由于日后实习需要,新年假期在家里有空写了个抓取天mao评论的程序,并用python的snownlp模块进行简单的情感分析,由于本人刚接触python,项目可能有许多不足,请大家谅解!具体流程如下:
0.主要流程
0.数据采集
0. 目标网址获取
首先,获取自己要爬取的商品网页。如图:
这里用iPhone x的商品做样例(博主目前使用的手机是小米3,穷鬼啊有没有!)。因为加载评论的页面用js封装起来了。因此需要用到浏览器开发者工具获取保存评论的页面,直接按F12打开。如图:

在NETwork//js目录下有一个形如上图的网址(巨长无比呀),细心发现会有一个page=1的字段,这个是控制不同页数的关键字!因此我们只需要改变page的值就能爬取不同页面的内容了!!具体代码如下:
# -*- coding: utf-8 -*-
import urllib.request
import json
import time
import re
import pymysql
def find_message(url,x,j):
print('已有' + str(x) + '页无法获取')
#读取网页数据
html = urllib.request.urlopen(url).read().decode('gbk')
#筛选json格式数据
jsondata=re.search('^[^(]*?\((.*)\)[^)]*$', html).group(1)
#用json加载数据
data = json.loads(jsondata)
#数据保存在变量里
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='1234', db='pysql', charset='utf8')
cur = conn.cursor()
# 连接mysql
print('连接成功!!!!')
try:
for i in range(0, len(data['rateDetail']['rateList'])):
#print(str(i + 1) + data['rateDetail']['rateList'][i])
name = data['rateDetail']['rateList'][i]['displayUserNick']
#处理过的用户名
content = data['rateDetail']['rateList'][i]['rateContent']
#当天评论
time = data['rateDetail']['rateList'][i]['rateDate']
# 评论日期
iphonetype = data['rateDetail']['rateList'][i]['auctionSku']
#机型
appenddays = data['rateDetail']['rateList'][i]['appendComment']['days']
#追加评论的天数
appendtime=data['rateDetail']['rateList'][i]['appendComment']['commentTime']
#追加评论的时间
appendcontent=data['rateDetail']['rateList'][i]['appendComment']['content']
#追加评论的内容
cur.execute("insert into iphonex(用户名,当天评论,当天时间,机型,追加天数,追加时间,追加评论) values (\"%s\",\"%s\",\"%s\",\"%s\",%d,\"%s\",\"%s\")"%(str(name),str(content),str(time),str(iphonetype),int(appenddays),str(appendtime),str(appendcontent)))
print(str(j+1)+"页数据已经保存")
#数据插入mysql
return x
except BaseException:
x+=1
print('已有'+str(x)+'页无法获取')
print("####此页无法获取####")
return x
#主函数
x=0
for j in range(1,50):
try:
print("正在获取第{}页评论数据!".format(j))
url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=560257961625&spuId=893336129&sellerId=1917047079&order=3¤tPage=' + str(j) +'&append=1&' \
'content=1&tagId=&posi=&picture=0&ua=098%23E1hvLpvZv7UvUpCkvvvvvjiPPLLhzjtbPscOsjljPmPhljlUR25Z0jlURFSWljn8RFyCvvpvvvvvdphvmpvhOOhvvv2' \
'psOhCvv147GzzgY147Dunrn%2FrvpvEvvkj9oIuvWLMdphvmpvWPgEboQvgfOhCvv14cOjzyC147DikWn%2Fjvpvhvvpvv8wCvvpvvUmmRphvCvvvvvvPvpvhMMGvvvyCvhQpm' \
'kwvCszEDajxRLa9mNLhQnmOjVQ4S47B9CkaU6bnDO2hV36AxYjxAfyp%2B3%2BuQjc60fJ6EvLv%2BExreE9aUExr0jZ7%2B3%2Buzjc61C4Auphvmvvv9bvT4yc7kphvC99v' \
'vOClpbyCvm9vvvvvphvvvvvv96Cvpvs4vvm2phCvhRvvvUnvphvppvvv96CvpCCvvphvC9vhvvCvp86Cvvyv224CeiIvHUytvpvhvvvvv86CvvyvhEKCFgGv1WQtvpvhvvvvvUh' \
'CvmDz7GczTr147Dup2nGD1TAqsd%2FoU0dieGd8S6STvI8byIKB9OHmvtmWyv%3D%3D&isg=BAMDf2HuXRdECBGLXKb6oZc2ksdt0Jbc5_lgETXg6mLa9CIWvUsTCypmaoS61O-y&itemPropertyId=&itemPropertyIndex=&userProp' \
'ertyId=&userPropertyIndex=&rateQuery=&location=&needFold=0&_ksTS=1518175553706_1200&callback=jsonp1201'
x=find_message(url,x,j)
time.sleep(3)
# 设置时间间隔(这个不要忽视)
except BaseException:
continue
说几点代码的问题:
js网页效果图如下:

jsondata=re.search('^[^(]*?\((.*)\)[^)]*$', html).group(1)
由网页效果图可知,评论信息是保存在jsonp719()里面的,因此需要用正则表达式获取()里面的内容,去除无用部分,然后用json.loads得到字典data。

如上图,用pycharm里面的json格式打开输出的数据data可以得到想要的数据在字典中位置。
在data = json.loads(jsondata)后面加print(data)输出原数据会发现一些问题:如下

打开图中url得到:

没错这个就是securitymatrix(下篇文章介绍),这样会有一些页面无法获取一些页面,所以需要设置 time.sleep(3),这里用参数3,其实最好用random()选随机数3到5的参数(这样T猫机器人没那么容易发现你也是它的同类,页面丢失率会降低,当然你也可以写个函数重新获取丢失的页面)
运行结果:


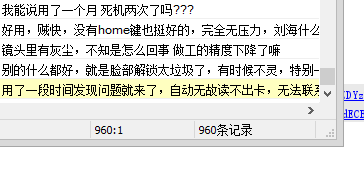
由于丢失了2页数据,所以剩下960条记录(50页每页20条)
好了爬取工作完成了!
1. 爬虫框架选用
本来打算是用python的selenium模块模拟登录爬取的但是由于天猫的securitymatrix安全系统()比较强大,博主还没有能力破解,这里只能使用自己写的流程用request库抓取网页。
当然你也可以选择python的scrapy模块爬取,这个看个人喜好吧!核心思路是不变的。
好了爬虫部分写到这里了,后面的内容以后会更新!由于博主还是小白,写的代码,特别是异常处理写的不是很规范。希望各位大师指点。
听说帅的人都点赞和打赏了!
那么你帅吗????^-^
还有欢迎各位留言交流!!!
预祝2018,新年快乐!