接下来会详细分析bfs的源码,主要是bfs代码的分析资料在网络上几乎没有,不像其他诸如leveldb/rocksdb等有较多的参考资料;还有就是之前分析的raft实现并没有结合相关的业务场景去思考更多的可能,即具体使用;当然有具体的开源如etcd/tikv/pika使用raft实现高可用;bfs中其他可学习的设计思路,当然如ceph/leveldb/rocksdb/redis等知名开源都挺值得学习和分析的。
在这里可clone相关的代码bfs,为什么使用bfs呢:
“传统的分布式文件系统(如HDFS)Namenode是一个单点,容量和吞吐量都不可以扩展,同时使用外部的日志同步工具(如QJM、ZooKeeper)failover时间是分钟级的。 BFS主要从扩展性和持续可用两个方面做了改进,采用分布式的NameServer,多NameServer之间使用内置的Raft协议做日志同步,保证failover时,新主一定有最新的状态不需要额外日志同步,解决了扩展性和可用性问题。”
引用bfs的特点:
高可用,多台NameServer之间自动选主,并通过Raft协议进行同步,当主宕机后,剩余NameServer会自动选出新主,不影响集群的可用性;
高吞吐,低延时 ChunkServer写流程异步化,最大化存储介质IO吞吐,全局负载均衡,支持链式写与扇出写模式,遇到慢节点时自动规避;
高可靠,ChunkServer宕机后快速进行副本恢复,根据存货副本数区别恢复优先级,支持自动将不同副本进行多机房部署,保证数据不丢失;
水平扩展,支持两地三机房,1万+台机器管理,更多的可以参考后面连接。
架构如下:

不知道阅读本文的读者是否使用过或了解过hdfs呢?在本地执行一些相关的命令即可看到结果?这里附上一张架构图对比,具体的不再详述:
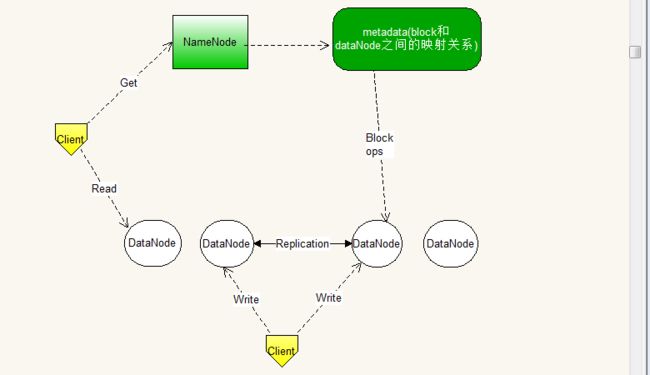
下面会从bfs_client.cc源代码以"ls命令"简单介绍下流程,后续文章会详细分析各模块和设计。
"ls命令",在linux类似的系统上使用"ls -l"时会列出本地文件的一般信息,那如果文件不在本地则需要通过网络处理,就好像文件在本地一样,故在收到响应后会格式化相关的数据,大致流程如下:
main--->OpenFileSystem--->BfsList--->ListDirectory--->format
其中会通过sdk创建一个bfs对象,代码路径在src/sdk/bfs.h中,抽象基类class FS,继承类class FSImpl:
26 class FSImpl : public FS {
27 public:
31 bool ConnectNameServer(const char* nameserver);
33 int32_t ListDirectory(const char* path, BfsFileInfo** filelist, int *num);
60 private:
61 RpcClient* rpc_client_;
62 NameServerClient* nameserver_client_;
63 //NameServer_Stub* nameserver_;
64 std::vector nameserver_addresses_;
65 int32_t leader_nameserver_idx_;
66 //std::string nameserver_address_;
67 std::string local_host_name_;
68 ThreadPool* thread_pool_;
69 };
然后连接nameserver:
576 bool FS::OpenFileSystem(const char* nameserver, FS** fs, const FSOptions&) {
577 FSImpl* impl = new FSImpl;
578 if (!impl->ConnectNameServer(nameserver)) {
579 *fs = NULL;
580 return false;
581 }
582 *fs = impl;
583 return true;
584 }
88 bool FSImpl::ConnectNameServer(const char* nameserver) {
89 std::string nameserver_nodes = FLAGS_nameserver_nodes;
90 if (nameserver != NULL) {
91 nameserver_nodes = std::string(nameserver);
92 }
93 rpc_client_ = new RpcClient(); //sofa-pbrpc client
94 nameserver_client_ = new NameServerClient(rpc_client_, nameserver_nodes);
95 return true;
96 }
其中用到sofa-pbrpc模块,暂且不分析;
16 NameServerClient::NameServerClient(RpcClient* rpc_client, const std::string& nameserver_nodes)
17 : rpc_client_(rpc_client), leader_id_(0) {
18 common::SplitString(nameserver_nodes, ",", &nameserver_nodes_);
19 stubs_.resize(nameserver_nodes_.size());
20 for (uint32_t i = 0; i < nameserver_nodes_.size(); i++) {
