声明:本文仅限于发布,其他第三方网站均为盗版,原文地址: 一致性哈希及其 Python 实现
记得之前看一些集群数据库或者和集群相关的文章和书籍的时候,总是会有人提到一致性哈希这个东西,一开始感觉挺稀奇,挺神奇的,渐渐得看得多了,也就习以为常了。但是,虽然看了那么多的介绍,大多数都是理论层面讲讲,所说这是什么东西,什么原理,然后就完了,顶多再补充一下再具体的应用场景里面有什么好处。
作为一个开发者,我更关注于说这个东西怎么实现好用,有什么比较好的数据结构,好的实践可以更好得满足我们的目的。很可惜的是,我看的大部分书都没有说这个,我一开始还傻傻得以为真的用一个数组来设置哈希环,然后所有实例都哈希到对应的位置上,然后要哈希 key 的时候在环里一个个找。这是一个比较傻的方法,不过这是建立在我对一致性哈希的小规模应用场景的思维方式下,所以产生了这个想法,虽然一开始我就觉得不大可能,但是没细想它,最近突然看到 Map 这个数据结构(这个纯属 Java 学艺不精,当年写 Java 的时候没有区分 HashMap 和 TreeMap 的区别,罪过罪过)居然有人用红黑树实现的时候,我心里有一些想法冒出来了。
一致性哈希
废话说得有点多,还是先进入到主题吧,什么是一致性哈希。要说一致性哈希,我想来讲个普通的哈希表的例子,大家先看看有什么问题,下面先来一段描述:
假设我们有 5 台 MySQL 服务器,然后对数据库进行水平拆分,也就是对于插入表中的数据,我们对记录的 id 进行哈希映射到 0~4 的区间,然后根据哈希结果保存到对应的 MySQL 服务器中。
这个方案乍一看问题不大,但是,在不考虑冗余备份的情况下,我们考虑一下如果其中一台数据库宕机了,我们的数据就会因为这种哈希算法而乱掉,我们就需要定义新的哈希算法,将哈希映射到 0~3 的区间上,然后再对 所有的数据 进行重新分配,这对于分布式存储来说是很严重的问题。
那针对这个问题,我们当然是不希望重新分配 所有的数据 啦,我们期望的是重新分配的数据只是宕机的那台机器上的数据就好,而且我们的存储和获取逻辑还不需要更换,这就是一致性哈希的常见应用场景。
为了简单理解,我就简化描述,我们可以认为 一致性哈希比普通哈希表多做了一次哈希,也就是不仅仅数据做哈希,机器也做哈希;怎么理解,假设对于刚才的例子,我们构建一个 32 个位的环,我们将机器作哈希(这里可以使用任意的哈希函数,不过最好均匀一些)到 0~31 的区间里,假设哈希后的位置是这样的:
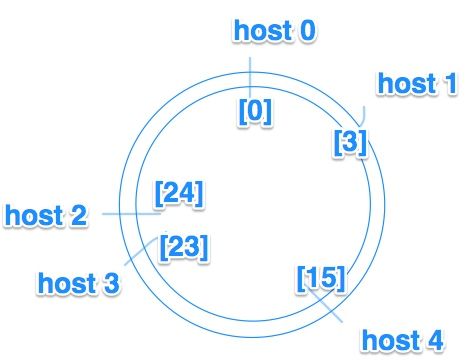
