-
spring的事务和数据库的事务的区别,各自实现方式。
本质上其实是同一个概念,spring的事务是对数据库的事务的封装,最后本质的实现还是在数据库,假如数据库不支持事务的话,spring的事务是没有作用的.数据库的事务说简单就只有开启,回滚和关闭,spring对数据库事务的包装,原理就是拿一个数据连接,根据spring的事务配置,操作这个数据连接对数据库进行事务开启,回滚或关闭操作.但是spring除了实现这些,还配合spring的传播行为对事务进行了更广泛的管理.其实这里还有个重要的点,那就是事务中涉及的隔离级别,以及spring如何对数据库的隔离级别进行封装.
-
事务的传播行为和隔离级别,mysql的默认隔离级别(可重复读)
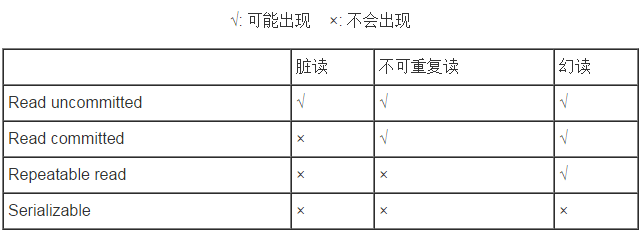
MySQL默认的隔离级别是Repeatable Read(可重读)
https://www.cnblogs.com/fidelQuan/p/4549068.html
-
spring的IOC和AOP思想
IOC也称控制反转,其实是和依赖注入的含义是一样的,就是把原先控制代码对象的生产由代码转换到IOC容器中去实现。作用是为了解耦,降低类之间的耦合度,其设计思想就是设计模式的工厂模式,我们并不需要知道其生产的具体过程,我们只要其产出的对象即可。其工作流程就是:在Spring容器启动的时候,Spring会把你在application.xml中配置好的bean都初始化,在你需要调用的时候,把已经初始化的bean分配给你要调用这些bean的类,而不用去创建一个对象的实例。
AOP可以说是对OOP的补充和完善,当我们需要为分散的对象引入公共行为的时候,OOP就显得无力,OOP不能解决从左到右的关系,例如日志,权限,事务之类的代码往往分散于很多代码中,在OOP设计中,这导致了大量代码的重复,我们可以把这些代码封装成一个切面,然后注入到目标对象中
-
jdk代理和cglib第三方代理(说出对接口代理和子类继承的区别)
JDK动态代理:
- 能够继承静态代理的全部优点.并且能够实现代码的复用.
- 动态代理可以处理一类业务.只要满足条件 都可以通过代理对象进行处理.
- 动态代理的灵活性不强.
- JDK 的动态代理要求代理者必须实现接口, , 否则不能生成代理对象
java.lang.ClassCastException:
com.sun.proxy.$Proxy0 cannot be cast to com.example.proxy.RealSubject
Cglib动态代理:
- 不管有无接口都可以创建代理对象.
- cglib创建的代理对象是目标对象的子类.
使用spring的AOP代理对象生成策略:
- 在spring中默认条件下如果目标对象有接口,则使用JDK的动态代理.如果目标对象没有接口则默认使用cgLib动态代理.
- 当从容器中获取对象时,如果获取的对象满足切入点表达式.那么就会为其创
建代理对象.代理对象指定方法就会执行与切入点绑定的通知方法.
