本文用到的包为
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
from collections import defaultdict
from collections import Counter
from numpy import linalg as LA
import statsmodels.api as sm
import matplotlib.cm as cm
from datetime import datetime as dt
import sys
from os import listdir
from scipy.stats.stats import pearsonr
from matplotlib.dates import YearLocator
StackExchange(以下简称SE)是世界上最大的专业性问答社区之一。最早只有一个StackOverflow,后来慢慢发展出其他的问答社区,现在一共有一百多社区。在这里可以看到所有社区。

图1. StackExchange的一部分社区
[这个]问答给出了SE历史数据的下载地址。本文给出对SE数据的初步处理示例。
首先定义一些数据处理函数:
def dailyQA(site):
F = defaultdict(lambda:[0,0])
path='/Users/csid/Documents/bigdata/stackexchange/unzip/'
filename = path + site + '/Posts.xml'
with open(filename,'r') as f:
for line in f:
try:
label = line.split('PostTypeId=')[1][1:2]
day = line.split('CreationDate=')[1][1:11]
if label == '1':
F[day][0]+=1
if label == '2':
F[day][1]+=1
except:
pass
return F
#plot the monthly growth of sites in terms of Na and Nq
def plotMonth(site,ax,col):
M=defaultdict(lambda:np.array([0,0]))
f=F[site]
for i in f:
M[i[:7]]+=np.array(f[i])
ms=sorted(M.keys())[1:-1]
if len(ms)>3:
x,y = np.array([M[i] for i in ms]).T
mm=[dt.strptime(j,'%Y-%m') for j in ms]
#ax.vlines(mm[0], x[0], y[0],color=col,linestyle='-')
ax.fill_between(mm, x, y,color=col, alpha=0.1)
ax.plot(mm,x,color="white",linestyle='-',marker='',alpha=0.1)
ax.plot(mm,y,color="white",linestyle='-',marker='',alpha=0.1)
def plotMonthSpecial(site,ax,col):
M=defaultdict(lambda:np.array([0,0]))
f=F[site]
for i in f:
M[i[:7]]+=np.array(f[i])
ms=sorted(M.keys())[2:-1]
x,y = np.array([M[i] for i in ms]).T
mm=[dt.strptime(j,'%Y-%m') for j in ms]
ax.vlines(mm[0], x[0], y[0],color=col,linestyle='-')
ax.plot(mm,x,color=col,linestyle='-',marker='')
ax.plot(mm,y,color=col,linestyle='-',marker='')
通过下列代码得到每个社区每天新增的问题和答案数
path='/Users/csid/Documents/bigdata/stackexchange/unzip/'
sites = [ f for f in listdir(path) if f[-1]=='m']
F={}
for i in sites:
flushPrint(sites.index(i))
F[i] = dailyQA(i)
