reference:[非常好的两本书。再加上libsvm的源码与调参的论文。]
[1]http://files2.syncfusion.com/Downloads/Ebooks/support_vector_machines_succinctly.pdf
[2]An Introduction to Support Vector Machines and Other Kernel-based Learning Methods
[3]https://pan.baidu.com/share/link?shareid=262520779&uk=1378138793干货
首先,SVM是解决supervised learning 中classification问题。有两种情况,看是否linearly separable。线性不可分则引入kernel,想法为先做transformation到其他空间进而转为可分问题。
对于线性可分的监督分类问题,SVM的目标是什么呢? find the optimal separating hyperplane which maximizes the margin of the training data
为什么以最大化间隔为目标?因为it correctly classifies the training data and because it is the one which will generalize better with unseen data
这里的 间隔 指?关于间隔涉及到两种分类,一种分类为几何间隔与函数间隔;一种为软、硬间隔。几何间隔在二维则为点线距离,三维空间就是我们学习的点面距离。函数间隔二维中可以理解为几个点没有在线上,三维则为几个点没有在面上;或者结合几何间隔可理解为,是将几何间隔求解的分母去掉了,没有归一化(也因此SVM中不能选择以函数间隔衡量,否则maximizes是没有意义的)。关于软硬,是看噪声,There will never be any data point inside the margin. If data is noisy, we need soft margin classifier.
-
继上面的目标,假设该超平面的公式为W*X=0,这里会有疑惑:
- Why do we use the hyperplane equation WX instead of Y=ax+b? --> the vector W will always be normal to the hyperplane
-
澄清下要做的步骤:
- 1 数据集 2 选择两个超平面能够分类数据并在两平面间没有其他点
3 最大化超平面间隔
- 1 数据集 2 选择两个超平面能够分类数据并在两平面间没有其他点
-
将步骤整理成数学过程
设两个超平面, WX+b = -θ 和 WX+b = +θ。这里,为什么我们需要两个超平面?我们设想的是,假定最佳的超平面在这两个超平面的中间。我们求得两个超平面即可求得最佳分类超平面。
θ取值无关,直接设为1。 即得WX+b = -1 和 WX+b = +1。这里要想明白W与b到底是什么关系?b依赖还是独立于W?显然,是独立的,可以想象为,我们需要求得W与b两个变量,能够最大化间隔。
需要满足两个约束: 1. 任何>=1的为class 1 2.任何<=-1的为class -1 -->这个限制使在两平面间没有其他点
将两个约束写为一个式子即: y(wx+b)>=1
最大化间隔 ?对于这个问题,目前我们已知条件是两个。一个是两个平面 WX+b = -1 和 WX+b = +1。一个是有一个点x在平面 WX+b = -1 上。得:
w*(x + m*w/||w||)+b=1
化简得m = 2/||w||得到的公式意味着:如果||w||没有限制,那么m我们可以取得任意大的值。
-
现在自然就面临optimization problem。所有的点subject to y(wx+b)>=1, 在此条件下如何minimize ||w||?先引入理论1,该理论为两个条件,在两个条件满足的情况下,可以说我们得到了一个scalar function的local minimum。
 theorem 1 .jpg
theorem 1 .jpg -
f为从集合σ(其元素为vector)到实数集(其元素为值)的映射,且在x处 连续、可二阶导。这里涉及到两个的概念:
- gradient :a generalization of the usual concept of derivative of a function in one dimension to a function in several dimensions ( the gradient of a function is a vector containing each of its partial derivatives.)注意符号为 nabla,图中倒三角。
- scalar function:A scalar valued function is a function that takes one or more values but returns a single value. In our case f is a scalar valued function.
