正则表达式(regular expression)用于指定字符串的模式,你可以在任何需要定位匹配某种特定模式的字符串的情况下使用正则表达式。


- 大部分字符都可以与它们自身匹配
- .符号可以匹配任何字符(有可能不包括行终止符,这取决于标志的设置)。
- 使用 \ 作为转义字符,例如,\. 匹配句号而 \\ 匹配反斜线。
- ^ 和 $ 分别匹配一行的开头和结尾。
- 如果 X 和 Y 是正则表达式,那么 XY 表示“任何 X 的匹配后面跟随 Y 的匹配”,X | Y 表示“任何 X 或 Y 的匹配”。
- 你可以将量词运用到表达式 X:X+(1 个或多个)、X* (0 个或多个)与 X ?(0 个或 1 个)。
- 默认情况下,量词要匹配能够使整个匹配成功的最大可能的重复次数。你可以修改这种行为,方法是使用后缀 ?(使用勉强或吝啬匹配,也就是匹配最小的重复次数)或使用后缀 +(使用占有或贪婪匹配,也就是即使让整个匹配失败,也要匹配最大的重复次数)。
例如,字符串 cab 匹配 [a-z]*ab,但是不匹配 [a-z]*+ab。在第一种情况中,表达式 [a-z]* 只匹配字符 c,使得字符 ab 匹配该模式的剩余部分;但是贪婪版本[a-z]*+ 将匹配字符 cab,模式的剩余部分将无法匹配。 - 我们使用群组来定义子表达式,其中群组用括号 () 括起来。例如,([+-]?)([0-9]+)。然后你可以询问模式匹配器,让其返回每个组的匹配,或者用 \n 来引用某个群组,其中 n 是群组号(从 \1 开始)。
- 捕获组可以通过从左到右计算其开括号来编号。
例如,下面是一个有些复杂但是却可能很有用的正则表达式,它描述了十进制和十六进制整数:
[+-]?\d+|0[Xx][0-9A-Fa-f]+
遗憾的是,在使用正则表达式的各种程序和类库之间,表达式语法并未完全标准化。尽管在基本结构上达成了一致,但是它们在细节上仍旧存在着许多令人抓狂的差异。Java 正则表达式类使用的语法与 Perl 语言使用的语法十分相似,但是并不完全一样。表 1-8 展示的是 Java语法中的所有结构。关于正则表达式语法的更多信息,可以求教于 Pattern 类的 API 文档和Jeffrey E. F. Friedl 的《Mastering Regular Expressions》(O’Reilly and Associates, 2006)。
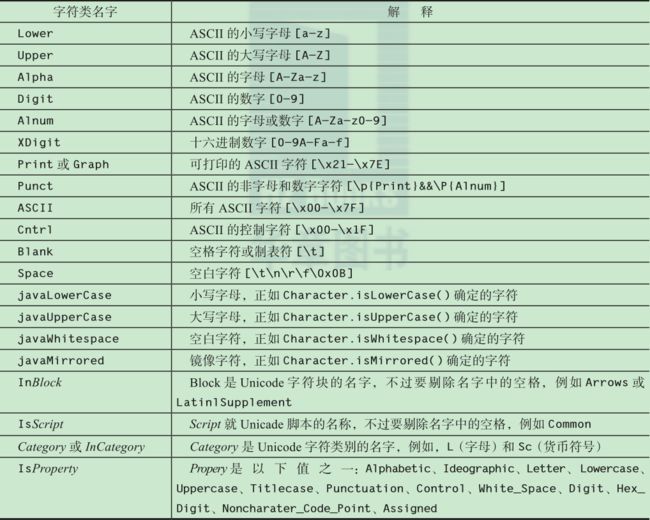
匹配
正则表达式的最简单用法就是测试某个特定的字符串是否与它匹配。
首先用表示正则表达式的字符串构建一个 Pattern 对象。然后从这个模式中获得一个 Matcher,并调用它的 matches 方法:
final String patternString = "1[3|5|7|8]\\d{9}"; //验证手机号合法性
final String input = "13800138000";
//标准方式
final Pattern pattern = Pattern.compile(patternString );
final Matcher matcher = pattern.matcher(input);
if(matcher.matches()){
//do something
}
//方式二 String类的方法
input.matches(patternString);
//方式三 Pattern的static方法
Pattern.matches(patternString, input);
这个匹配器的输入可以是任何实现了CharSequence 接口的类的对象,例如 String、StringBuilder 和 CharBuffer。在编译这个模式时,你可以设置一个或多个标志,例如:
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE + Pattern.UNICODE_CASE);
下面是所支持的六个标志:
- CASE_INSENSITIVE :匹配字符时忽略字母的大小写,默认情况下,这个标志只考虑
US ASCII 字符。 - UNICODE_CASE :当与 CASE_INSENSITIVE 组合时,用 Unicode 字母的大小写来匹配。
- MULTILINE :^ 和 $ 匹配行的开头和结尾,而不是整个输入的开头和结尾。
- UNIX_LINES :在多行模式中匹配 ^ 和 $ 时,只有 '\n' 被识别成行终止符。
- DOTALL :当使用这个标志时,. 符号匹配所有字符,包括行终止符。
- CANON_EQ :考虑 Unicode 字符规范的等价性,例如,u 后面跟随 ¨(分音符号)匹配 ü。
如果正则表达式包含群组,那么 Matcher 对象可以揭示群组的边界。下面的方法
int start(int groupIndex)
int end(int groupIndex)
