统计学包括描述性统计和推论统计。
描述性统计的含义——"A descriptive statistic is a summary statistic that quantitatively describes or summarizes features of a collection of information."
中文翻译:描述性统计是一种汇总统计,用于定量描述或总结信息集合的特征。
推论统计:根据数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体。
本文主要介绍描述性统计,描述性统计又分为集中趋势和离散趋势。
一、集中趋势(Measures of central tendency)
能够对总体的某一特征具有代表性,表明所研究的对象在一定时间、空间条件下的共同性质和一般水平。
1. 众数(Mode)
用于定性的数据,表示一组数据中出现频次最高的数。
优点:不受极端值影响;当数据具有明显的集中趋势时,代表性好;
缺点:缺乏唯一性。
2. 分位数(Quantile)
亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等。
2.1 中位数(Median)
用于定量的数据,表示数值大小位于中间(奇偶总量处理不同)的值。
优点:不受极端值影响;缺点:缺乏敏感性。

2.2 四分位数
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称中位数,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距。
3. 平均数(Mean)
3.1 算术平均数:
优点:充分利用所有数据,适用性强;缺点:易受极值影响。
3.2 加权平均数:根据权重比例来求平均值
3.3 几何平均数

python实现:
import numpy as np
import pandas as pd
from scipy.stats import mode
data=[1,2,2,3,2,4]
a=np.mean(data)
b=np.median(data)
print('均值:%s' %a)
print('中位数:%s' %b)
#众数 法一
c=mode(data)
print('众数为{},出现了{}次'.format(c[0][0],c[1][0]))
#众数 法二 (只适用于非负数据集)
counts = np.bincount(data) #返回一个长度为data最大值+1的数组,统计data升序排列后对应索引的频数
np.argmax(counts) #返回众数
#分位数 法一 (np.percentile)
q1=np.percentile(data,25) #四分位
q2=np.percentile(data,95) #95%位数
#分位数 法二 (df.quantile)
df=pd.Series(data)
df.quantile(.25)
二、离散趋势(Measures of Dispersion)
1. 极差
一组数值型数据中最大值和最小值之差,max(x)-min(x),反映了数值样本的数据范围。
2. 方差和标准差
方差用于衡量数据的分散程度,常见的有总体方差和样本方差,计算方法类似。标准差为方差的平方根。
3. 平均差
是数据组中各数据值与其算术平均数离差绝对值的算术平均数。

4. 分位差
其数值越小表明数据越集中,数值越大表明数据越离散。常用的四分位差为:四分位差=(第三个四分位数-第一个四分位数)/2
5. 异众比率
异众比率越大,说明非众数组的频数占总频数的比重越大,众数的代表性就越差;异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。
6. 离散系数
离散系数又称变异系数,CV(Coefficient of Variance)表示。CV(Coefficient of Variance):标准差与均值的比值。离散系数越小,数据的离散程度就越小。
python实现:
import numpy as np
data=[1,2,2,3,2,4]
print('极差:{}'.format(np.ptp(data)))
print('方差:%s' % np.var(data) )
print('标准差:%s'% np.std(data) )
#平均差
a=np.mean(data)
print(np.sum(abs(data-a))/len(data))
#四分位差
print('四分位差',np.percentile(data,75)-np.percentile(data,25)) #0.75
#离散系数
print(np.std(data)/a)
三、分布形态
1. 偏态系数(Skewness)
偏态系数又称偏差系数(deviation coefficient),偏态系数以平均值与中位数之差对标准差之比率来衡量偏斜的程度,用SK表示偏斜系数:偏态系数小于0,因为平均数在众数之左,是一种左偏的分布,又称为负偏。偏态系数大于0,因为均值在众数之右,是一种右偏的分布,又称为正偏。
偏态系数是根据众数、中位数与均值各自的性质,通过比较众数或中位数与均值来衡量偏斜度的。
| 数据状态 | 描述 | 图示 |
|---|---|---|
| mean>median>mode | 正偏态、右偏态 |
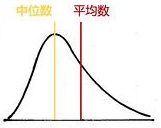
|
mean| 负偏态、左偏态 |
|

|
| mode=median=mean | 对称分布 |

|
2. 峰态系数(Kurtosis)
峰度系数是用来反映频数分布曲线顶端尖峭或扁平程度的指标,用于衡量离群数据离群度,峰度系数越大,说明该数据集中的极端值越多。在正态分布情况下,峰度系数值是3。>3的峰度系数说明观察量更集中,有比正态分布更短的尾部;<3的峰度系数说明观测量不那么集中,有比正态分布更长的尾部,类似于矩形的均匀分布。峰度系数的标准误用来判断分布的正态性。峰度系数与其标准误的比值用来检验正态性。如果该比值绝对值大于2,将拒绝正态性。
from scipy import stats
print('偏度:',stats.skew(data))
print('峰度:',stats.kurtosis(data))