positive definite:
A symmetric matrix A is called positive definite if x.TAx>0 , for all n维的实数向量x。-
theorem 2中的四个条件是等价的。因此可以通过其他三种情况来判断是否为正定。这里选择主子式来判断Hessian正定,涉及到三个概念:
 theorem 2 .jpg
theorem 2 .jpg- Minors: 删除某行和某列的所有值再计算行列式。remove the ith line and the jth column
- Principal minors :删除的行、列号一致。remove the ith line and the jth column and i=j
- Leading principal minor :The leading principal minor of A of order k is the minor of order k obtained by deleting the last n−k rows and columns.(这里包含一个正三角符号,标注删除哪些行列)栗子看图Leading principal minor
 leading principal minor.jpg
leading principal minor.jpg
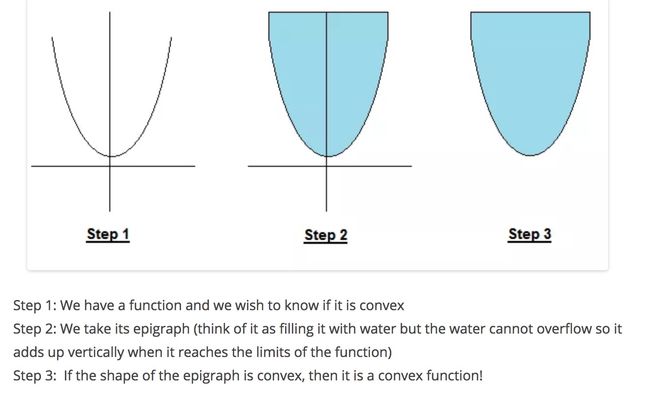
得到了local minimum,How can we find a global minimum?两步走, 1. Find all the local minima 2. Take the smallest one; it is the global minimum. 另一个思路是看我们的f是否是convex ,是then we are sure its local minimum is a global minimum.
Theorem: A local minimum of a convex function is a global minimum 这里又涉及到convex function, convex set的定义。-
What is a convex function? A function is convex if you can trace a line between two of its points without crossing the function line.
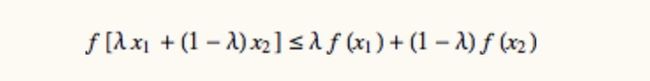 convex 0<λ<1.jpg
convex 0<λ<1.jpg
A function is convex if its epigraph (the set of points on or above the graph of the function) is a convex set. In Euclidean space, a convex set is the region such that, for every pair of points within the region, every point on the straight line segment that joins the pair of points is also within the region.
栗子看图convex set
 convex set.jpg
convex set.jpg- 同样根据Hessian判断是否convex,这里需要看是否是positive semidefinite,而semi有对应三个条件是与之等价。看 theorem 3
More generally, a continuous, twice differentiable function of several variables is convex on a convex set if and only if its Hessian matrix is positive semidefinite on the interior of the convex set.The difference here is that we need to check all the principal minors, not only the leading principal minors.
 theorem 3.jpg
theorem 3.jpg- 其中on the interior of the convex set是什么意思呢?定义:the domain of a convex function is a convex set,那么 a function is convex on a convex set意思就是在domain上是convex function,而interior只是意味着为两边开区间。
- 其他证明是convex function的方法
- 这里就谈convex function的optimization问题求解。涉及对偶概念,根据wiki,
Duality :duality means that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem (the duality principle). The solution to the dual problem provides a lower bound to the solution of the primal (minimization) problem.
给最小值以下限。lower bound中有一个值为infimum (即 greatest lower bound)。补充,相对而言
The same logic apply with the relation "greater than or equal" and we have the concept of upper-bound and supremum.
- 对偶,在求最小值时求对应的最大值,求出的最大值将是=<最小值,两者之差即为duality gap。对应来说,在求最大值时求对应最小值,求出的最小值将是>=最大值即upper bound。duality gap为正,我们称之weak duality holds,为0则为strong duality holds。
- 拉格朗日乘子 :
In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints.
