1.新建spark开发项目:
1. 使用maven命令行创建一个项目:
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.pmpa.bigdata.spark.app -DartifactId=log-analyzer -Dversion=1.0
我是在windows环境处理的。
2. 从IDEA导入这个用命令行新建的项目:
-
打开一个现有的IntelliJ IDEA工程,点击菜单的“File”->“new”->“Module from Existing Sources...”。
如下图所示:
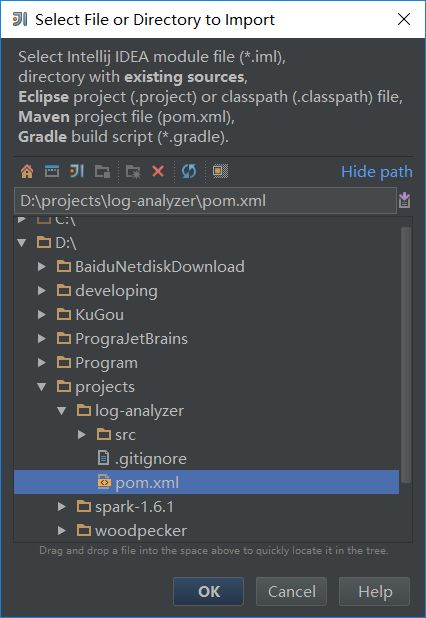 导入maven项目.png
导入maven项目.png
记得下边这项一定勾上:
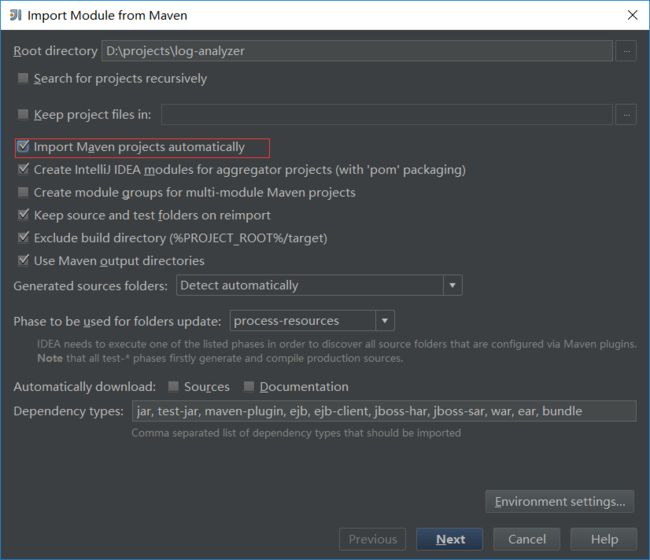 勾选对应项.png
勾选对应项.png
删除pom.xml文件中关于scala的一些内容(scala.version)。 添加依赖:
在官方文章《Spark Programming Guide》中,标识了需要添加的依赖:
org.apache.spark
spark-core_2.10
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop-client.version}
3.程序开发:
在读取文件时候,需要将文件上传到hdfs上,在读取文件时候,指定hdfs的完整URL:
val rdd1 =
sc.textFile("hdfs://192.168.8.128/user/natty/examples/input-data/text/data.txt")
println(s"The ouput of spark pmpa: ${rdd1.first()}")
2. IDEA导入Spark源码:
1.首先,下载spark对应版本的源码,可以在github或者官网的下载地址都可以。
如果在官网下载,解压压缩包,将源码包放在某个目录。
2.打开IDEA,关闭现有的项目,回到主页面。 File -> Close Project :
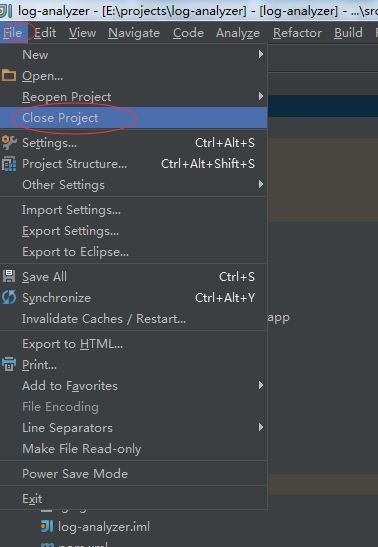
项目关闭后,回到了这个界面:

点击“import project”,并且选择源码包的目录,导入即可:
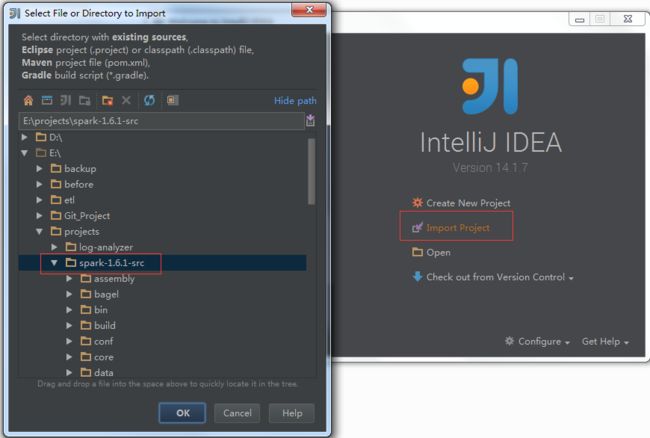
下面选择“Import project from existing mode”,并且下面选择Maven:

勾选以下选项:
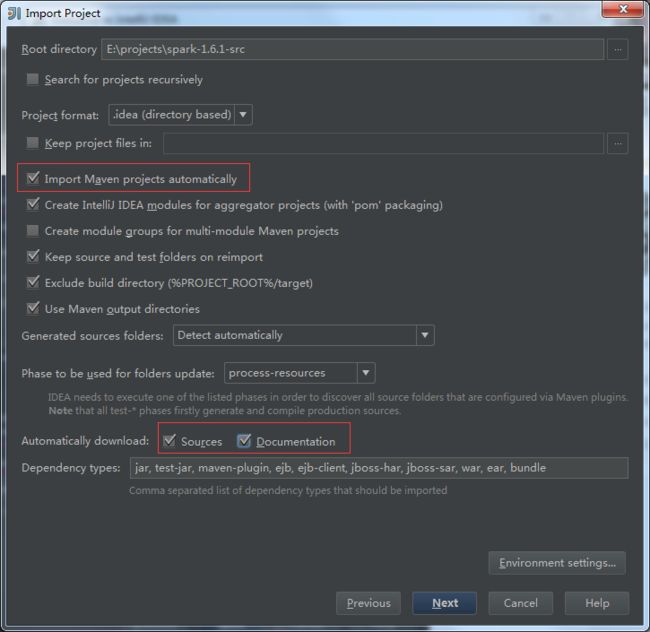
3. Spark运行的三种模式:
Yarn模式。