然后我们再对数据根据 id 进行映射,也是映射到 0~31 的区间内,假设 id 为 10086 的数据的哈希值是 18,那么我们就从环中 18 的位置开始寻找,只到找到第一个主机为止,在这个环中它就是 host3,也就是哈希值为 23 的机器,然后我们就可以将数据存储到这台机器了。
这就是一致性哈希的简单描述啦!那我们就来看看这样子有什么好处,先来看看机器宕机了吧,假设 host4 宕机了,那么一致性哈希会怎么处理?根据这个情况,我们从图中也可以发现,host4 中的数据都会迁移到 host3 中,除此之外就不需要做什么了。
增加一台主机也一样,假设我们增加了一台主机 liuliqiang.info,那么我们会发现这个环就应该变成这样:
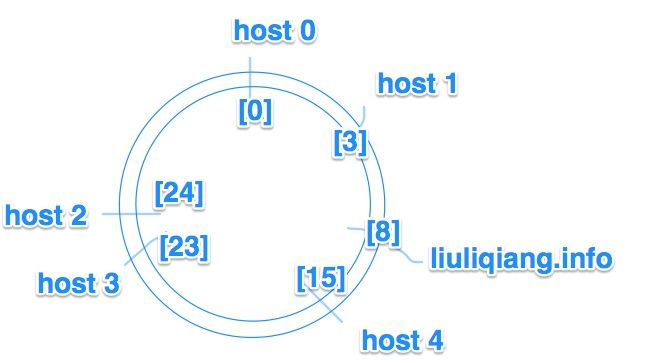
然后可以发现,原来放到 host4 的数据就可以迁移一部分到新的机器上,只是局部影响,而不是导致全体主机的数据收到波动影响。
但是,目前这都是最原始的,还是问题比较大,因为从上面可以看到,假设一台机器宕机之后,那么就会导致 host4 的数据全都迁移到 host3 中,从概率上来讲,host3 承载了 40% 的数据,比其他机器多了一倍负载,很可能会发生 雪崩效应 ,当然,一致性哈希还是可以解决这个问题。我知道的一个比较常用的方法就是使用 虚拟节点,也就是说一台主机,不仅仅只在环上有一个位置,而是多个位置,例如这样:
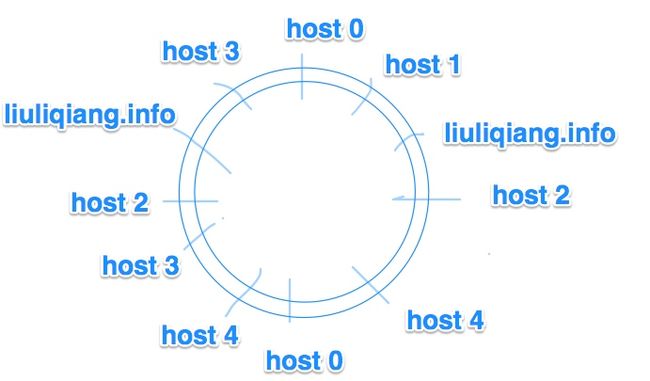
这样我们就可以看到,假设还是 host4 崩了,那么他一部分的数据会转给 host0,还有一部分数据会转给 host3,如果我们将虚拟节点再多一些,可能会更平均一点。至于怎么映射虚拟节点到多个节点,这个也很简单呀,我们可以这样做嘛:
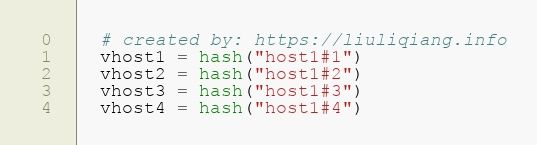
这样我就定义了 host1 的 4 个虚拟节点啦。
Python 实现
讲完原理之后,是时候上真刀真枪了,前面说了,我想用红黑树去实现它,为什么呢?考虑一下前面的说的,前面给的例子是一个 32 长度的环,这个确实比较好办,但是,假设我机器就几百台,那环就会更大,随着机器的增加或者我们做一些虚拟节点,这个环就会很大了,影响了查找效率,这是一方面;另一方面,我们从上面的例子中也可以看到,环中除了一些有意义的位置存了主机的信息之外,还有很多位置是闲置的,这又浪费了内存空间。
其实,细想一下,这里根本就不需要有真的环实体存在,理论上经常说环是为了方便理解,但是事实上在实现的时候我们可以忽略环这个概念,将它转化为一个排序的数组,例如上面的例如,我们可以将哈希值排序,排序为:[0, 3, 8, 15, 23, 24]
