
主节点(master)复制到从节点(slave)
[zhangting@master hadoop]$scp -r hadoop2.7.4 zhangting@slave:~/
注意:因为之前已经配置了免密钥登录,这里可以直接远程复制
但是实验没成功
启动集群
1配置Hadoop启动的系统环境变量
该节的配置需要同时在两个节点(master和slave)上进行操作,操作命令如下:
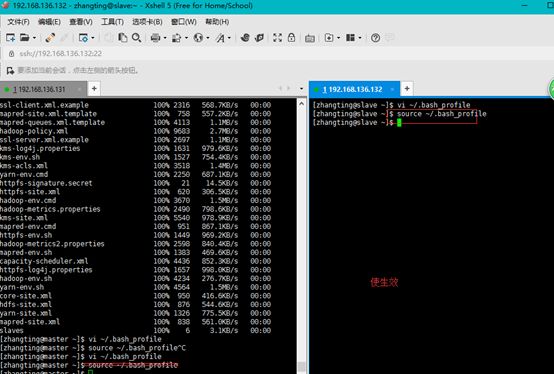
[zhangting@master ~]$ vi~/.bash_profile
#HADOOP
exportHADOOP_HOME=/home/zhangting/hadoop2.7.4
exportPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

[zhangting@master ~]$source ~/.bash_profile
2.创建数据目录
同样需要在主 子节点上增加
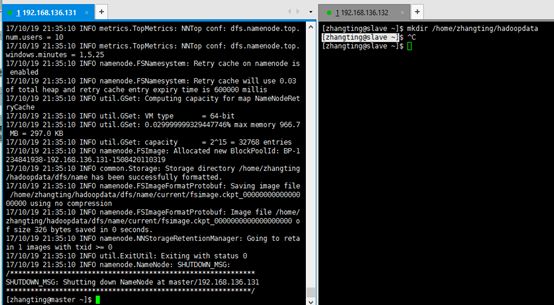
[zhangting@master ~]$ mkdir/home/zhangting/hadoopdata
[zhangting@master ~]$

3.启动Hadoop集群
1、格式化文件系统(只能格式化一次)
格式化命令如下,该操作需要在master节点上执行:
[zhangting@master~]$ hdfs namenode -format
2、启动hadoop
使用start-all.sh启动Hadoop集群,首先进入Hadoop安装主目录,然后执行启动命令:
[zhangting@master~]$ cd hadoop2.7.4/
[[email protected]]$ sbin/start-all.sh
执行命令后,提示出入yes/no时,输入yes。

3、查看进程是否启动

浏览器验证:

