上一节提到了解码需要声学模型(final.mdl)和语言模型(HCLG.fst),这节就来看一看这个model文件里是什么东西。
Ref
Dan's DNN implementation http://kaldi-asr.org/doc/dnn2.html
Kaldi Lecture 4
Decoders used in the Kaldi toolkit http://kaldi-asr.org/doc/decoders.html
kaldi yesno example http://blog.csdn.net/shichaog/article/details/73264152?locationNum=9&fps=1
单音素GMM学习笔记 http://www.itdadao.com/articles/c15a1230377p0.html
model文件是什么?
Kaldi官网上给出的OnlineDecoder Demo用到的是online2-wav-nnet2-latgen-faster这个命令,于是查看了一下它的源码,关于这个Model的部分如下
//nnet2_rxfilename便是.mdl文件
TransitionModel trans_model;
nnet2::AmNnet nnet;
{
bool binary;
Input ki(nnet2_rxfilename, &binary);
//trans_model和nnet声学模型都在final.mdl里面
trans_model.Read(ki.Stream(), binary);
nnet.Read(ki.Stream(), binary);
}
由以上代码便可知道model文件包含了HMM的部分拓扑结构(即TransitionModel,更完整的拓扑结构在HCLG.fst中)以及各个特征对应的概率(即声学模型AM),通过声学模型加上TransitionModel就能知道这个特征属于HMM中的哪个状态,这个完整的HMM结构就是HCLG.fst。
HCLG.fst文件是什么?
音素由状态状态组成,单词由音素组成,句子由单词组成,只要这要一步步还原就能将上面过程得到的状态还原为文字。HCLG.fst便对应这个过程的转化。
- H: HMM,将状态还原为音素。实际上输入Kaldi这个HCLG.fst的并不是状态,而是一串由TransitionModel产生出来的
transition-id,不过理解成状态并无大碍。 - L: Lexicon,即一个单词是怎么读的,将音素还原为单词。可以理解为一个单词的音标是怎样的。
- G: Grammar,即单词是如何组成句子的。将单词合理地组成句子。
- C: Context-dependency,由它来构建音素之间的上下文相关性,即形成
triphone。这个过程是实时构建的(原文为on-the-fly,大概意思是这个C是在内存里动态构建的?)
NNet2 Model文件分析
感觉DNN的Model文件比GMM的容易懂一些
Ref1中提到,这个Model输入的是一个窗口内的特征串,输出维数对应决策树的叶节点数量,这样就能得出这个特征串最可能是HMM中的哪个pdf了。先来使用nnet-am-info命令查看一下librispeech经过nnet2训练得到的model里面的声学模型
num-components 17
num-updatable-components 5
left-context 7
right-context 7
input-dim 140
output-dim 5816
parameter-dim 10351000
component 0 : SpliceComponent, input-dim=140, output-dim=700, context=-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 , const_component_dim=100
component 1 : FixedAffineComponent, input-dim=700, output-dim=700, linear-params-stddev=0.00203155, bias-params-stddev=0.0310742
component 2 : AffineComponentPreconditionedOnline, input-dim=700, output-dim=3500, linear-params-stddev=0.986785, bias-params-stddev=4.42767, learning-rate=0.001, rank-in=20, rank-out=80, num_samples_history=2000, update_period=4, alpha=4, max-change-per-sample=0.075
component 3 : PnormComponent, input-dim = 3500, output-dim = 350, p = 2
component 4 : NormalizeComponent, input-dim=350, output-dim=350
