本系列博客是本人的开发笔记。为了方便讨论,本人新建了一个微信群(iOS技术讨论群),想要加入的,请添加本人微信:zhujinhui207407,【加我前请备注:iOS 】,本人博客http://www.kyson.cn 也在不停的更新中,欢迎一起讨论
背景
今天朋友圈被一篇文章(以下简称“coobjc介绍文章”)刷屏了:刚刚,阿里开源 iOS 协程开发框架 coobjc!。可能大部分iOS开发者都直接懵逼了:
- 什么是协程?
- 协程的作用是什么?
- 为什么要使用它?
因此笔者想给大家普及普及协程的知识,运行一下coobjc的Example,顺便分析一下coobjc源码。
分析
协程的维基百科在这里:协程。引用里面的解释如下:
协程是计算机程序的一类组件,推广了非抢先多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程源自Simula和Modula-2语言,但也有其他语言支持。协程更适合于用来实现彼此熟悉的程序组件,如合作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
根据高德纳的说法, 马尔文·康威于1958年发明了术语coroutine并用于构建汇编程序。
对,还是一知半解。但最起码我们了解到
- 协程的英文是“coroutine”,因此我们能理解阿里的库起名为
coobjc的含义。那么这个词又是怎么来的呢?笔者再深挖一下,协程(coroutine)顾名思义就是“协作的例程”(co-operative routines)。 - 协程是和进程或者线程有一定关系的
- 协程的历史还是比较悠久的,只是
Objective-C不支持。笔者经过查阅,发现很多现代语言都支持协程。比如Python以及swift,甚至C语言也是支持协程的。
协程的作用其实在coobjc介绍文章中有提及,是为了优化iOS中的异步操作。解决了如下问题:
- "嵌套地狱"
- 错误处理复杂和冗长
- 容易忘记调用 completion handler
- 条件执行变得很困难
- 从互相独立的调用中组合返回结果变得极其困难
- 在错误的线程中继续执行
- 难以定位原因的多线程崩溃
- 锁和信号量滥用带来的卡顿、卡死
听起来是有点强大,最明显的好处是可以简化代码;并且在coobjc介绍文章也说道,性能也有所保障:当线程的数量级大于1000以上时,coobjc的优势就会非常明显。为了证明文章的结论,我们就来运行一下coobjc源码好了。
这里下载coobjc源码。
发现目录结构如下:
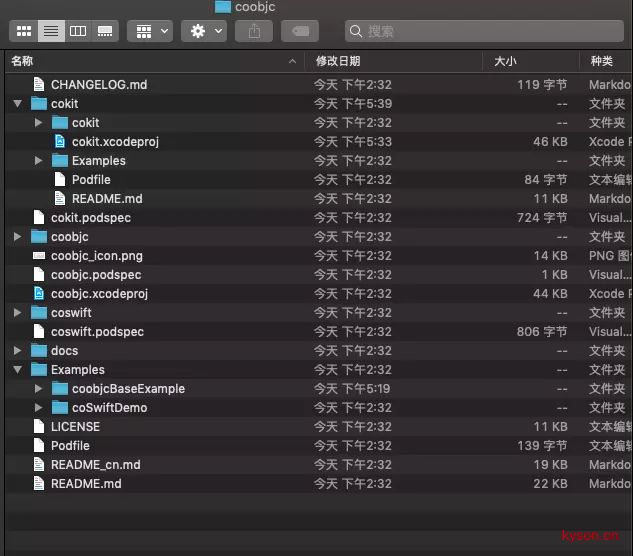
从目录结构看还是比较清晰的,根据coobjc介绍文章中提到的,coobjc不但提供了基础的异步操作还提供了基于UIKit的封装。目录中
-
cokit及其子目录提供的是基于UIKit层的coobjc封装 -
coobjc目录是coobjc的Objective-C版实现的源代码 -
coswift目录是coobjc的Swift版实现的源代码 -
Example下有两个目录,一个是Objective-C的实现,一个是Swift版的实现的Demo
我们先分析一下coobjcBaseExample工程:
打开项目,pod update一下即可运行,运行结果如下:

可以看到是个简单的列表页。
Tips
打开podfile可以发现里面有库coobjc以外,还有Specta、Expecta以及OCMock。这三个库这里不多做介绍了,大家只需要知道这是用于单元测试的。
我们先看一下这个列表的实现逻辑是什么样的。我们不难定位到页面位于KMDiscoverListViewController中,其网络请求(这里是电影列表)代码如下:
- (void)requestMovies
{
co_launch(^{
NSArray *dataArray = [[KMDiscoverSource discoverSource] getDiscoverList:@"1"];
[self.refreshControl endRefreshing];
if (dataArray != nil)
{
[self processData:dataArray];
