好久没写东西了,开始是因为准备毕设,毕业了有点散漫,后来公司任务有点繁重,再后来国庆中秋玩了 8 天……总之就是一个字 -- 太懒了。现在我得把这些东西捡起来,尽量每周都能总结一些东西。
因为公司人手不够,我又搞了点 Python 的东西。人生苦短,我学 Python。这篇文章就是写如何应用 Python 编写一个简单的爬虫
- 陆续会有几篇爬虫相关的文章:
- 应用正则匹配爬取 “百思不得姐”
- 应用 selenium 爬取 “糗事百科”
- 爬取 “36kr” 首页新闻
- 爬取 “腾讯新闻”
不多废话,开始
一、分析网页代码
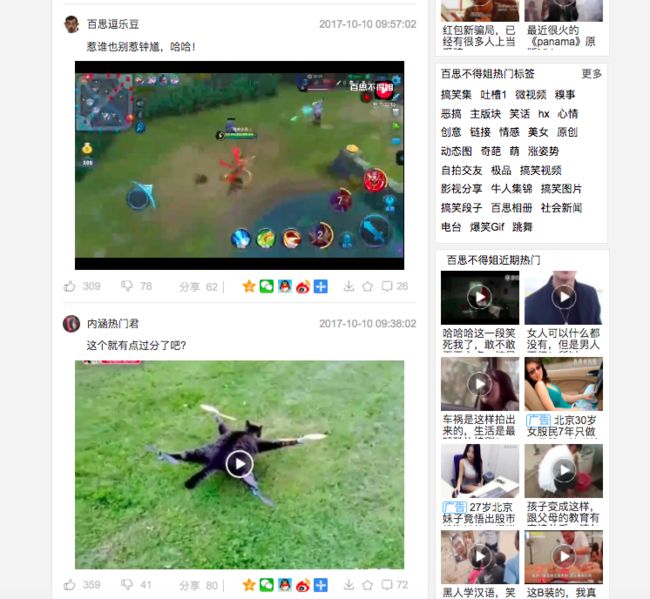
我们要爬取的是 “百思不得姐” 的视频模块,首先打开百思不得姐看一下网页结构。
我们看到网页左部分即需要爬取的搞笑视频,右部分是一些标签、广告等。然后我们 command + alt + u 来看下网页的源代码。
可以找到我们要爬取的视频标题、地址在代码中的位置,所以我们只要获取该位置的代码即可。
二、获取网页代码
- 很多网站做了反爬处理,我们可以模拟浏览器访问,拿到 User-Agent
- 下载 requests 模块并导入该模块
代码如下
#!/usr/bin/env python
#coding:utf-8
import requests
page = 1
def getData():
global page
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
url = 'http://www.budejie.com/video/' + str(page)
html = requests.get(url, headers = headers).text
print html
getData()
运行即可获取 “百思不得姐” 的 HTML 代码。
三、正则匹配视频和标题
第一步中我们已经得到网页的代码结构,我们需要通过正则匹配对应部分的代码。
此部分代码如下:
#!/usr/bin/env python
#coding:utf-8
import requests
import re
data = []
page = 1
def getData():
global page
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
url = 'http://www.budejie.com/video/' + str(page)
html = requests.get(url, headers = headers).text
match_obj = re.compile(r'.*?
.*?
', re.S)
results = re.findall(match_obj, html)
for item in results:
match_video = r'data-mp4="(.*?)">'
video = re.findall(match_video, item)
# print video
if video:
match_title = re.compile(r'
(.*?)', re.S)
title = re.findall(match_title, item)
# print title
for i, j in zip(title, video):
data.append([i, j])
print i, j
getData()
match_obj 是匹配了每个视频的最外层的
,和后面两个
match_video 是匹配对应视频的地址
match_title 是匹配对应视频的标题
四、下载视频
最后把爬取的视频下载到本地,需要用到 urllib、os 模块。
首先应用 os 模块判断当前文件目录下是否存在名为 video 的文件夹,没有则创建一个
def initFile():
dir = os.getcwd()
list = os.listdir(dir)
flag = False
for i in list:
if i == 'video':
flag == True
break
if flag == False:
os.mkdir('video')
然后应用 urllib 的 urlretrieve 方法进行下载。
num = 1
def saveData():
global num
while num <= 10:
data = getData()
for i in data:
urllib.urlretrieve(i[1], './video/%s.mp4' %(i[0]))
data.pop(0)
num += 1
num 用来控制视频下载个数,我这里以 10 个为例演示。
./video/%s.mp4 为保存的路径,若不写 initFile 方法,也可以直接写成完整路径,如:
/Users/JackieQu/Desktop/Crawler/video/%s.mp4
五、完整代码与演示
#!/usr/bin/env python
#coding:utf-8
import requests
import re
import urllib
import os
data = []
page = 1
def getData():
global page
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
url = 'http://www.budejie.com/video/' + str(page)
html = requests.get(url, headers = headers).text
match_obj = re.compile(r'.*?
.*?
', re.S)
results = re.findall(match_obj, html)
for item in results:
match_video = r'data-mp4="(.*?)">'
video = re.findall(match_video, item)
if video:
match_title = re.compile(r'
(.*?)', re.S)
title = re.findall(match_title, item)
for i, j in zip(title, video):
data.append([i, j])
return data
num = 1
def saveData():
global num
while num <= 10:
data = getData()
for i in data:
urllib.urlretrieve(i[1], './video/%s.mp4' %(i[0]))
data.pop(0)
num += 1
def initFile():
dir = os.getcwd()
list = os.listdir(dir)
flag = False
for i in list:
if i == 'video':
flag = True
break
if flag == False:
os.mkdir('video')
initFile()
saveData()
哦了,要想爬取多页数据,改改页码,遍历一下即可。