前 言
所谓爬虫,简单来说就是通过网络请求获取内容并解析出结果的过程,当中以网页爬虫最为常见。然而随着Web应用的日益复杂化,各种Ajax和JS加持的Web页面对于爬虫来说,在请求内容这第一步就造成了不小难度。爬虫工程师们往往不得不苦于分析网页请求中各种不明意义的字段,开始一段心酸的JS探寻之旅。而此时,来自测试领域的一套自动化测试工具,却给爬虫工程师们带了新的曙光——她,就是Selenium。

关于Selenium
Selenium是一套Web应用的自动化测试框架,拥有完整的浏览器支持,通过模拟浏览器的真实操作实现Web应用测试,并且提供简单好用的录制/回放工具让使用者无需了解脚本语言就能写出可以执行的测试用例。
Selenium底层由各种web driver驱动,提供丰富的API接口。对Python/Java等语言的支持,再配合上headless的浏览器(如PhantomJS),注定会成为爬虫工程师手中的利器!
实践看亮点
准备
Python 2.7.12
python-selenium 3.0.0
Selenium Webdriver(本文因可视化展示所需,所以用到chromedriver,实际爬虫应用中,一般常用PhantomJS作为headless浏览器)
亮点
1、完整的Web支持
得益于Selenium的运行机制,因为实际启用了浏览器,所以能够对Web应用进行完整的支持。一句话:浏览器看到的样子就是爬虫可以获取到的内容,所以在用Selenium编写爬虫的过程中,爬虫开发者不用再纠结于网页请求的分析,只需关注于页面解析即可。
以某企业信息查询网站查询“星巴克”为例,抓包可知其实际查询请求如下:

如图可见该接口的请求cookie中带有一个神奇的token字段。令人比较遗憾的是,该token并非是来自于其它请求的返回,而是由JS生成。
通常情况下,需要找到生成该token的JS代码段,分析其输入输出,使用JS执行器或者将该部分JS的逻辑自行实现,以获得token。而使用Selenium编写爬虫,则不用关心这个部分,短短几行就可以完成一次页面查询。代码示例:
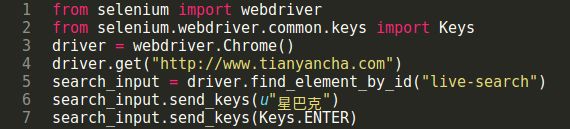
从查询结果页的URL来看,我们还能更进一步简化查询操作,甚至一句代码就能完成,如下:

2、支持响应式交互
浏览网页中,经常会遇到执行某些操作后才出现相关页面元素的情况。这种场景用普通爬虫方式很难模拟,但对于Selenium来说,却有着先天优势。
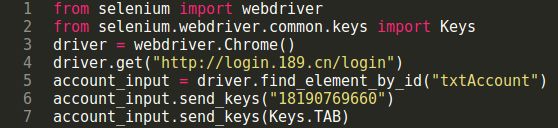
以中国电信登录页为例,对于多次登录错误的帐号会出现图片验证码,而该验证码只有在输入帐号后才会出现。普通做法,分析整个过程中执行了哪些请求,请求cookie和请求参数如何获得,然后模拟发送请求获取结果。例如该场景中,通过抓包分析可知当中有三次关键请求(如图)。

第一次根据号码获得城市代码,第二次检查对应手机号登录是否需要验证码,第三次获取验证码图片。
然而仅仅看这三次请求,其所需输入都是欠缺的,因此整个分析过程会变得非常繁杂。此时使用Selenium直接模拟登录操作,不失为一种简单有效的方法。整个模拟过程如图所示:

代码示例:
3、丰富的html解析支持
Selenium API提供丰富的方法获取页面元素,支持多种方式进行元素定位选择,比如根据元素id,name,xpath,css选择器等。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
当然同时也支持直接返回网页源代码,然后再自行使用其它第三方html解析库进行解析。
4、动作链(ActionChains)
动作链是Selenium提供的用于模拟自动化交互的方式,如鼠标移动,鼠标按键点击,键盘按键点击和复杂菜单交互等等。在复杂的动作场景中,比如拖拽和滑动,非常有用。
基于此,Selenium爬虫可以实现一些普通爬虫难以实现的功能,比如特征位点击、滑动验证码自动验证等。以某常见滑动验证码为例,合理使用动作链可以实现自动验证,效果如下图所示:
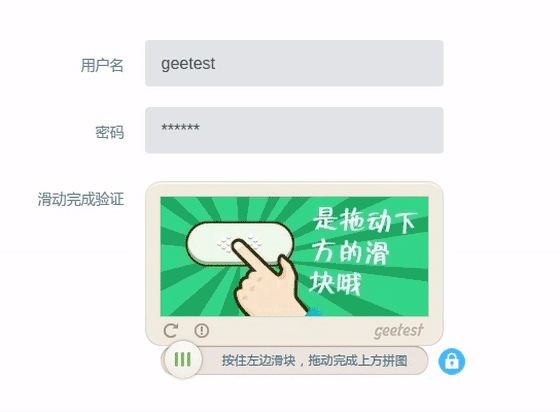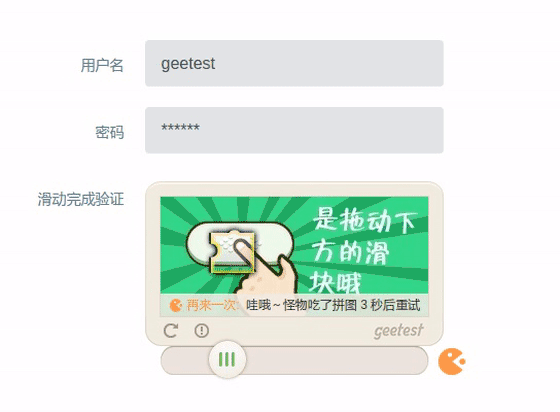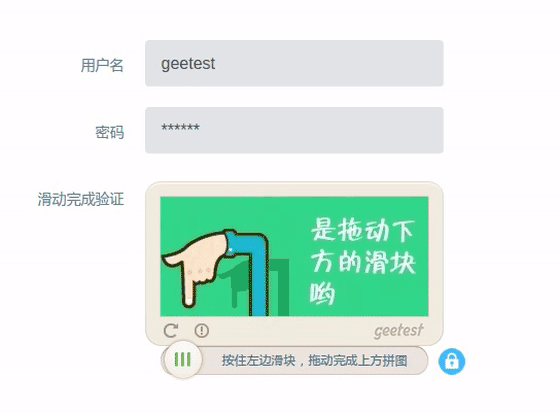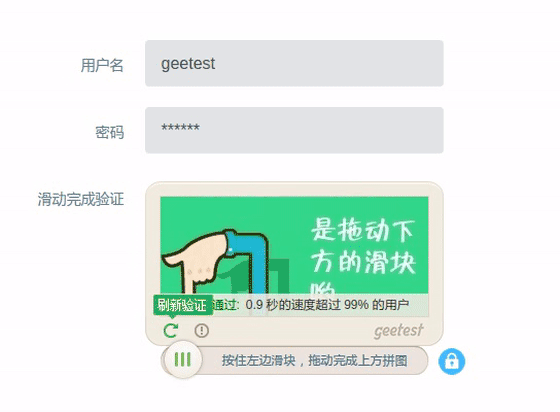
注:具体实现方式不在本文敖述,大概思路为:获取完整背景图片及缺块图片,通过比较获得缺块位置,得出滑动距离,再用Selenium模拟鼠标拖拽滑动实现自动滑动验证。示例中可以看出两次尝试后才验证成功。因此成功率并非100%,所以加入自动重试以保证验证结果。
总结
优点
通过以上几个例子可以看出,在网页爬虫中应用Selenium的优势特别明显。
完全浏览器化的操作简化掉了请求分析的过程,让爬虫开发更多关注于页面解析和结果处理。
爬虫实现难度比较低。对于某些特殊的场景,比如对同样功能的查询类网站进行查询接口封装,Selenium能够通过模拟浏览器的查询操作快速实现。
缺点
因为Selenium实际上使用了浏览器,所以其缺点也显而易见。
资源占用大,每开一个浏览器进程就会占用将近20MB左右内存,在爬虫应用中需要进行及时关闭释放,因此这也注定了Selenium爬虫不适用于批量爬取。
速度慢,因为浏览器请求页面会加载所有相关的资源请求,同时还有页面操作的模拟过程,会导致爬虫的执行周期较长,因此也不适用于即时性要求较高的场景。
来自于测试领域的Selenium,对于爬虫应用来说是一柄利剑同时也是一把重剑,只有恰当的取舍和准确的使用才能真正达到“他山之石,可以攻玉”的最终目的。
本文作者:彭英杰(点融黑帮),就职于点融成都Data Team,负责接口集成以及爬虫开发工作。喜欢折腾新事物,爱游戏,爱运动。