-
为什么索引不能随便用,什么时候用(什么时候失效,什么时候最高效)
为什么索引不能随便用?因为:
- 数据的变更(增,删,改)都需要修订索引,索引存在额外的维护成本
- 查找翻阅索引系统需要消耗时间,索引存在额外的访问成本
- 这个索引系统需要一个地方来存放,索引存在额外的空间成本
在数据量大,且查询需求比较多的情况下使用索引
在查询条件中都添加索引,过滤效果越好的字段需要更靠前。所以为了保证索引的高效性,字段的顺序对组合索引效率有至关重要的作用。
索引什么时候失效
- 当查询条件中有or
- like查询是以%开头
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
https://blog.csdn.net/colin_liu2009/article/details/7301089
-
MySQL数据库引擎
Innodb引擎
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级别这篇文章。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
MyIASM引擎
MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
两种引擎的选择
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,关于这个问题我会在下文中讲到。大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些,但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
-
redis的理解
- Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
- 再说一下IO,Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
- Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
- 另外,数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
- 还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
- redis可以存储list,set,zset,hash数据类型
-
JVM的理解(从内存划分说到了GC算法、分代思想,CMS和G1 collector,到类加载模型,tomcat的非双亲委派、线程上下文加载器,到JVM调优的策略,gc参数设置策略,如何找死锁,读快照,发现内存泄漏等等吧)
------------稍后总结
内存模型:
程序计数器 ,java虚拟机栈,java堆,本地方法栈,方法区
垃圾回收
新生代有:serial,parNew,parallel
老年代有:CMS,parallel Old,Serial Old
G1
分代及回收算法
serial,parNew,parallel 复制 算法
parallelOld,serialOld 标记-整理 算法
CMS 标记-清除 算法
G1 复制,标记-整理 算法
哪些作为gc root
1.虚拟机栈(栈帧中的本地变量表)中引用的对象;
2.方法区中的类静态属性引用的对象;
3.方法区中常量引用的对象;
4.本地方法栈中JNI(即一般说的Native方法)中引用的对象
类加载机制和双亲委派模型和几个加载器
https://blog.csdn.net/javazejian/article/details/73413292
tomcat类加载有什么不同,说加载顺序并不是双亲模型
-
JUC
ReentrantLock重入锁
https://www.jianshu.com/p/4e54802c965f
ReentrantReadWriteLock读写锁
Semaphore信号量
CountDownLatch计数器
-
线程进程区别
- 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
- 线程的划分尺度小于进程,使得多线程程序的并发性高。
- 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
- 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
- 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。
-
并发注意什么,线程实现同步的方式
- 使用synchronized关键字修饰的方法
- 使用同步代码块
synchronized(object){
}
- 使用重入锁实现线程同步
class Bank {
private int account = 100;
//需要声明这个锁
private Lock lock = new ReentrantLock();
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
lock.lock();
try{
account += money;
}finally{
lock.unlock();
}
}
}
- 使用局部变量实现线程同步
- 使用阻塞队列LinkedBlockingQueue实现线程同步
public class BlockingSynchronizedThread {
/**
* 定义一个阻塞队列用来存储生产出来的商品
*/
private LinkedBlockingQueue queue = new LinkedBlockingQueue();
/**
* 定义生产商品个数
*/
private static final int size = 10;
/**
* 定义启动线程的标志,为0时,启动生产商品的线程;为1时,启动消费商品的线程
*/
private int flag = 0;
private class LinkBlockThread implements Runnable {
@Override
public void run() {
int new_flag = flag++;
System.out.println("启动线程 " + new_flag);
if (new_flag == 0) {
for (int i = 0; i < size; i++) {
int b = new Random().nextInt(255);
System.out.println("生产商品:" + b + "号");
try {
queue.put(b);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
for (int i = 0; i < size / 2; i++) {
try {
int n = queue.take();
System.out.println("消费者买去了" + n + "号商品");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("仓库中还有商品:" + queue.size() + "个");
try {
Thread.sleep(100);
} catch (Exception e) {
// TODO: handle exception
}
}
}
}
}
public static void main(String[] args) {
BlockingSynchronizedThread bst = new BlockingSynchronizedThread();
LinkBlockThread lbt = bst.new LinkBlockThread();
Thread thread1 = new Thread(lbt);
Thread thread2 = new Thread(lbt);
thread1.start();
thread2.start();
}
}
- 使用原子变量实现线程同步->AtomicInteger
class Bank {
private AtomicInteger account = new AtomicInteger(100);
public AtomicInteger getAccount() {
return account;
}
public void save(int money) {
account.addAndGet(money);
}
}
-
死锁
public class DeadLock {
public static String obj1 = "obj1";
public static String obj2 = "obj2";
public static void main(String[] args){