Standalone模式(40%):自身携带的分布式资源管理和任务调度。
Local本地模式。
4. 安装本地模式:
1.自行编译spark源码,按照我们使用的hadoop版本,scala版本等因素,定制化编译源码,获得编译包后,首先解压安装包。
$ tar -zxf spark-1.6.1-bin-2.5.0-cdh5.3.6.tgz -C /opt/modules
2.配置单机模式:
spark的配置非常简单,需要配置JAVA_HOME,SCALA_HOME绝对路径;再配置Hadoop的配置文件地址即可。这里,我们需要三个配置文件:log4j.properties;slaves;spark-env.sh。下面,修改配置文件$SPARK_HOME/conf/spark-env.sh.template
$ cp spark-env.sh.template spark-env.sh
这样,直接修改文件“spark-env.sh”,增加这3项的配置:
JAVA_HOME=/opt/modules/jdk1.7.0_67
SCALA_HOME=/opt/java/scala-2.10.4
HADOOP_CONF_DIR=/opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop
3.测试安装情况:
启动spark命令行:
$ ./bin/spark-shell
4.说明:
所有的Spark程序,入口都是SparkContext
【问题】虚拟机拷贝后,发现IP有改变,造成错误,发现原因,eth0网卡配置后没有使用,而是用了 eth1网卡,导致Hadoop和Spark相关的配置都有错误,在网上找了解决方法:
1.修改配置文件:vim /etc/sysconfig/network-scripts/ifcfg-eth0
把其中的 mac地址修改和vmware中生成的一样。
2.删除文件 rm /etc/udev/rules.d/70-persistent-net.rules
5. Standalone模式使用:
Standalone不是单机模式,而是spark本身自带的一个分布式资源管理系统以及任务调度的框架。
类似于yarn这样的框架(包含主节点和从节点),是分布式的:
主节点:
Master -> ResourceManager
从节点:
Workers -> NodeManager
Standalone模式的配置方法:
1.配置文件 $SPARK_HOME/conf/spark-env.sh 文件。
需要配置以下参数:
SPARK_MASTER_IP :主节点IP/Hostname
SPARK_MASTER_PORT :主节点的端口号 默认7077
SPARK_MASTER_WEBUI_PORT : 主节点的WEB UI界面的端口号 8080