当我们有一条数据例如哈希值是 10 的记录要保存时,我们不用找环了,直接在排序的哈希数组里面二分查找大于 10 的最小记录,也就是 15,这样就保证了空间的合理利用,查找效率上也不差,最坏也是 log(n)。
但是,在转化成代码的时候,我们又要考虑了,这里要用什么数据结构?数组好不好?首先数组可以保证我们查找的效率,但是,删除和新增的复杂度时很高的,将会达到 O(n),而且我们数组的大小也是问题,要怎么分配这个数组的大小,如果太小以后不够是不是要扩容?所以不是很合适。链表呢?删除和新增效率很高,但是我们比较常用的查找性能又不行,用跳表来弥补?空间浪费又来了。。。
好吧,权衡之下,我选择了用 红黑树,红黑树有什么特点?它最大的特点就是平均,它可以保证在最坏的情况下,基本的操作都是 log(n),下面是一张别人总结的对比图:
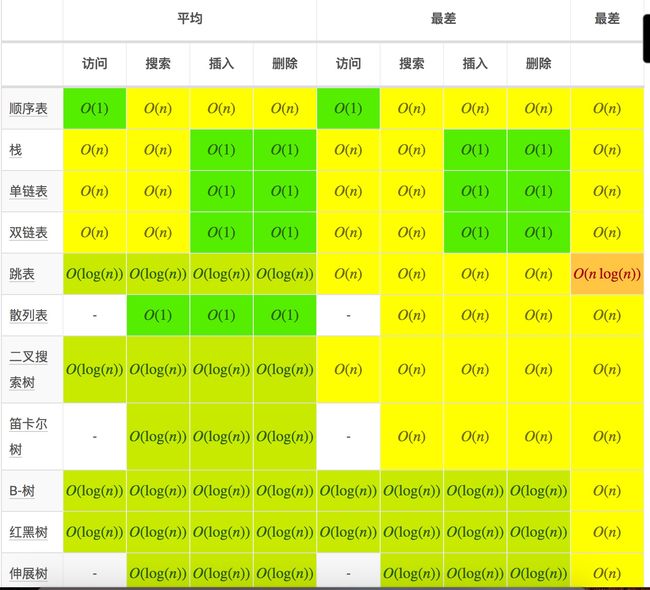
所以用红黑树来保存还是非常合适的。
下面用 Python 代码来模拟一下这个一致性哈希的过程,其实可以分为三个部分:
- 新增主机
- 删除主机
- 查找主机
然后红黑树的实现我是使用的 bintrees,首先,想看下我们的主机的 model 是怎么写的,需要保存些什么内容:

这里我就保存了主机的名称,还有它们的哈希值,这个后面会用到,然后再来看看增加主机怎么写:
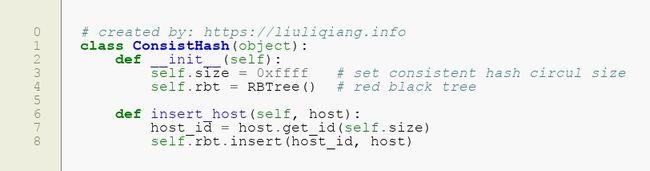
插入的代码可以很简单得写出来,因为我们已经封装好了节点以及红黑树,所以也就没什么难度了,还有删除的也会很简单:
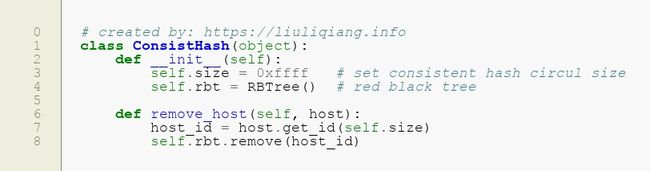
没啥大毛病,下面的关键来了,就是如何查找存放数据的主机,这个很关键,也是二叉查找树里面的一个比较有意思的问题,就是如何查找不小于指定元素的最小元素节点,我是这么写的:
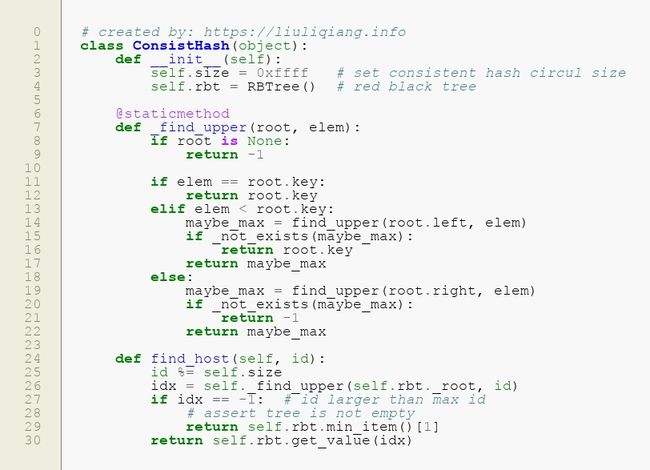
这里对对查找逻辑做了一些简单封装,有一点需要注意的是,如果要查找的 id 比所有的主机的 id 都要大,那么就应该选取环中 id 最小的那个元素(回顾一下前面)。这样整个简单的代码就完成了。
本文的所有代码都可以在我的 Github 代码片段中找到:Github代码片段
Reference
- 红黑树详解
- 复杂度速查表
- Python 红黑树实现
- Consistent hashing