选型背景
这次采用开源监控系统主要是为了监控一些自定义业务并进行告警,所以重点关注了上传自定义数据、监控、显示、存储、告警四个方面,由于公司运维已经有监控机器指标的工具,所以监控机器指标这方面不是重点。
各监控告警系统简介
Zabbix
官方文档:https://www.zabbix.com/documentation/3.4/zh/manual
官方文档比较详细,中英文都有。
后端用C开发,界面用PHP开发。
图形化界面比较成熟,界面上基本能完成全部的配置操作。
Prometheus
官方文档:https://prometheus.io
第三方中文文档:https://songjiayang.gitbooks.io/prometheus/content/introduction/what.html
go语言开发,前端支持Grafana展示
抓取数据是通过node_exporter插件,这些插件有官方的也有第三方的。引入插件的同时必须配置监控的指标。
与其他监控框架显著的不同是支持灵活的查询语句(PromQL)
在常用查询和统计方面,PromQL 比 MySQL 简单和丰富很多,而且查询性能也高不少。
注意
- Prometheus 的数据是基于时序的 float64 的值,如果你的数据值有更多类型,无法满足。
- Prometheus 不适合做审计计费,因为它的数据是按一定时间采集的,关注的更多是系统的运行瞬时状态以及趋势,即使有少量数据没有采集也能容忍,但是审计计费需要记录每个请求,并且数据长期存储,这个 Prometheus 无法满足,可能需要采用专门的审计系统。

open-Falcon
官方文档:http://book.open-falcon.com/zh_0_2/dev/support_grafana.html
后台是go语言开发,前端支持Grafana展示
抓取数据通过脚本插件抓取日志或调用CLI,脚本组装数据发送给主服务端,配置是可选项,在脚本插件处进行配置。
- 现在的策略表达式中只能配置一条规则,此处应该支持配置多条,任何一条触发,就要发报警,不同规则之间应该支持覆盖

监控自定义指标
prometheus
Pushgateway是prometheus的一个重要组件,利用该组件可以实现自动以监控指标,从字面意思来看,该部件不是将数据push到prometheus,而是作为一个中间组件收集外部push来的数据指标,prometheus会定时从pushgateway上pull数据。

pushgateway并不是将Prometheus的pull改成了push,它只是允许用户向他推送指标信息,并记录。而Prometheus每次从 pushgateway拉取的数据并不是期间用户推送上来的所有数据,而是client端最后一次push上来的数据。因此需设置client端向pushgateway端push数据的时间小于等于prometheus去pull数据的时间,这样一来可以保证prometheus的数据是最新的。
需要注意的点
如果client一直没有推送新的指标到pushgateway,那么Prometheus获取到的数据是client最后一次push的数据,直到指标消失(默认5分钟)。
Prometheus本身是不会存储指标的,但是为了防止pushgateway意外重启、工作异常等情况的发送,在pushgateway处允许指标暂存,参数--persistence.interval=5m,默认保存5分钟,5分钟后,本地存储的指标会删除。
prometheus官方提供了Java工具类用来上传自定义指标到pushgateway
特点
- prometheus默认采用pull模式,由于不在一个网络或者防火墙的问题,导致prometheus 无法拉取各个节点的数据。
- 监控业务数据时,需要将不同数据汇总,然后由prometheus统一收集
缺陷
将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
Prometheus 拉取状态
up只针对 pushgateway, 无法做到对每个节点有效。Pushgateway 可以持久化推送给它的所有监控数据。
因此,即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。
Open-falcon
如果需要监控自定义指标,有两种方式
- 需要自己通过Http Push指标数据到Client的Agent组件提供的接口,再通过组件Agent上报数据到open-falcon主服务上的Transfer组件做一个汇总。
- 编写采集脚本,用什么语言写没关系,只要目标机器上有运行环境就行,脚本本身要有可执行权限。采集到数据之后直接打印到stdout即可,agent会截获并push给server。数据格式是json。
官方推荐把采集脚本放到业务程序发布包中,随着业务代码上线而上线,随着业务代码升级而升级,这样会比较容易管理。
Agent上传数据的间隔时间是可配置的。

transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。
Transfer接收数据时会做少量缓存,提供重试机制。
自定义数据格式
[
{
"endpoint": "test-endpoint",
"metric": "test-metric",
"timestamp": ts,
"step": 60,
"value": 1,
"counterType": "GAUGE",
"tags": "idc=lg,loc=beijing",
}
]
字段说明:
- metric: 最核心的字段,代表这个采集项具体度量的是什么, 比如是cpu_idle呢,还是memory_free, 还是qps
- endpoint: 标明Metric的主体(属主),比如metric是cpu_idle,那么Endpoint就表示这是哪台机器的cpu_idle
- timestamp: 表示汇报该数据时的unix时间戳,注意是整数,代表的是秒
- value: 代表该metric在当前时间点的值,float64
- step: 表示该数据采集项的汇报周期,这对于后续的配置监控策略很重要,必须明确指定。
- counterType: 只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
- GAUGE:即用户上传什么样的值,就原封不动的存储
- COUNTER:指标在存储和展现的时候,会被计算为speed,即(当前值 - 上次值)/ 时间间隔
- tags: 一组逗号分割的键值对, 对metric进一步描述和细化, 可以是空字符串. 比如idc=lg,比如service=xbox等,多个tag之间用逗号分割
说明:这7个字段都是必须指定
Zabbix
zabbix中监控项叫做item,监控项的取值方法叫做key。
item: Items是从agnet主机里面获取的所有数据。通常情况下我叫itme为监控项,item由key+参数组成。
Key:我们可以理解为key是item的唯一标识,在agent端有很多监控项,zabbix-server根据key区分不同的监控项。

zabbix_server通过发送key给zabbix_agent,然后agent端口根据key执行设定好的sheel脚本,把所要监控的item的最新数据返回给server端。同Open-falcon的第二种方式大致相同,不同点在于数据格式。zabbix是k-v键值串。value支持五种格式:数字(无正负)、浮点数、字符、日志、文本。
总结
Zabbix创建自定义监控任务,获取自定义数据指标只能通过执行设定好的脚本获取脚本print出的值,如果希望实现java业务上的监控,没有现成的插件或Api调用,只能通过调用脚本(比如脚本调用Mysql客户端直接查库或者Curl访问)的方式,比较迂回,没有像Prometheus直接调用官方Java的Api、Open-falcon通过Http上传数据这样来的方便且安全。
显示
Open-falcon
前后端组件可以分开部署
默认的Dashboard监控指标效果图


除了默认的之外,支持Grafana视图展现,Grafana可以很有弹性的自定义图表,并且可以针对Dashboard 做权限控管、上标签以及查询,图表的展示选项也更多样化。
Grafana监控指标效果图


Prometheus
Prometheus 自带了 Web Console, 安装成功后可以访问 http://localhost:9090/graph 页面,用它可以进行 PromQL 查询和调试工作
效果图

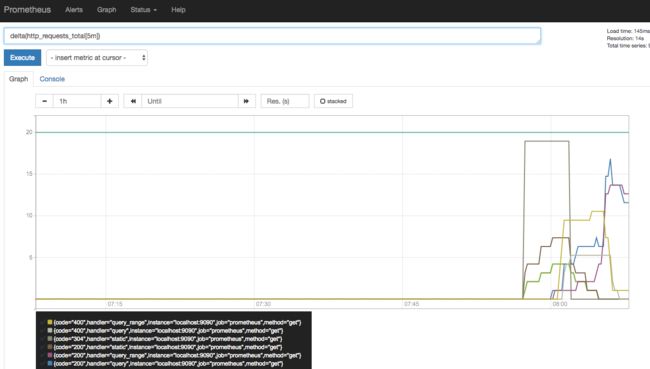
Prometheus同样支持Grafana数据展示。
Zabbix
Zabbix的使用手册文档很全面,页面的功能及使用方式介绍的很清晰。
默认的页面显示效果图