好的可视化,需要层次分明,所以在绘制各个社区问答数量增长曲线时,往往需要排序来决定绘制的先后叠加顺序。下列代码将各个社区按照总的问答数量排序。
# plot good sites at first then plot bad sites
S={}
for i in sites:
q,a=zip(*F[i].values())
S[i]=sum(q),sum(a)
rsites=[i for i,j in sorted(S.items(),key=lambda x:-x[1][0])]
然后就可以绘制图2了
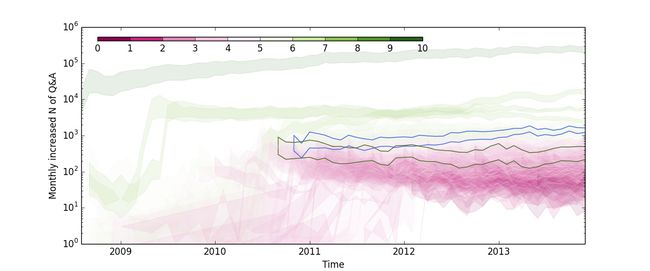
图1. StackExchange的一部分社区
每条带子是一个社区,上界是每月新增答案数,下界是每月新增问题数。一共有110个社区。颜色代表社区的问答总数(取对数再减去5)。我们还可以选择性地标示出某些社区,例如本图中标示出了物理类(蓝色)和烹调类(深绿色)两个社区。
绘制代码为
fig = plt.figure(figsize=(12, 5),facecolor='white')
ax = plt.subplot(111)
years = YearLocator()
cmap = cm.get_cmap('PiYG', 10)
for i in rsites:
c = int(np.log(S[i][0])-5)
plotMonth(i,ax,cmap(c))
plotMonthSpecial('physics.stackexchange.com',ax,'RoyalBlue')
plotMonthSpecial('cooking.stackexchange.com',ax,'DarkOliveGreen')
ax.set_yscale('log')
ax.set_ylim(1,10**6)
ax.set_xlabel('Time')
ax.set_ylabel('Monthly increased N of Q&A')
ax.xaxis.set_major_locator(years)
smm = plt.cm.ScalarMappable(cmap=cmap, norm=plt.Normalize(vmin=0, vmax=10))
smm._A = []
cbaxes = fig.add_axes([0.15, 0.85, 0.5, 0.015])
cbar = plt.colorbar(smm,cax=cbaxes,orientation='horizontal')
plt.show()
接下来,我们考虑使用节点到源和汇的流距离构造一个相空间,分析用户在这个相空间中游走的轨迹产生的角度熵(把在两个节点间的每一步跳跃合并到一个原点上,考察角度的分布)与社区可持续发展之间的关系。我们的假设是,用户游走的熵越大,说明用户越有创造性,对问答社区的长期发展也越有利。
首先要定义一系列函数
def userDailyAnswers(site):
C={}
filename = path + site + '/Posts.xml'
with open(filename,'r') as f:
for line in f:
try:
label = line.split('PostTypeId=')[1][1:2]
if label == '2':
date = line.split('CreationDate=')[1][1:11]
time = line.split('CreationDate=')[1][12:20]
author = int(line.split('OwnerUserId=')[1].split(r'"')[1])
questionID = int(line.split('ParentId=')[1].split(r'"')[1])
if date in C:
if author in C[date]:
C[date][author]+=[(time,questionID)]
else:
C[date][author]=[(time,questionID)]
else:
C[date]={author:[(time,questionID)]}
except:
pass
return C
# calculate entropy of path angles
def entropy(G,O,K,T):
angles=[]
for i,j in G.edges():
#wi = G[i][j]['weight']
dx,dy = np.array([O[j],K[j]])-np.array([O[i],K[i]])
dis = LA.norm(np.array([O[j],K[j]])-np.array([O[i],K[i]]))