component 5 : AffineComponentPreconditionedOnline, input-dim=350, output-dim=3500, linear-params-stddev=1.0001, bias-params-stddev=0.983017, learning-rate=0.001, rank-in=20, rank-out=80, num_samples_history=2000, update_period=4, alpha=4, max-change-per-sample=0.075
component 6 : PnormComponent, input-dim = 3500, output-dim = 350, p = 2
component 7 : NormalizeComponent, input-dim=350, output-dim=350
component 8 : AffineComponentPreconditionedOnline, input-dim=350, output-dim=3500, linear-params-stddev=1.00021, bias-params-stddev=0.944995, learning-rate=0.001, rank-in=20, rank-out=80, num_samples_history=2000, update_period=4, alpha=4, max-change-per-sample=0.075
component 9 : PnormComponent, input-dim = 3500, output-dim = 350, p = 2
component 10 : NormalizeComponent, input-dim=350, output-dim=350
component 11 : AffineComponentPreconditionedOnline, input-dim=350, output-dim=3500, linear-params-stddev=1.0002, bias-params-stddev=0.943781, learning-rate=0.001, rank-in=20, rank-out=80, num_samples_history=2000, update_period=4, alpha=4, max-change-per-sample=0.075
component 12 : PnormComponent, input-dim = 3500, output-dim = 350, p = 2
component 13 : NormalizeComponent, input-dim=350, output-dim=350
component 14 : AffineComponentPreconditionedOnline, input-dim=350, output-dim=12000, linear-params-stddev=0.607722, bias-params-stddev=0.874339, learning-rate=0.001, rank-in=20, rank-out=80, num_samples_history=2000, update_period=4, alpha=4, max-change-per-sample=0.075
component 15 : SoftmaxComponent, input-dim=12000, output-dim=12000
component 16 : SumGroupComponent, input-dim=12000, output-dim=5816
prior dimension: 5816, prior sum: 1, prior min: 2.69233e-06
LOG (nnet-am-info[5.3.31~1-4e3c1]:main():nnet-am-info.cc:76) Printed info about final.mdl
可以看到librispeech语料库训练得到的层数为16层,Ref1中提到的RM数据集的mdl层数则是10层,估计大部分时间都用在了这个网络的计算中。影响实时性的元凶找到了,重新训练一个小一点的网络结构吧(说的可真轻松呢)。
GMM Model文件分析
Ref4中提到的有些概念可能会让人误解,还有些数据感觉有问题,这里仅以我理解的方式分析一下。
切换到yesno/s5/exp/mono0a目录下,用~/kaldi-bak/src/gmmbin/gmm-copy --binary=false 0.mdl -命令将二进制的mdl文件显示在标准输出中。
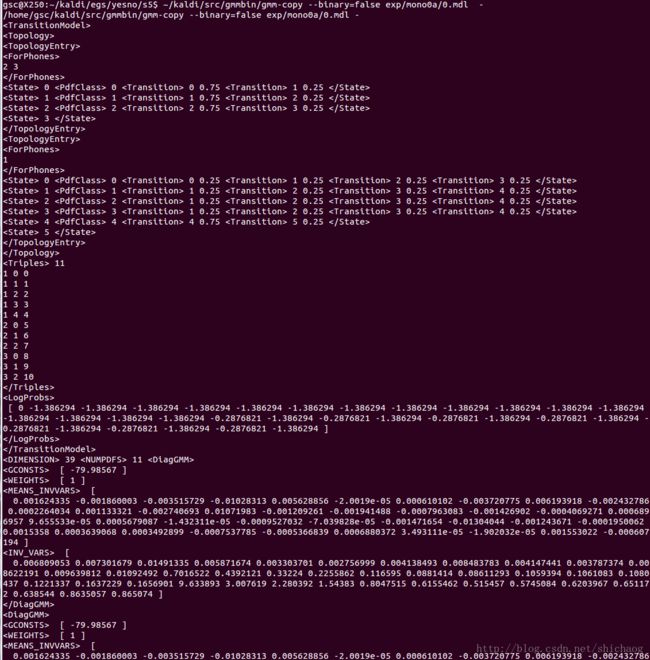
这个包含的就不必多说了,就是整个HMM的结构和初始参数(0.mdl和40.mdl这一部分的参数均相同,可见转移概率等应该是储存在HCLG.fst文件中的)了
共有11个,对应11个状态双圆圈,如下图

如Kaldi官网HMM部分所说,
Each possible triple of (phone, hmm-state, pdf) maps to a unique transition-state.