21 rpc_client_->GetStub(nameserver_nodes_[i], &stubs_[i]); //定义 channel,代表通讯通道,每个服务器地址对应一个 channel
22 }
23 }
然后通过fs调用ListDirectory,其中会调用bool ret = nameserver_client_->SendRequest(&NameServer_Stub::ListDirectory, &request, &response, 60, 1);请求nameserver:
31 template
32 bool SendRequest(void(NameServer_Stub::*func)(google::protobuf::RpcController*,
33 const Request*, Response*, Callback*),
34 const Request* request, Response* response,
35 int32_t rpc_timeout, int retry_times = 1) {
36 bool ret = false;
37 for (uint32_t i = 0; i < stubs_.size(); i++) {
38 int ns_id = leader_id_;
39 ret = rpc_client_->SendRequest(stubs_[ns_id], func, request, response,
40 rpc_timeout, retry_times);
41 if (ret && response->status() != kIsFollower) {
42 // LOG(DEBUG, "Send rpc to %d %s return %s",
43 // leader_id_, nameserver_nodes_[leader_id_].c_str(),
44 // StatusCode_Name(response->status()).c_str());
45 return true;
46 }
47 MutexLock lock(&mu_);
48 if (ns_id == leader_id_) {
49 leader_id_ = (leader_id_ + 1) % stubs_.size();
50 }
51 //LOG(INFO, "Try next nameserver %d %s",
52 // leader_id_, nameserver_nodes_[leader_id_].c_str());
53 }
54 return ret;
55 }
49 template
50 bool SendRequest(Stub* stub, void(Stub::*func)(
51 google::protobuf::RpcController*,
52 const Request*, Response*, Callback*),
53 const Request* request, Response* response,
54 int32_t rpc_timeout, int retry_times) {
56 sofa::pbrpc::RpcController controller;
57 controller.SetTimeout(rpc_timeout * 1000L);
58 for (int32_t retry = 0; retry < retry_times; ++retry) {
59 (stub->*func)(&controller, request, response, NULL);
60 if (controller.Failed()) {
61 if (retry < retry_times - 1) {
62 LOG(DEBUG, "Send failed, retry ...");
63 usleep(1000000);
64 } else {
65 LOG(WARNING, "SendRequest to %s fail: %s\n",
66 controller.RemoteAddress().c_str(), controller.ErrorText().c_str());
67 }
68 } else {
69 return true;
70 }
71 controller.Reset();
72 }
73 return false;
74 }
即调用NameServerImpl::ListDirectory接口:
712 void NameServerImpl::ListDirectory(::google::protobuf::RpcController* controller,
713 const ListDirectoryRequest* request,
714 ListDirectoryResponse* response,
715 ::google::protobuf::Closure* done) {
716 if (!is_leader_) {
717 response->set_status(kIsFollower);
718 done->Run();
719 return;
720 }
721 g_list_dir.Inc();
722 response->set_sequence_id(request->sequence_id());
723 std::string path = NameSpace::NormalizePath(request->path());
724 common::timer::AutoTimer at(100, "ListDirectory", path.c_str());
725