}
else
{
[self.networkLoadingViewController showErrorView];
}
});
}
这里很容易理解代码
NSArray *dataArray = [[KMDiscoverSource discoverSource] getDiscoverList:@"1"];
是请求网络数据的,其实现如下:
- (NSArray*)getDiscoverList:(NSString *)pageLimit;
{
NSString *url = [NSString stringWithFormat:@"%@&page=%@", [self prepareUrl], pageLimit];
id json = [[DataService sharedInstance] requestJSONWithURL:url];
NSDictionary* infosDictionary = [self dictionaryFromResponseObject:json jsonPatternFile:@"KMDiscoverSourceJsonPattern.json"];
return [self processResponseObject:infosDictionary];
}
以上代码也能猜出,
id json = [[DataService sharedInstance] requestJSONWithURL:url];
这一行是做了网络请求,但是我们再点击进入类DataService看requestJSONWithURL方法的实现的时候,发现已经看不懂了:
- (id)requestJSONWithURL:(NSString*)url CO_ASYNC{
SURE_ASYNC
return await([self.jsonActor sendMessage:url]);
}
好吧。既然看不懂了,我们就从头开始学习,协程的含义以及使用。继而对coobjc源码进行分析。
协程入门
coobjc介绍文章中有提到
- 第一种:利用
glibc的ucontext组件(云风的库)。 - 第二种:使用汇编代码来切换上下文(实现C协程),原理同
ucontext。 - 第三种:利用C语言语法
switch-case的奇淫技巧来实现(Protothreads)。 - 第四种:利用了 C 语言的
setjmp和longjmp。 - 第五种:利用编译器支持语法糖。
经过筛选最终选择了第二种。那我们来一个个分析,为什么coobjc摒弃了其他的方式。
首先我们看第一种,coobjc介绍文章中提到ucontext在iOS中被废弃了,那如果不废弃,我们如何去使用ucontext呢?如下的一个Demo可以解释一下ucontext的用法:
#include
#include
#include
int main(int argc, const char *argv[]){
ucontext_t context;
getcontext(&context);
puts("Hello world");
sleep(1);
setcontext(&context);
return 0;
}
注:示例代码来自维基百科.
保存上述代码到example.c,执行编译命令:
gcc example.c -o example
想想程序运行的结果会是什么样?
kysonzhu@ubuntu:~$ ./example
Hello world
Hello world
Hello world
Hello world
Hello world
Hello world
^C
kysonzhu@ubuntu:~$
上面是程序执行的部分输出,不知道是否和你想得一样呢?我们可以看到,程序在输出第一个“Hello world"后并没有退出程序,而是持续不断的输出“Hello world”。其实是程序通过getcontext先保存了一个上下文,然后输出“Hello world”,在通过setcontext恢复到getcontext的地方,重新执行代码,所以导致程序不断的输出“Hello world”,在我这个菜鸟的眼里,这简直就是一个神奇的跳转。那么问题来了,ucontext到底是什么?