if dy>=0:
angle = np.round(180*np.arccos(dx/dis)/np.pi,1)
else:
angle = 360-np.round(180*np.arccos(dx/dis)/np.pi,1)
angles.append(angle)
l = len(angles)
ps=np.array(Counter(angles).values())
ps=ps/float(ps.sum())
#ent = -(ps*np.log(ps)).sum()/np.log(l)
ent = -(ps*np.log(ps)).sum()
return ent
def getSiteFlowdata(site):
C=userDailyAnswers(site)
days=sorted(C.keys())
E=defaultdict(lambda:0)
n=0
maxuser=100
for day in days[len(days)/2:]:
d = C[day]
f = sorted(d.items(),key=lambda x:x[1])
for i,j in f:
if nr:
r=rr
plt.arrow(0, 0, dx, dy, head_width=0.05, head_length=0.1, fc='gray', ec='gray',alpha=0.1)
plt.arrow(0, 0, Dx/float(tr), Dy/float(tr), head_width=0.1,
head_length=0.2, fc='red', ec='red',alpha=0.7)
lim=2
plt.xlim(-lim,lim)
plt.ylim(-lim,lim)
接着就可以比较物理和烹调这两个规模相近的社区,取其总天数一半时的一百个用户产生的游走轨迹的角度熵
i='physics.stackexchange.com'
j='cooking.stackexchange.com'
G1,O1,K1,T1=getSiteFlowdata(i)
G2,O2,K2,T2=getSiteFlowdata(j)
# okplot demo
fig = plt.figure(figsize=(12, 6),facecolor='white')
ax = plt.subplot(121)
okplot(G1,O1,K1,T1)
ax = plt.subplot(122)
okplot(G2,O2,K2,T2)
plt.tight_layout()
plt.show()
得到下图
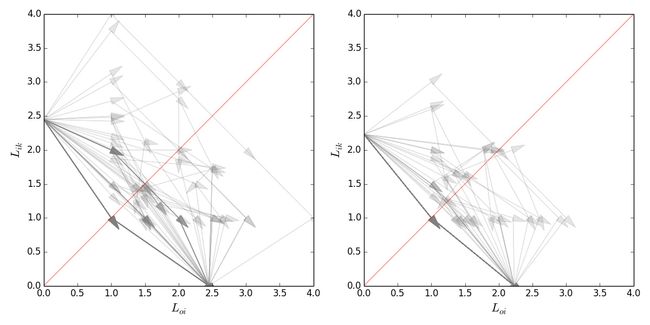
物理和烹调社区一百个用户的游走轨迹,横轴是问题节点离源的距离,纵轴是其到汇的距离。问题节点在此图中不显示,只以箭头显示用户在节点之间的跳跃。
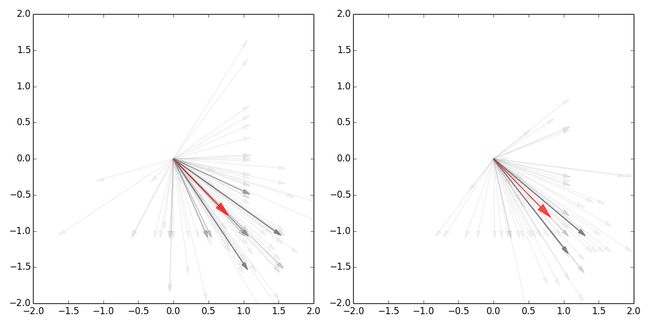
把所有用户的所有一步跳跃矢量合并到一个原点上以计算角度熵,红色代表矢量合并的结果。矢量合并的结果一定是一单位长的箭头以45度角指向右下方,因为所有用户的所有游走都是从源开始,到汇结束。
可以通过下列代码
entropy(G1,O1,K1,T1),entropy(G2,O2,K2,T2)
来计算得到两个社区的熵分别为3.47和2.67。物理社区的熵更大,实际发展也更好,验证了我们的假设。
接下来,我们考察所有社区在发展一半时的一百个用户记录,以此预测其最终发展规模
# construct network and calculate path entropy
D={}
for site in sites:
if site=='ebooks.stackexchange.com' or site=='stackoverflow.com':
continue
flushPrint(sites.index(site))
C=userDailyAnswers(site)
days=sorted(C.keys())
E=defaultdict(lambda:0)
n=0
maxuser=100
for day in days[len(days)/2:]:
d = C[day]
f = sorted(d.items(),key=lambda x:x[1])
for i,j in f:
if n得到下图
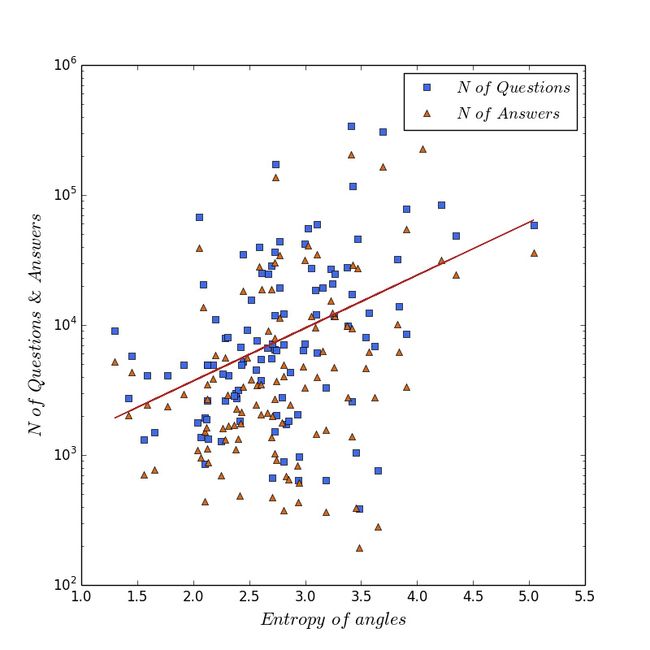
角度熵与社区规模之间的相关
考察其皮尔逊相关系数
pearsonr(l,np.log(q))
得到0.42,p-value小于0.001。