Zabbix也支持Grafana视图展示。
存储
Open-falcon
Open-falcon存储数据用了三个数据库分别是MySQL、Redis、RRDTool(一种时序数据库)。
Open-falcon存储过程主要是靠Graph组件,将索引部署保存在MySQL中,监控数据保存在RRD中,使用一致性哈希来对数据做均匀的分片。
Redis主要用于存储judge产生的报警event,alarm从redis读取处理event,已经发送的报警事件会写入MySQL。
数据存储的流程大致为:
大致流程为:
- 接收数据=>保存监控数据=>保存索引=>保存历史数据
- 定期将内存数据GraphItems写入磁盘
- 定期更新索引到mysql
1、2、3这三个过程并行运行。
流程图:
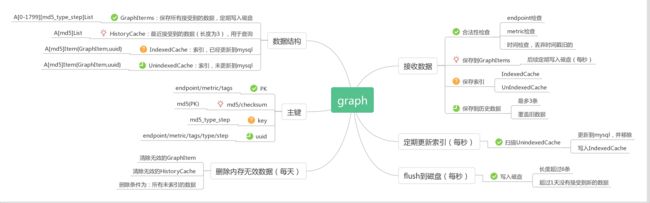
Prometheus
Prometheus内部主要分为三大块,Retrieval是负责定时去暴露的目标页面上去抓取采样指标数据,Storage是负责将采样数据写磁盘,PromQL是Prometheus提供的查询语言模块。


通过这张架构图可以看出,Prometheus的本地存储使用了tsdb时序数据库。本地存储的优势就是运维简单,缺点就是无法海量的metrics持久化和数据存在丢失的风险。
为了解决单节点存储的限制,prometheus没有自己实现集群存储,而是提供了远程读写的接口,让用户自己选择合适的时序数据库来实现prometheus的扩展性。
Prometheus通过下面两种方式来实现与其他的远端存储系统对接
- Prometheus 按照标准的格式将metrics写到远端存储
- Prometheus 按照标准格式从远端的url来读取metrics

Zabbix
数据存储在Mysql中,Zabbix 3.4.6版本开始支持历史数据存储到Elasticsearch。
总结
如果只是短期存储和查询,那么Prometheus、Open-falcon、zabbix现有的都能满足要求。但如果要对大量数据进行分析预测等过程,则三者都需要转用其他可接入spark、mapreduce等的数据库。Open-falcon需要进行二次开发,Prometheus提供了远程读写的接口。Zabbix网上没查到二次开发使用MySQL、ES外其他数据库的,而且Zabbix后台用C开发,二次开发的难度也比较大。
报警
Open-falcon
Open-falcon的报警主要通过judge、Alarm、AlarmManager三个组件来实现。
Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
AlarmManager模块主要有两大功能,一个用于注册告警数据接收服务、提供告警事件多条件查询功能;另外一个是针对告警事件升级为故障,定制化处理功能。
目前功能有:
- 可配置报警级别,比如P0/P1/P2等等,每个及别的报警都会对应不同的redis队列
- 报警消息聚类,针对同一个策略发出的多条报警,在MySQL存储的时候会聚类
- 报警合并,有的时候报警短信、邮件太多,对于优先级比较低的报警,希望做报警合并,这些逻辑都是在alarm中做的。
- 针对告警信息生成一个跟进事件(事件定义为故障),可以将告警事件的处理过程通过时间轴管理起来,可新增、更改故障、增加告警时间、关注、状态变更(关闭、废弃、重新打开)、输出故障时间轴
- 告警管理,可指定接收者和其他条件快速过滤关注的告警、告警数量、已经添加至故障的告警信息等
目前告警管理数据来源于alarm组件推的方式。alarm-manager组件实现告警数据的自管理,组件提供专门的接收数据接口,其它告警数据通道可按照一定数据格式进行推动,用于其它监控平台的数据流入、告警管理。
配置报警策略的时候open-falcon支持多种报警触发函数,比如all(#3) diff(#10)等等。 这些#后面的数字表示的是最新的历史点,比如#3代表的是最新的三个点。该数字默认不能大于10,大于10将当作10处理,即只计算最新10个点的值。(#后面的数字的最大值,即在 judge 内存中保留最近几个点,是支持自定义的,)
报警策略:
all(#3): 最新的3个点都满足阈值条件则报警
max(#3): 对于最新的3个点,其最大值满足阈值条件则报警
min(#3): 对于最新的3个点,其最小值满足阈值条件则报警
sum(#3): 对于最新的3个点,其和满足阈值条件则报警
avg(#3): 对于最新的3个点,其平均值满足阈值条件则报警
diff(#3): 拿最新push上来的点(被减数),与历史最新的3个点(3个减数)相减,得到3个差,只要有一个差满足阈值条件则报警
pdiff(#3): 拿最新push上来的点,与历史最新的3个点相减,得到3个差,再将3个差值分别除以减数,得到3个商值,只要有一个商值满足阈值则报警
lookup(#2,3): 最新的3个点中有2个满足条件则报警;
stddev(#7) = 3:离群点检测函数,取最新 **7** 个点的数据分别计算得到他们的标准差和均值,分别计为 σ 和 μ,其中当前值计为 X,那么当 X 落在区间 [μ-3σ, μ+3σ] 之外时,则认为当前值波动过大,触发报警;更多请参考3-sigma算法:https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule。
支持的通知方式:
- 短信
- 微信
- 邮件
- 电话
需要提供Http的发送接口。
Prometheus
Prometheus的告警通过组件AlertManager来实现。报警过程分为两步,根据创建的告警规则发送警报给Altermanager。Altermanager然后管理这些警告,包括沉默,禁用,聚合和通过各种方式例如email,pagerDuty和HipChat发送通知。
配置配置报警和发送通知的主要步骤有:
- 设置和配置Alertmanager。
- 配置Prometheu去通知Alertmanager。
- 在Prometheus中创建报警规则。
告警流程图:

目前功能有:
- 告警分组,作为用户同类报警只想看到单一的报警页面,同时仍然能够清楚的看到哪些实例受到影响,因此,人们通过配置Alertmanager将警报分组打包,并发送一个相对看起来紧凑的通知。
- 抑制,抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。
- 静默,其实就相当于限流,一定时间内不再为满足设定规则的用户发送告警。
- 告警延时,假设系统发生故障产生告警,每分钟发送一条告警消息,这样的告警信息十分令人崩溃。Alertmanager提供第一个参数是repeat interval,可以将重复的告警以更大频率发送。
通知方式则是使用WebHook来实现,支持钉钉机器人、企业微信、电话、短信、邮件等,资料比较少。
Zabbix
报警流程:
首先item(监控项)拿到server端的数据,收集到数据后,如果它和一个trigger(触发器)绑定了,那么会检查trigger的状态。
是否变成异常状态,然后按照trigger的状态生成一个事件(无论状态变与不变都会生成),最后检查报警动作。其实也就是满足Trigger的触发条件便会执行绑定的Action(动作)

定义触发器的表达式,其实就是配置报警的触发条件,定义页面如下图

配置触发器页面

选择触发器级别

创建Action的页面大同小异。
总结
Zabbix文档资料较少,配置项不多,功能不够丰富,优点是直接可以在页面上进行配置;Prometheus功能比Zabbix多,比Open-falcon少,配置项多但文档不够详细;Open-falcon功能丰富,官方文档也比较详细。
整体总结
这次采用开源监控系统主要是为了监控一些自定义业务并进行告警,所以重点关注了上传自定义数据、监控、显示、存储、告警五个方面,由于公司运维已经有监控机器指标的工具,所以监控机器指标这方面不是重点。
Zabbix后台采用了C语言,监控数据存储在关系型数据库内,如MySQL,很难从现有数据扩展维度,定制化难度较高,自定义监控指标的接入只能依靠shell脚本的运行,监控及告警的配置功能不够丰富,所以优先排除。
Prometheus和Open-falcon后台都是采用Go编写,相对C而言要好二次开发一些。Prometheus支持PromQL数据查询语言,对比常用的SQL语言而言查询性能高、Prometheus在集群存储方面官方提供了接口方便扩展对流处理有优势的数据库,如果需要对数据进行预测的话Prometheus有着较大的优势,Open-falcon虽然不方便扩展,但目前功能也足够使用。监控自定义指标Prometheus官方也提供了对应的Java接口,Open-falcon虽然没有提供,但是编写上传数据接口的难度也不大。Open-falcon在报警规则、告警通知配置方面功能要比Prometheus丰富。
最后总结,如果有需要对监控指标趋势进行预测的话,选择Prometheus。如果不需要预测的话,选择Open-falcon。
文中如果有错误,欢迎批评指正。