这里笔者不多做介绍了,推荐一篇文章,讲的比较详细:ucontext-人人都可以实现的简单协程库
这里我们只需要知道,所谓coobjc介绍文章中提到的使用汇编语言模拟ucontext,其实就是模拟的上面例子中的setcontext及getcontext等函数。为了证明笔者的猜想,笔者打开了coobjc源码库,发现里面的唯一的汇编文件coroutine_context.s
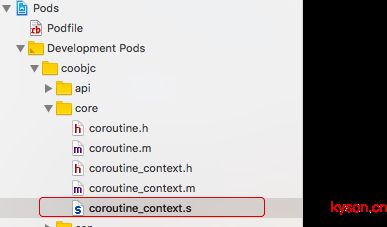
查看该文件,发现了这么几个函数:
- _coroutine_getcontext
- _coroutine_begin
- _coroutine_setcontext
果然验证了笔者的想法。这三个方法被暴露在文件coroutine_context.h中,供后序调用:
extern int coroutine_getcontext (coroutine_ucontext_t *__ucp);
extern int coroutine_setcontext (coroutine_ucontext_t *__ucp);
extern int coroutine_begin (coroutine_ucontext_t *__ucp);
接下来说另外一个函数
int setcontext(const ucontext_t *cut)
该函数是设置当前的上下文为cut,setcontext的上下文cut应该通过getcontext或者makecontext取得,如果调用成功则不返回。如果上下文是通过调用getcontext()取得,程序会继续执行这个调用。如果上下文是通过调用makecontext取得,程序会调用makecontext函数的第二个参数指向的函数,如果func函数返回,则恢复makecontext第一个参数指向的上下文第一个参数指向的上下文context_t中指向的uc_link.如果uc_link为NULL,则线程退出。
我们画个表类比一下ucontext和coobjc的函数:
| ucontext | coobjc | 含义 |
|---|---|---|
| setcontext | coroutine_setcontext | 设置协程上下文 |
| getcontext | coroutine_getcontext | 获取协程上下文 |
| makecontext | coroutine_create | 创建一个协程上下文 |
这么一来,我们之前的程序可以改写成如下:
#import
int main(int argc, const char *argv[]) {
coroutine_ucontext_t context;
coroutine_getcontext(&context);
puts("Hello world");
sleep(1);
coroutine_setcontext(&context);
return 0;
}
返回的结果仍然不变,一直打印“hello world”。
深入协程
(1)目录分析

上图是
coobjc的目录结构,其中
-
core目录提供了核心的协程函数 -
api目录是coobjc基于Objective-C的封装 -
csp,目录从库libtask引入,提供了一些链式操作 -
objc提供了coobjc对象声明周期管理的一些类
下面的文章,笔者会先从核心的core目录开始研究,后面的大家理解起来也就不复杂了。
(2)协程的构成
上面我们只简单的介绍了coobjc,也了解到coobjc基本都是参考了ucontext。那下面的例子中,笔者尽可能先介绍ucontext,然后再应用到coobjc对应的方法中。
我们继续讨论上文提到的几个函数,并说明一下其作用:
int getcontext(ucontext_t *uctp)
这个方法是,获取当前上下文,并将上下文设置到uctp中,uctp是个上下文结构体,其定义如下:
_STRUCT_UCONTEXT
{
int uc_onstack;
__darwin_sigset_t uc_sigmask; /* signal mask used by this context */
_STRUCT_SIGALTSTACK uc_stack; /* stack used by this context */
_STRUCT_UCONTEXT *uc_link; /* pointer to resuming context */
__darwin_size_t uc_mcsize; /* size of the machine context passed in */
_STRUCT_MCONTEXT *uc_mcontext; /* pointer to machine specific context */
#ifdef _XOPEN_SOURCE
_STRUCT_MCONTEXT __mcontext_data;
#endif /* _XOPEN_SOURCE */
};
/* user context */
typedef _STRUCT_UCONTEXT ucontext_t; /* [???] user context */
以上是ucontext的数据结构,其内部的几个属性介绍一下:
当当前上下文(如使用makecontext创建的上下文)运行终止时系统会恢复uc_link指向的上下文;uc_sigmask为该上下文中的阻塞信号集合;uc_stack为该上下文中使用的栈;uc_mcontext保存的上下文的特定机器表示,包括调用线程的特定寄存器等。其实还蛮好理解的,ucontext其实就存放一些必要的数据,这些数据还包括拯救成功或者失败的情况需要的数据。
相比较而言,coobjc的定义和ucontext有一定区别:
/**
The structure store coroutine's context data.
*/
struct coroutine {
coroutine_func entry; // Process entry.
void *userdata; // Userdata.
coroutine_func userdata_dispose; // Userdata's dispose action.
void *context; // Coroutine's Call stack data.
void *pre_context; // Coroutine's source process's Call stack data.
int status; // Coroutine's running status.
uint32_t stack_size; // Coroutine's stack size
void *stack_memory; // Coroutine's stack memory address.
void *stack_top; // Coroutine's stack top address.
struct coroutine_scheduler *scheduler; // The pointer to the scheduler.
int8_t is_scheduler; // The coroutine is a scheduler.
struct coroutine *prev;
struct coroutine *next;
void *autoreleasepage; // If enable autorelease, the custom autoreleasepage.
bool is_cancelled; // The coroutine is cancelled
};
typedef struct coroutine coroutine_t;
其中
struct coroutine *prev;
struct coroutine *next;
表明其是一个链表结构。
既然是链表,那么就会有添加元素,以及删除某个元素的方法,果然我们在coroutine.m中发现了对应的链表操作方法:
// add routine to the queue
void scheduler_add_coroutine(coroutine_list_t *l, coroutine_t *t) {
if(l->tail) {
l->tail->next = t;
t->prev = l->tail;
} else {
l->head = t;
t->prev = nil;
}
l->tail = t;
t->next = nil;
}
// delete routine from the queue
void scheduler_delete_coroutine(coroutine_list_t *l, coroutine_t *t) {
if(t->prev) {
t->prev->next = t->next;
} else {
l->head = t->next;
}
if(t->next) {
t->next->prev = t->prev;
} else {
l->tail = t->prev;
}
}
其中coroutine_list_t是为了标识链表的头尾节点:
/**
Define the linked list of scheduler's queue.
