange(batch_size)]
start = self._index_in_epoch
self._index_in_epoch += batch_size
if self._index_in_epoch > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Shuffle the data
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self._images[perm]
self._labels = self._labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size
assert batch_size <= self._num_examples
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def read_data_sets(train_dir, fake_data=False, one_hot=False, dtype=tf.float32):
class DataSets(object):
pass
data_sets = DataSets()
if fake_data:
def fake():
return DataSet([], [], fake_data=True, one_hot=one_hot, dtype=dtype)
data_sets.train = fake()
data_sets.validation = fake()
data_sets.test = fake()
return data_sets
TRAIN_IMAGES = 'train-images-idx3-ubyte.gz'
TRAIN_LABELS = 'train-labels-idx1-ubyte.gz'
TEST_IMAGES = 't10k-images-idx3-ubyte.gz'
TEST_LABELS = 't10k-labels-idx1-ubyte.gz'
VALIDATION_SIZE = 5000
local_file = maybe_download(TRAIN_IMAGES, train_dir)
train_images = extract_images(local_file)
local_file = maybe_download(TRAIN_LABELS, train_dir)
train_labels = extract_labels(local_file, one_hot=one_hot)
local_file = maybe_download(TEST_IMAGES, train_dir)
test_images = extract_images(local_file)
local_file = maybe_download(TEST_LABELS, train_dir)
test_labels = extract_labels(local_file, one_hot=one_hot)
validation_images = train_images[:VALIDATION_SIZE]
validation_labels = train_labels[:VALIDATION_SIZE]
train_images = train_images[VALIDATION_SIZE:]
train_labels = train_labels[VALIDATION_SIZE:]
data_sets.train = DataSet(train_images, train_labels, dtype=dtype)
data_sets.validation = DataSet(validation_images, validation_labels,
dtype=dtype)
data_sets.test = DataSet(test_images, test_labels, dtype=dtype)
return data_sets

运行代码
从上述的HelloWorld例子我们已经知道代码的运行方式,复制以下代码:
import tensorflow as tf
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder("float", [None, 784.])
W = tf.Variable(tf.zeros([784.,10.]))
b = tf.Variable(tf.zeros([10.]))
y = tf.nn.softmax(tf.matmul(x,W) + b)
y_ = tf.placeholder("float", [None,10.])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 检测我们的预测
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
结果
输入代码,点击运行,因为需要下载文件和执行代码,请稍等几十秒,就可以看到我们计算所学习到的模型在测试数据集上面的正确率:0.9158,
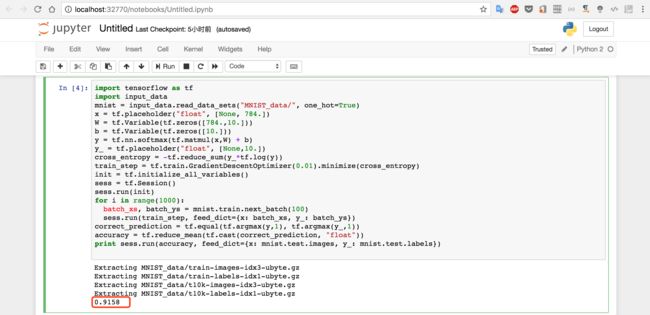
如果运行出现网络错误,请手动下载文件到对于文件夹
该实验的数据集,可以从http://yann.lecun.com/exdb/mnist下载,包含四个文件:
训练图片集合: train-images-idx3-ubyte.gz (包含 60,000 个图片样本)
训练标签集合: train-labels-idx1-ubyte.gz (包含 60,000 个数字标签)
测试图片集合: t10k-images-idx3-ubyte.gz (包含 10,000 个图片样本)
测试标签集合: t10k-labels-idx1-ubyte.gz (包含 10,000 个数字标签)
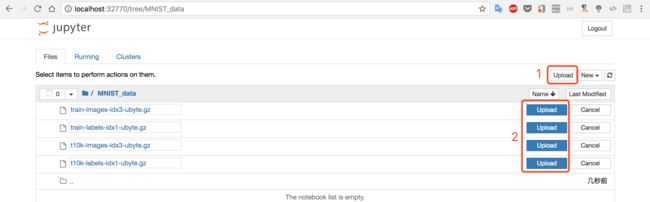
控制台先创建文件夹MNIST_data,然后把四个文件上传到MNIST_data文件夹
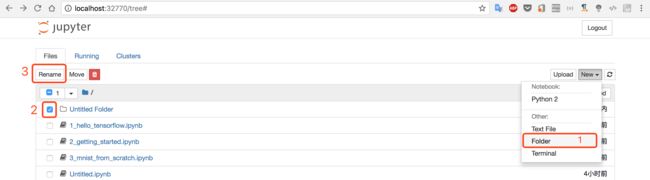
点击【1】选择四个文件,然后必须点击【2】的
Upload才是真正的上传。
总结
上面仅仅是我个人的学习的过程,没有太多原理的解析,后续会有更多相关的文章。
《机器学习Tensorflow笔记2:超详细剖析MNIST实验》