将产生指定群组的开始索引和结束之后的索引。
你可以直接通过调用下面的方法抽取匹配的字符串:
String group(int groupIndex)
群组 0 是整个输入,而用于第一个实际群组的群组索引是 1。调用 groupCount 方法可以获得全部群组的数量。
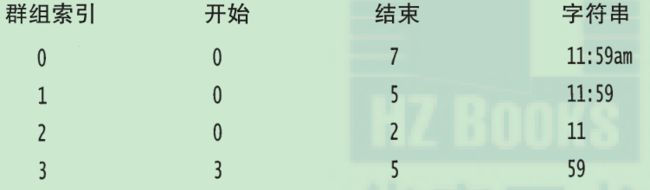
嵌套群组是按照前括号排序的,例如,假设我们有下面的模式
((1?[0-9]):([0-5][0-9]))[ap]m
和右边的输出 11:59am
那么,匹配器会报告下面的群组:
/**
* 该案例程序将打印出输入是否与模式相匹配。如果输入匹配模式,并且模式包含群组,
* 那么这个程序将用括号打印出群组边界
*/
private static void regexTest() {
final String patternString = "((1?[0-9]):([0-5][0-9]))[ap]m";
final String input = "11:59am";
final Pattern pattern = Pattern.compile(patternString);
final Matcher matcher = pattern.matcher(input);
if(matcher.matches()){
System.out.println("Match");
int g = matcher.groupCount();
if(g > 0){
for(int i=0; i查找(子字符串)
通常,你不希望用正则表达式来匹配全部输入,而只是想找出输入中一个或多个匹配的子字符串。这时可以使用 Matcher 类的 find 方法来查找匹配的下一个子字符串。
while(matcher.find()){
//方式一:group取得整个群组
String match = matcher.group();
//方式二: 取出下标后操作, 然后可进行更复杂的操作
int start = matcher.start();
int end = matcher.end();
match = input.substring(start, end);
}
/**
* 该程序清单对这种机制进行了应用,它定位一个 Web 页面上的所有超文本引用,并打印它们
* @throws IOException
*/
private static void hrefMatch() throws IOException{
final String urlString = "http://java.sun.com";
final URL url = new URL(urlString);
final BufferedReader bf = new BufferedReader(new InputStreamReader(url.openStream()));
//read contents into string builder
final StringBuilder input = new StringBuilder();
String line;
while((line = bf.readLine())!=null){
input.append(line);
}
//search for all occurrences of pattern
final String patternString = "]*)\\s*>";
final Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
final Matcher matcher = pattern.matcher(input);
while(matcher.find()){
int start = matcher.start();
int end = matcher.end();
String match = input.substring(start, end);
System.out.println(match);
}
}
Output:
替换
Matcher 类的 replaceAll 方法将正则表达式出现的所有地方都用替换字符串来替换。
例如,下面的指令将所有的数字序列都替换成 # 字符。
Matcher matcher = Pattern.compile("(\\d{3})\\d+").matcher("恭喜13800138000唐女士获得‘越策越开心’终极大奖");
String outputString = matcher.replaceAll("$1###");
替换字符串可以包含对模式中群组的引用:$n 表示替换成第 n 个群组,因此我们需要用$ 来表示在替换文本中包含一个 $ 字符。
如果字符串中包含 $ 和 \,但是又不希望它们被解释成群组的替换符,那么就可以调用atcher.replaceAll(Matcher.quoteReplacement(str))。
