Python之扩展包安装
scikit learn 是Python下开源的机器学习包。(安装环境:win7.0 32bit和Python2.7)
Python安装第三方扩展包较为方便的方法:easy_install + packages name
在官网https://pypi.python.org/pypi/setuptools/#windows-simplified
下载名字为

的文件。
在命令行窗口运行
添加到环境变量中,即可方便使用easy_install.exe命令了。
理论上应该可以使用 easy_install命令安装matplotlib,numpy。但是由于网速限制,总是出错。所以可以选择下载.exe文件手动安装。
scikit-learn需要以下包或者工具:
Python (>= 2.6 or >= 3.3),
NumPy (>= 1.6.1),
SciPy (>= 0.9).
numpy 下载链接
http://download.csdn.net/detail/ivankeiths/1205245
matplotlib下载链接
http://matplotlib.org/downloads.html
在安装matplotlib之前,需要安装两个辅助包,dateutil 和 pyparsing.
可以采用命令 easy_install python_dateutil和easy_install pyparsing安装
后手动安装matplotlib即可
若运行命令import matplotlib.pyplot as plt 出现错误
ImportError: No module named six; 可把路径:
C:\Python27\Lib\site-packages\scipy\lib中的six.py six.pyc six.pyo三个文件拷贝到C:\Python27\Lib\site-packages目录下。
安装SciPy出现如下错误:
I cannot import datetime from a python script, ValueError: numpy.ufunc has the wrong size, try recompiling
考虑更换版本。
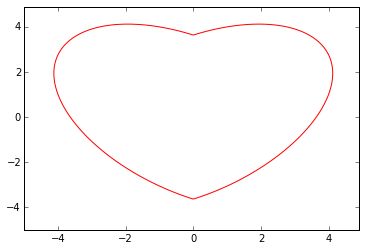
测试如下代码:
1 importnumpy as np
2 importmatplotlib.pyplot as plt
3
4 X = np.arange(-5.0, 5.0, 0.1)
5 Y = np.arange(-5.0, 5.0, 0.1)
6
7 x, y =np.meshgrid(X, Y)
8 f = 17 * x ** 2 - 16 * np.abs(x) * y + 17 * y ** 2 - 225
9
10fig =plt.figure()
11cs = plt.contour(x, y, f, 0, colors ='r')
12plt.show()
运行后:
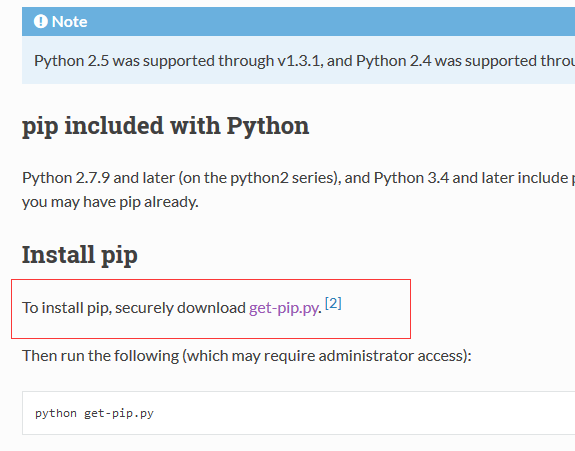
或者安装pip 命令,操作同上。下载网址https://pip.pypa.io/en/latest/installing.html
如果嫌配置麻烦,可以考虑安装IDE环境,本文推荐WinPython
https://winpython.github.io/下载32bit或64bit的IDE. 安装后的界面和RStudio相似。
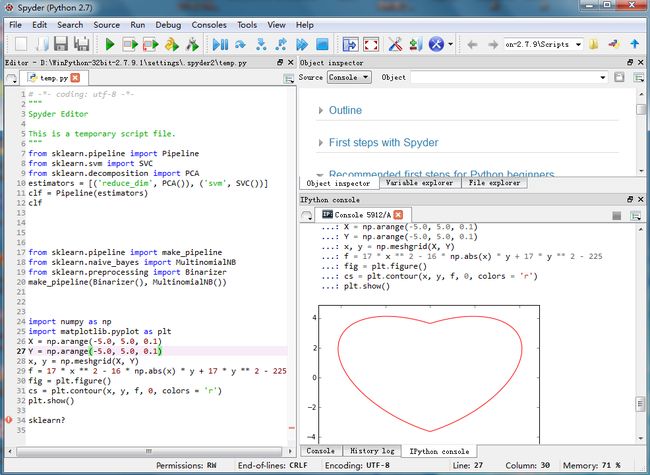
WinPython 是由 Python(x,y) 的作者开发,功能是比较全的,软件包也比较新,GUI基于PyQt, 不过相对于Python(x,y),