*/
struct coroutine_list {
coroutine_t *head;
coroutine_t *tail;
};
typedef struct coroutine_list coroutine_list_t;
为了管理所有的协程状态,还设置了一个调度器:
/**
Define the scheduler.
One thread own one scheduler, all coroutine run this thread shares it.
*/
struct coroutine_scheduler {
coroutine_t *main_coroutine;
coroutine_t *running_coroutine;
coroutine_list_t coroutine_queue;
};
typedef struct coroutine_scheduler coroutine_scheduler_t;
看命名就大概能猜到,main_coroutine中包含了主协程(可能是即将设置数据的协程,或者即将使用的协程);running_coroutine是当前正在运行的协程。
(3)协程的操作
协程拥有和线程一样类似的操作,例如创建,启动,出让控制权,恢复,以及死亡。对应的,我们在coroutine.h看到了如下的几个函数声明:
//关闭一个协程如果它已经死亡
void coroutine_close_ifdead(coroutine_t *co);
//添加协程到调度器,并且立刻启动
void coroutine_resume(coroutine_t *co);
//添加协程到调度器
void coroutine_add(coroutine_t *co);
//出让控制权
void coroutine_yield(coroutine_t *co);
为了更好的控制各个操作中的数据,coobjc还提供了以下两个方法:
void coroutine_setuserdata(coroutine_t *co, void *userdata, coroutine_func userdata_dispose);
void *coroutine_getuserdata(coroutine_t *co);
至此,coobjc的核心代码都分析完成了。
(3)协程的Objective-C层面的封装
我们再次回到文章开头的例子- (void)requestMovies方法的实现中,第一步就是调用一个co_launch()的方法,这个方法最终会调用到
+ (instancetype)coroutineWithBlock:(void(^)(void))block onQueue:(dispatch_queue_t _Nullable)queue stackSize:(NSUInteger)stackSize {
if (queue == NULL) {
queue = co_get_current_queue();
}
if (queue == NULL) {
return nil;
}
COCoroutine *coObj = [[self alloc] initWithBlock:block onQueue:queue];
coObj.queue = queue;
coroutine_t *co = coroutine_create((void (*)(void *))co_exec);
if (stackSize > 0 && stackSize < 1024*1024) { // Max 1M
co->stack_size = (uint32_t)((stackSize % 16384 > 0) ? ((stackSize/16384 + 1) * 16384) : stackSize/16384); // Align with 16kb
}
coObj.co = co;
coroutine_setuserdata(co, (__bridge_retained void *)coObj, co_obj_dispose);
return coObj;
}
- (void)resumeNow {
[self performBlockOnQueue:^{
if (self.isResume) {
return;
}
self.isResume = YES;
coroutine_resume(self.co);
}];
}
这两个方法。其实代码已经很容易理解了,第一个方法是创建一个协程,第二个是启动。
最后我们在说一下文章开头提到的await方法,其实最终就交给chan去处理了:
- (COActorCompletable *)sendMessage:(id)message {
COActorCompletable *completable = [COActorCompletable promise];
dispatch_async(self.queue, ^{
COActorMessage *actorMessage = [[COActorMessage alloc] initWithType:message completable:completable];
[self.messageChan send_nonblock:actorMessage];
});
return completable;
}
所有的操作虽然丢到了同一个线程中,但其实最终是通过chan来调度了。关于chan就不在本文讨论范围了,后面如果有时间,笔者会再进行对chan的分析。
总结
本文介绍了协程的概念,通过对比ucontext以及coobjc来说明协程的用法,并分析了coobjc的源代码,希望对大家有所帮助。
扩展阅读
iOS单元测试:Specta + Expecta + OCMock + OHHTTPStubs + KIF
我所理解的ucontext族函数
一个“蝇量级” C 语言协程库
协程(Coroutine)并不是真正的多线程
ucontext-人人都可以实现的简单协程库
协程分析之context上下文切换
广告
我的首款个人开发的APP壁纸宝贝上线了,欢迎大家下载。
