CUDA编程(六): 利用好shared memory
CUDA编程(五): 并行规约优化
CUDA编程(四): CPU与GPU的矩阵乘法对比
CUDA编程(三): GPU架构了解一下!
CUDA编程(二): Ubuntu下的CUDA10.x环境搭建
CUDA编程(一): 老黄和他的核弹们
目录
- 前言
- CPU矩阵转置
- GPU实现
- 简单移植
- 单block
- tile
- 利用率计算
- shared memory
- 最后
前言
之前在CUDA编程(四): CPU与GPU的矩阵乘法对比对比过CPU和GPU, 差距非常大. 这一次来看看GPU自身的优化, 主要是shared memory的用法.
CPU矩阵转置
矩阵转置不是什么复杂的事情. 用CPU实现是很简单的:
#include
#include
#include
#define LOG_
#define N 1024
/* 转置 */
void transposeCPU( float in[], float out[] )
{
for ( int j = 0; j < N; j++ )
{
for ( int i = 0; i < N; i++ )
{
out[j * N + i] = in[i * N + j];
}
}
}
/* 打印矩阵 */
void logM( float m[] )
{
for ( int i = 0; i < N; i++ )
{
for ( int j = 0; j < N; j++ )
{
printf( "%.1f ", m[i * N + j] );
}
printf( "\n" );
}
}
int main()
{
int size = N * N * sizeof(float);
float *in = (float *) malloc( size );
float *out = (float *) malloc( size );
/* 矩阵赋值 */
for ( int i = 0; i < N; ++i )
{
for ( int j = 0; j < N; ++j )
{
in[i * N + j] = i * N + j;
}
}
struct timeval start, end;
double timeuse;
int sum = 0;
gettimeofday( &start, NULL );
transposeCPU( in, out );
gettimeofday( &end, NULL );
timeuse = end.tv_sec - start.tv_sec + (end.tv_usec - start.tv_usec) / 1000000.0;
printf( "Use Time: %fs\n", timeuse );
#ifdef LOG
logM( in );
printf( "\n" );
logM( out );
#endif
free( in );
free( out );
return(0);
}
GPU实现
简单移植
如果什么都不考虑, 只是把代码移植到GPU:
#include
#include
#include
#define N 1024
#define LOG_
/* 转置 */
__global__ void transposeSerial( float in[], float out[] )
{
for ( int j = 0; j < N; j++ )
for ( int i = 0; i < N; i++ )
out[j * N + i] = in[i * N + j];
}
/* 打印矩阵 */
void logM( float m[] ){...}
int main()
{
int size = N * N * sizeof(float);
float *in, *out;
cudaMallocManaged( &in, size );
cudaMallocManaged( &out, size );
for ( int i = 0; i < N; ++i )
for ( int j = 0; j < N; ++j )
in[i * N + j] = i * N + j;
struct timeval start, end;
double timeuse;
gettimeofday( &start, NULL );
transposeSerial << < 1, 1 >> > (in, out);
cudaDeviceSynchronize();
gettimeofday( &end, NULL );
timeuse = end.tv_sec - start.tv_sec + (end.tv_usec - start.tv_usec) / 1000000.0;
printf( "Use Time: %fs\n", timeuse );
#ifdef LOG
logM( in );
printf( "\n" );
logM( out );
#endif
cudaFree( in );
cudaFree( out );
}
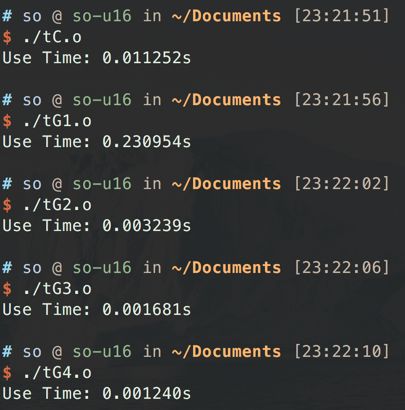
不用想, 这里肯定是还不如单线程的CPU的, 真的是完完全全的资源浪费. 实测下来, 耗时是CPU的20多倍, 大写的丢人.
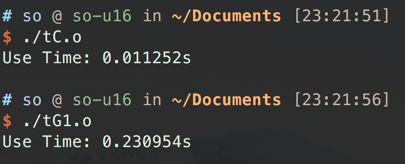
单block
单block最多可以开1024线程, 这里就开1024线程跑下.