Thread a = new Thread(new Lock1());
//Thread b = new Thread(new Lock2());
a.start();
//b.start();
}
}
class Lock1 implements Runnable{
@Override
public void run(){
try{
System.out.println("Lock1 running");
while(true){
synchronized(DeadLock.obj1){
System.out.println("Lock1 lock obj1");
Thread.sleep(3000);
synchronized(DeadLock.obj2){
System.out.println("Lock1 lock obj2");
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
class Lock2 implements Runnable{
@Override
public void run(){
try{
System.out.println("Lock2 running");
while(true){
synchronized(DeadLock.obj2){
System.out.println("Lock2 lock obj2");
Thread.sleep(3000);
synchronized(DeadLock.obj1){
System.out.println("Lock2 lock obj1");
}
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
-
单链表逆置
void reverse(Node head) {
Node p, s, t;
p = head;
s = head.next;
head.next = null;
while (s.next != null) {
t = s.next;
s.next = p;
p = s;
s = t;
}
s.next = p;
}
-
单例模式
public class Singleton {
private static Singleton singleton;
private Singleton() {
}
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
-
算法:时间复杂度O(1),删除执行链表结点,做分析
/*
* Solution:由于我们知道当前的要删除节点的指针,那么就可以不用从头扫描整个链表
* 而是将下个点的值复制到要删除的节点中,然后将下一个节点删掉。
*/
public void deleteNode(ListNode node) {
if(node.next == null) {
return;
}
ListNode nextNode = node.next;
node.val = nextNode.val;
node.next = nextNode.next;
//去除nextNode的引用关系,防止GC不回收
nextNode.next = null;
}
· ######排序
//选择
public void xuanze(int[] nums) {
int N = nums.length;
for (int i = 0; i < N; i++) {
int min = i;
for (int j = i + 1; j < N; j++) {
if (nums[j] < nums[min]) {
min = j;
}
}
int swap = nums[i];
nums[i] = nums[min];
nums[min] = swap;
}
}
//冒泡
public void maopao(int[] nums) {
int N = nums.length;
boolean hasSorted = false;
for (int i = 0; i < N && !hasSorted; i++) {
hasSorted = true;
for (int j = 0; j < N - i - 1; j++) {
if ((nums[j + 1] < nums[j])) {
hasSorted = false;
int swap = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = swap;
}
}
}
}
//插入
public void charu(int[] nums) {
int N = nums.length;
for (int i = 1; i < N; i++) {
for (int j = i; j > 0 && nums[j] < nums[j - 1]; j--) {
int swap = nums[j];
nums[j] = nums[j - 1];
nums[j - 1] = swap;
}
}
}
//快速排序
public void quickSort(int[] a, int low, int high) {
//找到递归算法的出口
if (low > high) {
return;
}
//存
int i = low;
int j = high;
//key
int key = a[low];
//完成一趟排序
while (i < j) {
//从右往左找到第一个小于key的数
while (i < j && a[j] > key) {
j--;
}
//从左往右找到第一个大于key的数
while (i < j && a[i] <= key) {
i++;
}
//交换
if (i < j) {
int p = a[i];
a[i] = a[j];
a[j] = p;
}
}
// 调整key的位置
int p = a[i];
a[i] = a[low];
a[low] = p;
//对key左边的数快排
quickSort(a, low, i - 1);
//对key右边的数快排
quickSort(a, i + 1, high);
}
-
算法:二叉树的最长距离
int HeightOfBinaryTree(BinaryTreeNode pNode, int nMaxDistance) {
if (pNode == null){
return -1; //空节点的高度为-1
}
//递归
int nHeightOfLeftTree = HeightOfBinaryTree(pNode.m_pLeft, nMaxDistance) + 1; //左子树的的高度加1
int nHeightOfRightTree = HeightOfBinaryTree(pNode.m_pRight, nMaxDistance) + 1; //右子树的高度加1
int nDistance = nHeightOfLeftTree + nHeightOfRightTree; //距离等于左子树的高度加上右子树的高度+2
nMaxDistance = nMaxDistance > nDistance ? nMaxDistance : nDistance; //得到距离的最大值
return nHeightOfLeftTree > nHeightOfRightTree ? nHeightOfLeftTree : nHeightOfRightTree;
}
-
给定一个有序数组,如{1,2,3,4,5,6,7,8,9},我们将对这个数组进行选择,位置旋转未知。下面给出一个可能的旋转结果。如{4,5,6,7,8,9,1,2,3},我们可以理解为它从元素4位置开始旋转。之后给定一个指定的数字n,让我们从{4,5,6,7,8,9,1,2,3}这个数组中找出它的位置,要求时间复杂度尽可能的低。
public int search(int n, int[] array) {
int low = 0;
int high = array.length - 1;
while (low <= high) {
int middle = (low + high) / 2;
if (array[middle] == n) {
return middle;
}
//若中间的值大于左边第一个值,则左边是有序的
if (array[middle] > array[low]) {
if (n <= array[middle] && n >= array[low]) {
high = middle - 1;
} else {
low = middle + 1;
}
//反之,右边是有序的
} else {
if (n >= array[middle] && n <= array[high]) {
low = middle + 1;
} else {
high = middle - 1;
}
}
}
return -1;
}