726 StatusCode status = namespace_->ListDirectory(path, response->mutable_files());
727 for (int i = 0; i < response->files_size(); i++) {
728 FileInfo* file = response->mutable_files(i);
729 if ((file->type() & (1 << 9)) == 0) {
730 //maybe it's an incomplete file
731 SetActualFileSize(file);
732 }
733 }
734 response->set_status(status);
735 done->Run();
736 }
以上实现大致是leader处理请求;然后从namespace_->ListDirectory,从leveldb中获取元数据相关的,因为在启动初始化时:
52 void NameSpace::Activate(std::function callback, NameServerLog* log) {
53 std::string version_key(8, 0);
54 version_key.append("version");
55 std::string version_str;
56 leveldb::Status s = db_->Get(leveldb::ReadOptions(), version_key, &version_str);
57 if (s.ok()) {
63 } else {
74 }
75 SetupRoot();
76 RebuildBlockMap(callback);
77 InitBlockIdUpbound(log);
78 }
675 bool NameSpace::RebuildBlockMap(std::function callback) {
676 int64_t block_num = 0;
677 int64_t file_num = 0;
678 int64_t link_num = 0;
679 std::set entry_id_set;
680 entry_id_set.insert(root_path_.entry_id());
681 leveldb::Iterator* it = db_->NewIterator(leveldb::ReadOptions());
682 for (it->Seek(std::string(7, '\0') + '\1'); it->Valid(); it->Next()) {
683 FileInfo file_info;
684 bool ret = file_info.ParseFromArray(it->value().data(), it->value().size());
685 assert(ret);
686 if (last_entry_id_ < file_info.entry_id()) {
687 last_entry_id_ = file_info.entry_id();
688 }
689 FileType file_type = GetFileType(file_info.type());
690 if (file_type == kDefault) {
691 //a file
692 for (int i = 0; i < file_info.blocks_size(); i++) {
693 if (file_info.blocks(i) >= next_block_id_) {
694 next_block_id_ = file_info.blocks(i) + 1;
695 block_id_upbound_ = next_block_id_;
696 }
697 ++block_num;
698 }
699 ++file_num;
700 if (callback) {
701 callback(file_info);
702 }
703 } else if (file_type == kSymlink) {
704 ++link_num;
705 } else {
706 entry_id_set.insert(file_info.entry_id());
707 }
708 }
709 //more code...
从代码中看元数据信息是存在leveldb中的,其中有些代码使用了google protobuf rpc,这块我不是很熟悉,后面会看下怎么用的,和解决什么业务场景。
这篇是简单介绍,可能分析的不够深入,后续文章会详细分析每个模块的实现原理。
另外,如果让我们来实现一个文件系统,只考虑基本功能,有建文件,有写文件,有读文件,有列出文件信息。
对于像在本地执行ls命令一样,列出基本文件信息,包括建立文件的用户,最后访问时间,所在路径,文件类型等,这些都作为元数据的一部分存储在某个地方如bfs中的namesever,且是冗余的,如bfs中那样通过raft来解决单点问题。
那具体写文件,比如说1GB大小,如何进行分片?是如ceph中那样通过某种一致性hash算法散列到不同的机器上?由谁来处理这些工作?副本数多少保证高可用?比如chunkserver来负责具体的数据落地和备份。
chunkserver的健康这些也要及时管理。然后用户写文件或读文件,怎么设计?是先和nameserver通信,进行一些检查等,然后怎么做?其实我也不知道,之前ceph相关的貌似直接通过datanode进行通信,后面再分析下ceph/hdfs吧。
参考
初步掌握HDFS的架构及原理
BFS Master 高可用设计方案
BFS FAQ
使用google protobuf RPC实现echo service