 Lagrange_portrait.jpg
Lagrange_portrait.jpg-
如何将3D图在2D平面表示:Contour lines 两个要点:1. 线上的点z值不变,for each point on a line, the function returns the same value 2. 颜色扮演标识,the darker the area is, the smallest the value of the function is
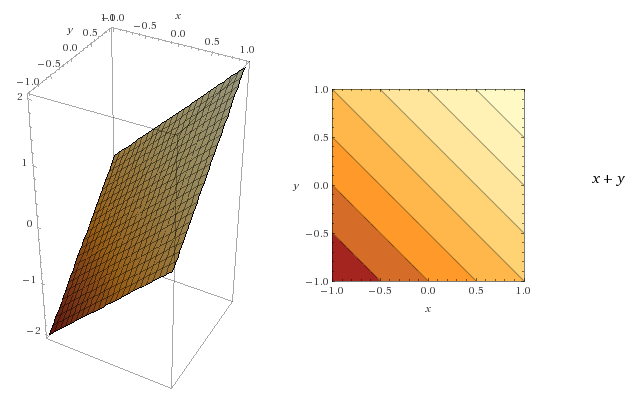 contours.png
contours.png -
那么梯度就可以用向量场进行可视化。箭头指向函数增长的方向。与Contour lines 图有什么关系呢?在Contour lines 图中,gradient vectors非常容易画出,1 垂直于Contour lines 2.指向增加的方向。
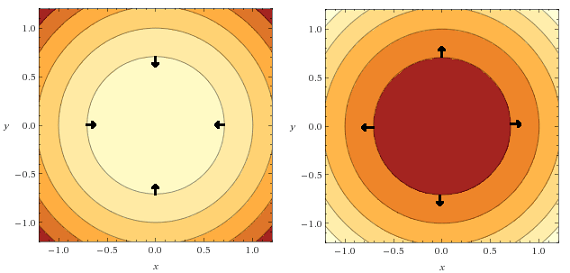 gradient_and_contour.png
gradient_and_contour.png -
将约束函数和优化目标函数以contour lines 画在一幅图中,并画出两者的gradient vector。可得到最优点。图中的优化目标函数为x2+y2, 约束函数为 y=1-x。
 function_and_constraint.png
function_and_constraint.png ▽f(x,y) = λ ▽g(x,y)
λ 这就是拉格朗日乘子。根据图中,当两个gradient vector平行时,我们得到最优解。无论是否同向。更无论是否等长。乘以λ 即意味着不必等长。即求▽L(x,y,λ )=0时的x,y。现在我们需要列出L并求解。- 由于我们需要求f(w)=1/2*||w||^2的最小值,将每个约束函数乘以的 λ需要取正数。
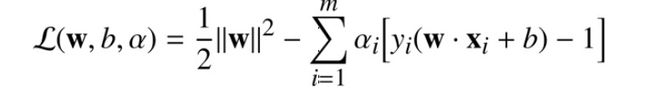 L.jpg
L.jpg -
又面临一个问题,求L(x,y,λ )=0, the problem can only be solved analytically when the number of examples is small (Tyson Smith, 2004 即只有当约束函数数量比较小的时候,λ 个数不多,我们才能用分析的方法求解). So we will once again rewrite the problem using the duality principle-->we need to minimize with respect to w and b, and to maximize with respect to a at the same time.我们在上一步需要最小化
 duality_after_L.jpg
duality_after_L.jpg 这里需要讲清楚三个问题。1. 拉格朗日是对约束函数是等式的情况,那么我们在这里是不等式约束的问题,也用拉格朗日乘子解决,需要满足什么条件吗?(KKT)2.之前说了,对偶问题有强与弱,只有当强时,gap才为0,我们才能将对偶问题的最大值作为原问题的最小值。那么,这里是否满足是strong duality holds? (强对偶 即下文Slater’s condition)3.或许你对为什么能够是对w b求min,对a求max还是留有疑问。(拉格朗日到对偶问题这两个之间的转化过程)
-
仍需要引入两个理论。1. duality principle 2.Slater’s condition 3.KKT
首先,L对w与b求偏导,令为0(这里两个等式),再将这两个等式带入到L中,消去了w、b,只剩下变量a,即得L(a)。于是将问题转化为 Wolfe dual Problem
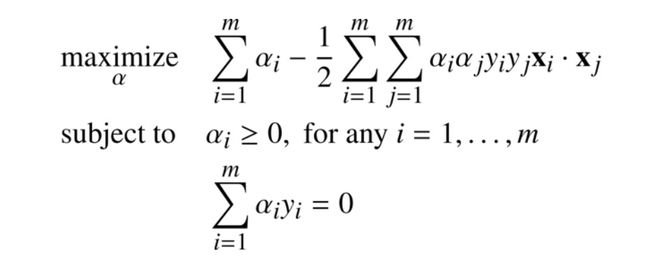 wolfe dual.jpg
wolfe dual.jpg -
慢着,这里又出现一个问题。
Traditionally the Wolfe dual Lagrangian problem is constrained by the gradients being equal to zero. In theory, we should add the constraints θL/θw=0 and θL/θb=0 . However, we only added the latter, because it is necessary for removing b from the function. However, we can solve the problem without the constraint θL/θw=0.