/* 转置 */
__global__ void transposeParallelPerRow( float in[], float out[] )
{
int i = threadIdx.x;
for ( int j = 0; j < N; j++ )
out[j * N + i] = in[i * N + j];
}
int main()
{
...
transposeParallelPerRow << < 1, N >> > (in, out);
...
}
效率一下就提升了, 耗时大幅下降.
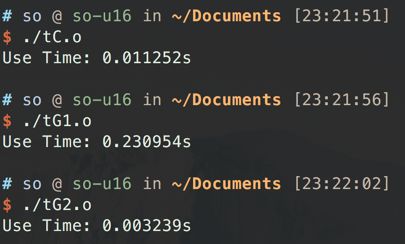
tile
但是的话, 如果可以利用多个block, 把矩阵切成更多的tile, 效率还会进一步提升.
/* 转置 */
__global__ void transposeParallelPerElement( float in[], float out[] )
{
int i = blockIdx.x * K + threadIdx.x;
/* column */
int j = blockIdx.y * K + threadIdx.y;
/* row */
out[j * N + i] = in[i * N + j];
}
int main()
{
...
dim3 blocks( N / K, N / K );
dim3 threads( K, K );
...
transposeParallelPerElement << < blocks, threads >> > (in, out);
...
}
这些都是GPU的常规操作, 但其实利用率依旧是有限的.
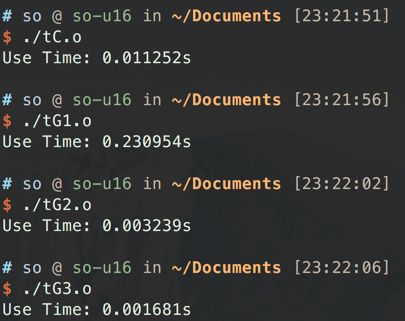
利用率计算
利用率是可以粗略计算的, 比方说, 这里的Memory Clock rate和Memory Bus Width是900Mhz和128-bit, 所以峰值就是14.4GB/s.
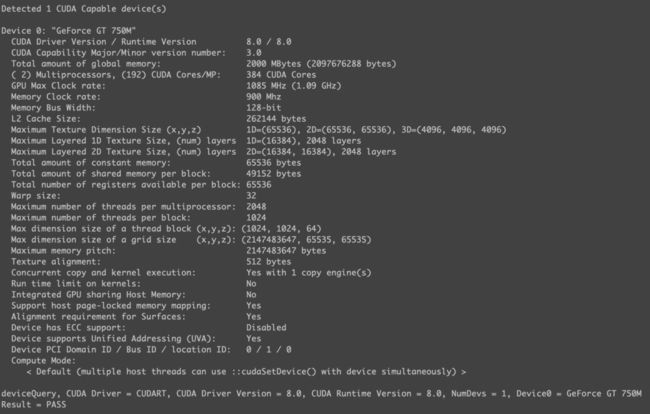
之前的最短耗时是0.001681s. 数据量是1024*1024*4(Byte)*2(读写). 所以是4.65GB/s. 利用率就是32%. 如果40%算及格, 这个利用率还是不及格的.
shared memory
那该如何提升呢? 问题在于读数据的时候是连着读的, 一个warp读32个数据, 可以同步操作, 但是写的时候就是散开来写的, 有一个很大的步长. 这就导致了效率下降. 所以需要借助shared memory, 由他转置数据, 这样, 写入的时候也是连续高效的了.
/* 转置 */
__global__ void transposeParallelPerElementTiled( float in[], float out[] )
{
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K];
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y) * N];
__syncthreads();
out[(out_corner_i + x) + (out_corner_j + y) * N] = tile[x][y];
}
int main()
{
...
dim3 blocks( N / K, N / K );
dim3 threads( K, K );
struct timeval start, end;
double timeuse;
gettimeofday( &start, NULL );
transposeParallelPerElementTiled << < blocks, threads >> > (in, out);
...
}
这样利用率就来到了44%, 及格了.
所以这就是依据架构来设计算法, 回顾一下架构图:

最后
但是44%也就是达到了及格线, 也就是说, 还有更深层次的优化工作需要做. 这些内容也就放在后续文章中了, 有意见或者建议评论区见~