[ 0 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 -0.2876821 -1.386294 ]
这里共有1(进入HMM的初始概率为1,log后为0)+30个值(不知道Ref4的作者是不是打错了)

也就是说这个LogProbs是和transition-id对应起来的,描述了转移概率。
39 11
输入的MFCC特征为39维,需要求11个状态的概率密度函数,后续的一些值就是记录这11个状态具体的GMM描述的概率密度函数啦。一个GMM原原本本的参数需要以下参数:分量权重weights_,均值means_,方差vars_,不过为了方便计算,在里面记录了每一分量多维高斯分布里的常量部分取log后的数值gconsts_,方差每一元素求倒数后的inv_vars_、均值乘以inv_vars_后的means_invvars_。
RM Model文件分析
从官网上下载各个阶段训练出的model文件,http://kaldi-asr.org/downloads/build/4/trunk/egs/rm/s5/exp/,并转为文本格式,~/kaldi-bak/src/gmmbin/gmm-copy --binary=false 0.mdl 0_text.mdl,然后就可以像上面那样分析一下声学模型是如何构成的,这里只比较一下Monophone单音素和Triphone三音素之间的差异。
Monophone阶段
- 1~5为SIL,含5个状态
- 6~193为发音音素,含3个状态
- 共有5*5+(194-6)*3=589个
transition state - 得益于决策树的聚类, PDF数量减少了一些,为146
Triphone 1阶段
- 1~5为SIL,含5个状态
-
6~193为发音音素,含3个状态
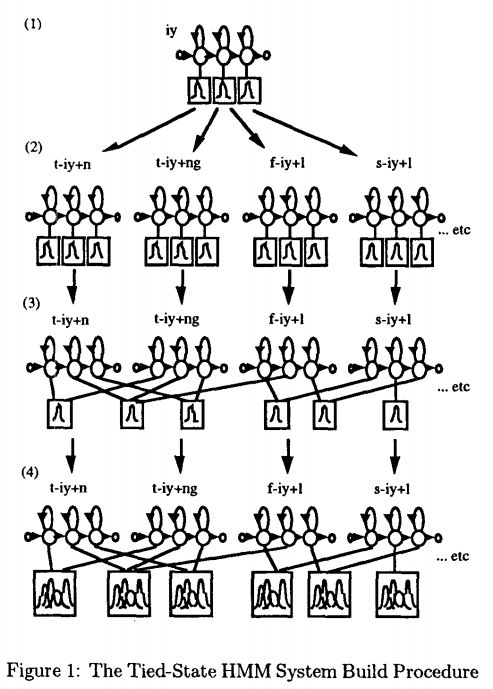 Ref:Tree-Based State Tying for High Acoustic Accuracy Modelling
Ref:Tree-Based State Tying for High Acoustic Accuracy Modelling - 单音素内部三个状态是排列好的,所以之前的计算是5*5+(194-6)*3=589个Transition;
现在三音素的三个状态可以从相关的别的音素那里去组合了,所以transition state增加到了5662 - PDF 1435
关于实时性
观察一下解码等命令所用的时间,
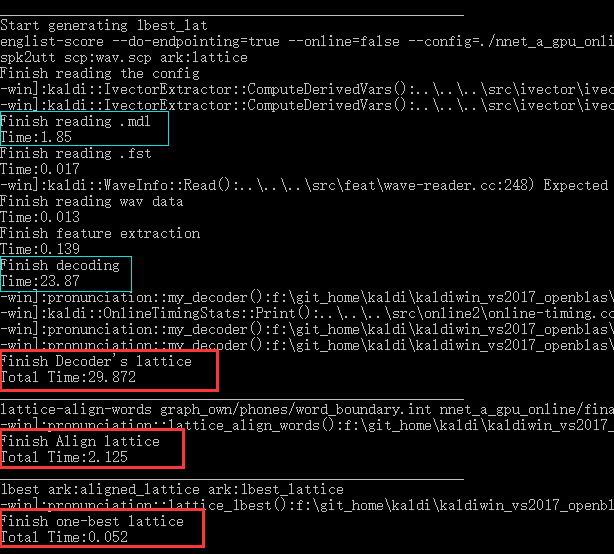
IO时间
可以注意到将
final.mdl这个接近40MB的文件给读入内存还是需要一定时间的,而且在
Decoder's lattice和
Align lattice里面都会用到它,因此考虑在程序启动的时候就将它读入内存,后续解码的时候直接使用。因此假如想移植到安卓,通过JNI操作的话就需要全局变量了。
解码时间
也就是第二个蓝框里的时间,这部分耗时是最长的,目前的想法就是分析这个解码运算集中在哪里,进行优化来提高实时性了。这也是为什么要分析model文件的原因。
分析一下Nnet2方式和GMM方式计算速度到底谁更快以及怎么优化: Nnet2输入特征找到最可能对应的pdf-id,在这个过程中计算了分别属于所有pdf-id的概率; GMM则可计算指定个数的pdf-id,找一个概率最大的出来。但是GMM是只找了该特征属于部分pdf-id的概率,还是找了所有的呢?Ref3中提到的
The function LogLikelihood() returns the log-likelihood for this frame and index; the index would normally be the (one-based) transition-id, see Integer identifiers used by TransitionModel. The frame is a zero-based quantity. The most normal DecodableInterface object will just look up the appropriate feature vector (using the index "frame"), work out the pdf-id corresponding to that transition-id, and return the corresponding acoustic log-likelihood.
似乎说明是找部分pdf-id去进行计算的,但是实际运行过程中发现GMM和NNET2解码时间相差并不大。
总结
model文件包含声学模型和transition model用于找出特征对应的状态的位置,再将状态扔到HCLG.fst中构建出所有状态组合成的句子。除开GMM和NNET2之外,还有NNET3模型没有分析,留到后面再说了。另外HCLG.fst是如何构建的?下一篇文章见。