它主要是关注便携式安装体验:你可以把它装在u盘里面。windows中可以不再使用Python(x,y)了,改成 WinPython了。
现在的版本支持Python2和3,稳定性已有相当的改善.发布的版本也比较全。winpython自带了 spyder作为Python开发环境,安装时会自动安装sypder。
关于Python IDE介绍参看:http://blog.csdn.net/rumswell/article/details/8927603
Python与R的比较
Python与R不同,Python是一门多功能的语言。数据统计是更多是通过第三方包来实现的。
具体来说,我常用的Python在统计上面的Package有这样一些
1.Numpy与Scipy。这两个包是Python之所以能在数据分析占有一席之地的重要原因。其中Numpy封装了基础的矩阵和向量的操作,而Scipy则在Numpy的基础上提供了更丰富的功能,比如各种统计常用的分布和算法都能迅速的在Scipy中找到。
2.Matplotlib。这个Package主要是用来提供数据可视化的,其功能强大,生成的图标可以达到印刷品质,在各种学术会议里面出镜率不 低。依托于Python,可定制性相对于其他的图形库更高。还有一个优点是提供互动化的数据分析,可以动态的缩放图表,用做adhoc analysis非常合适。
3.Scikit Learn。非常好用的Machine Learning库,适合于用于快速定制原型。封装几乎所有的经典算法(神经网络可能是唯一的例外,不过这个有Pylearn2来补充),易用性极高。
4.Python标准库。这里主要是体现了Python处理字符串的优势,由于Python多功能的属性和对于正则表达式的良好支持,用于处理text是在合适不过的了。
基本上就日常使用就涉及这些。符号运算等等也有Sympy和Theano等强力第三方库来支持。总结,Python在你列举这些里面是综合功能最强大的,但是这些功能分散在第三方库里面,没有得到有机的整合,相应的学习成本会较高。
其它意见:
python与R相比速度要快。python可以直接处理上G的数据;R不行,R分析数据时需要先通过数据库把大数据转化为小数据(通过groupby)才能交给R做分析,因此R不可能直接分析行为详单,只能分析统计结果。Python=R+SQL/Hive
R的优势在于有包罗万象的统计函数可以调用,特别是在时间序列分析方面(主要用在金融分析与趋势预测)无论是经典还是前沿的方法都有相应的包直接使用;相比python在这方面贫乏不少。
Python的优势在于其胶水语言的特性,一些底层用C写的算法封装在python包里后性能非常高效(Python的数据挖掘包Orange canve 中的决策树分析50万用户10秒出结果,用R几个小时也出不来,8G内存全部占满)。
总的来说Python是一套比较平衡的语言,各方面都可以,而R是在统计方面比较突出。但是数据分析其实不仅仅是统计,前期的数据收集,数据处理, 数据抽样,数据聚类,以及比较复杂的数据挖掘算法,数据建模等等这些任务,只要是100M以上的数据,R都很难胜任,但是Python却基本胜任。
补充一下:Python有专门的数据分析包Pandas用来完成类似SQL的功能,不过Pandas是会把数据都load到内存里,如果数据太大(2G以上)需要想办法分chunk分析,或者用pytables/pyh5转换为hdf5格式的文件在硬盘上分析。
另外如果是windows环境的话,建议用winpython,上面提到的这些包会自带。当然更丰富的是pythonxy可惜这个只有32位的。
SAS和SPSS是商业数据分析软件,本屌从来没用过。