SPARK_MASTER_IP=hadoop-senior01.pmpa.com
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
2.配置文件 $SPARK_HOME/conf/slaves
上边配置好了master,那么worker运行在哪个机器呢,如何配置呢,运行为Worker节点是哪台机器通过配置文件 $SPARK_HOME/conf/slaves中。
# A Spark Worker will be started on each of the machines listed below.
hadoop-senior01.pmpa.com
这样确定了运行为WORKER的机器后,下面将其他一些属性进行配置即可。回到spark-env.sh文件,添加如下属性:
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
SPARK_WORKER_INSTANCES=1
Spark集群中的每个节点可以运行多个WORKER,由参数SPARK_WORKER_INSTANCES决定,一般运行一个worker。
3.启动spark:
配置好了上边的选项后,下面启动spark,spark的启动脚本都在$SPARK_HOME/sbin下。主要了解2个启动脚本:
start-slaves.sh: 启动所有的从节点,也就是worker。使用此命令时,运行此命令的机器,必须要配置与其他机器的无密码登录。
start-master.sh:启动主节点,也就是master。
下面我尝试启动spark:
启动主节点:
$ ./start-master.sh
通过jps可以查看到Master进程。
启动从节点:
$ ./start-slaves.sh
通过jps可以查看到Worker进程。
4.查看spark主节点和从节点的监控页面:
根据我们上边配置的2个参数:
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_WEBUI_PORT=8081
根据这2个配置端口,查看worker和master的监控页面:
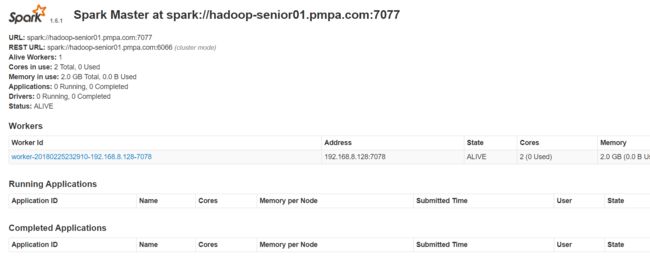
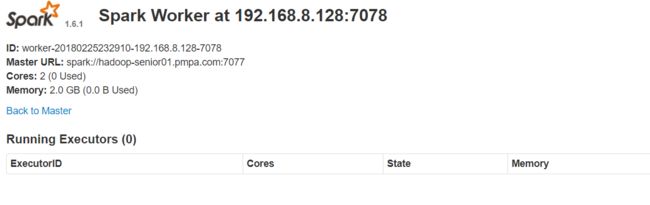
6. 集群测试:
根据我们上边安装的standalone环境,我们可以在集群上测试。上边,我们使用过spark-shell,但是如果只运行命令./bin/spark-shell,那么spark-shell是运行在本地上的,不是运行在集群上的。(如何测试这点呢,在本地启动一个spark-shell,提交一个job,你在监控页面上看不到这个job)
那么,如何将spark shell运行在集群上呢,使用 --master参数:
./bin/spark-shell --master spark://hadoop-senior01.pmpa.com:7077
这时候,我们在集群上可以发现这个application:
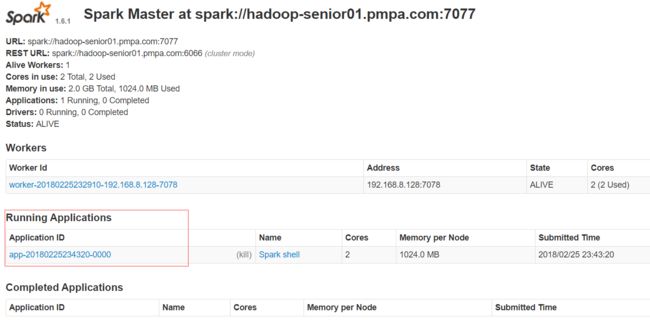
Spark Application由2部分组成:
1.Driver Programe:运行main方法,包含SparkContext(最关键对象)。
2.Executor:启动了JVM,包含资源来运行任务。运行job的task
每个Spark Application可以包含多个job(与mapreduce不同),同时,每个job又划分成多个stage,每个stage又划分成多个task。每个stage中的所有task,业务都是相同的,只不过处理的数据不同。不同的task是同一个进程的不同线程。
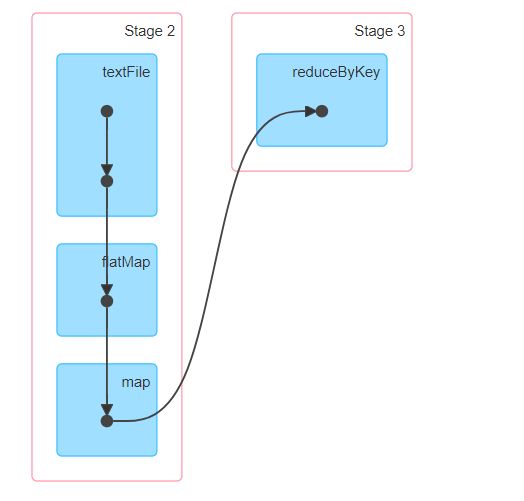
Spark UI中的DAG图,划分不同的stage,依据是有shuffle过程,就会出现一个新的stage。例如,运行wordcount时,如下代码:
val rdd1 = sc.textFile("/user/natty/README.md")
rdd1.flatMap(_.split(" ")).map( a => (a,1)).reduceByKey((a,b) => a+b).collect
有下面的DAG图:
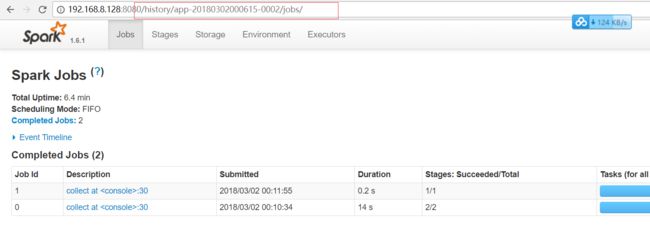
. 7.Spark HistoryServer配置:
关于history Server配置的相关文档在官方文档的这个入口:
首先我们启动一个Application来测试是否有HistoryServer:
有2个地方需要配置以启动History Server:
修改配置文件$SPARK_HOME/conf/spark-defaults.conf
spark.master spark://hadoop-senior01.pmpa.com:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-senior01.pmpa.com:8020/user/natty/sparkEventLogs
修改$SPARK_HOME/conf/spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop-senior01.pmpa.com:8020/user/natty/sparkEventLogs -Dspark.history.fs.cleaner.enabled=true"
最后启动historyserver:
$ sbin/start-history-server.sh