这里就会不明白为什么不需要加上θL/θw=0约束仍能够solve the problem?暂且保留疑问。
-
Karush-Kuhn-Tucker conditions :first-order necessary conditions for a solution of an optimization problem to be optimal
除了KKT还需要满足一些regularity conditions,其中之一为Slater’s condition。Because the primal problem we are trying to solve is a convex problem, the KKT conditions are also sufficient for the point to be primal and dual optimal, and there is zero duality gap.
这里说的,即只要为convex问题,KKT也满足,即可说得出的结果是原问题或对偶问题的最优解,因为Slater’s condition是一定满足了的,gap=0。对于SVM,如果结果满足KKT,那么即可说是最优解。(详细证明过程[2] ch5)
 KKT.jpg
KKT.jpg -
可见,1. stationary 即为偏导为0即为驻点,若无约束函数则直接gradient是0,有了约束则gradient of the Lagrangian为0。2. primal feasibility为原问题约束函数 3. dual feasibility 为我们对L求解时使用对偶理论时的约束函数 4.complementary slackness含义是,要么a=0,要么y(wx+b)-1=0.这里与Support vectors相关,
Support vectors are examples having a positive Lagrange multiplier. They are the ones for which the constraint y(wx+b)-1>=0 is active. (We say the constraint is active when y(wx+b)-1=0 )
这里,是否会疑惑为什么不能同时为0?为什么multiplier一定是正数?在KKT中,我们只选取支持向量,即将不等号约束改为等号约束,其他的点不考虑。
Solving the SVM problem is equivalent to finding a solution to the KKT conditions.” (Burges, 1988)
现在有了L(a),求导即可。得到了a。再根据偏导为0的公式回代得到w 。再根据prime problem中的约束函数y(wx+b)-1>=0,计算b
-
用QP solver来解对偶问题。用python CVXOPT包。将wolfe dual.jpg中我们需要求解的公式转化到下面CVXOPT支持的形式。这里引入了一个Gram matrix - The matrix of all possible inner products of X.
 CVXOPT.jpg
CVXOPT.jpg
 转化过程.jpg
转化过程.jpg
这个图里有问题,minimize部分最后一项需要q.T*a, 详见代码部分,需要q = cvxopt.matrix(-1 * np.ones(m))。
code部分:
import cvxopt.solvers
X, y = 这里获取到数据
m = X.shape[0] #data有多少
# Gram
K = np.array([np.dot(X[i], X[j]) for j in range(m) for i in range(m)]).reshape((m, m))
P = cvxopt.matrix(np.outer(y, y) * K)
q = cvxopt.matrix(-1 * np.ones(m))
# 等式约束
A = cvxopt.matrix(y, (1, m))
b = cvxopt.matrix(0.0)
# 不等式约束
G = cvxopt.matrix(np.diag(-1 * np.ones(m))) h = cvxopt.matrix(np.zeros(m))
# 求解
solution = cvxopt.solvers.qp(P, q, G, h, A, b)
# 拉格朗日乘子
multipliers = np.ravel(solution['x'])
# 支持向量
has_positive_multiplier = multipliers > 1e-7
sv_multipliers = multipliers[has_positive_multiplier]
support_vectors = X[has_positive_multiplier]
support_vectors_y = y[has_positive_multiplier]
#计算w,b
def compute_w(multipliers, X, y):
return np.sum(multipliers[i] * y[i] * X[i] for i in range(len(y)))
def compute_b(w, X, y):
return np.sum([y[i] - np.dot(w, X[i]) for i in range(len(X))])/len(X)
w = compute_w(multipliers, X, y)
w_from_sv = compute_w(sv_multipliers, support_vectors, support_vect
b = compute_b(w, support_vectors, support_vectors_y)
We saw that the original optimization problem can be rewritten using a Lagrangian function. Then, thanks to duality theory, we transformed the Lagrangian problem into the Wolfe dual problem. We eventually used the package CVXOPT to solve the Wolfe dual.
- 为什么需要将拉格朗日函数转化为对偶问题到wolfe dual?
这里还差对偶原则及Slater’s condition 概念。