replaceFirst 方法将只替换模式的第一次出现。
切割
最后,Pattern 类有一个 split 方法,它可以用正则表达式来匹配边界,从而将输入分割成字符串数组。例如,下面的指令可以将输入分割成标记,其中分隔符是由可选的空白字符包围的标点符号。
Pattern pattern = Pattern.compile("\\s*\\p{Punct}\\s*");
String[] tokens = pattern.split("If I stayed all night, Just to peep in on you.");
System.out.println(tokens.length + ", " + Arrays.toString(tokens));
最后看看API
java.util.regex.Pattern 1.4
* static Pattern compile(String expression)
* static Pattern compile(String expression, int flags)
把正则表达式字符串编译到一个用于快速处理匹配的模式对象中。
参数:expression 正则表达式
flags CASE_INSENSITIVE、UNICODE_CASE、MULTILINE、UNIX_
LINES、DOTALL 和 CANON_EQ 标志中的一个
* Matcher matcher(CharSequence input)
返回一个 matcher 对象,你可以用它在输入中定位模式的匹配。
* String[] split(CharSequence input)
* String[] split(CharSequence input, int limit)
将输入分割成标记,其中模式指定了分隔符的形式。返回标记数组,分隔符并非标记的一部分。
参数:
input 要分割成标记的字符串
limit 所产生的字符串的最大数量。如果已经发现了 limit - 1 个
匹配的分隔符,那么返回的数组中的最后一项就包含所有剩余
未分割的输入。如果 limit<0,那么这个输入都被分割;如果
limit 为 0,那么坠尾的空字符串将不会置于返回的数组中
java.util.regex.Matcher 1.4
* boolean matches() 如果输入匹配模式,则返回 true。
* boolean lookingAt() 如果输入的开头匹配模式,则返回 true。
* boolean find()
* boolean find(int start) 尝试查找下一个匹配,如果找到了另一个匹配,则返回 true。
参数:start 开始查找的索引位置
* int start()
* int end() 返回当前匹配的开始索引和结尾之后的索引位置。
* String group() 返回当前的匹配。
* int groupCount() 返回输入模式中的群组数量。
* int start(int groupIndex)
* int end(int groupIndex) 返回当前匹配中给定群组的开始和结尾之后的位置。
参数:groupIndex 群组索引(从 1 开始),或者表示整个匹配的 0
* String group(int groupIndex) 返回匹配给定群组的字符串。
参数:groupIndex 群组索引(从 1 开始),或者表示整个匹配的 0
* String replaceAll(String replacement)
* String replaceFirst(String replacement)
返回从匹配器输入获得的通过将所有匹配或第一个匹配用替换字符串替换之后的字符串。
参数:replacement 替换字符串,它可以包含用 $n 表示的对群组的引用,这时需要用 \$ 来表示字符串中包含一个 $ 符号
* static String quoteReplacement(String str) 5.0 引用 str 中的所有 \ 和 $。
* Matcher reset()
* Matcher reset(CharSequence input) 复位匹配器的状态。第二个方法将使匹配器作用于另一个不同的输入。这两个方法都返回 this。
常见的正则表达式
### 全文匹配
腾讯QQ号
[1-9]\\d{4,9}
手机号
1[3|5|7|8]\\d{9}
邮箱号(粗略)
\\w+@\\w+(\\.\\w+)+
邮箱号(精确)
[a-zA-Z0-9_]+@[a-zA-Z0-9]+(\\.[a-zA-Z]+)+
### 获取字符串
获得叠字符, 例如`九天玄刹,化为神雷。煌煌天威,以剑引之`, 最终结果只有'煌煌'符合要求
(.)\\1+
本文属自己的心路历程, 供人参考。 绝大多数内容出自Java核心技术(卷2):高级特性(第9版)