决策树算法
优点
计算复杂度不高,输出结果易于理解,对中间值得缺失不敏感,可以处理不相关特征数据。
缺点
可能会产生过度匹配问题
适用数据类型
数值型和标称型数据
信息增益
划分数据的大原则是:将无序的数据变得更加有序。组织杂乱无章数据的一种方法就是使用信息论度量信息。
在划分数据集之前之后信息发生的变化称为信息增益。通过计算每个特征划分数据集获得的信息增益来度量划分后的数据是否更有序,获得信息增益最大的特征就是此次划分数据的最好特征。即此次根据特征划分数据后,数据已经被尽可能的正确分类。
对数据集合信息的度量方式称为香农熵。信息增益即为划分数据前后香农熵的差值。
熵定义为信息的期望值。如果待分类的事务可能划分在多个分类之中,则符号x的信息定义:
p(xi)是选择该分类的概率。
熵的计算方式:
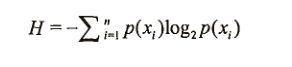
具体代码实现:
from math import log
from collections import defaultdict , Counter
###测试数据集
def createDataset():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
featLabels = ['no surfacing','flippers']
return dataSet, featLabels
def calcShannonEnt(dataset):
###计算数据集的香农熵,用于衡量该数据集的复杂度,如果该数据集越复杂,类别越多,香农熵值越大,反之越小
numEntries = len(dataset)
labels = defaultdict(int)
for featVec in dataset:
label = featVec[-1]
labels[label] += 1
shannonEnt= 0.0
for v in labels.values():
prob = float(v) / numEntries
shannonEnt -= prob * log(prob, 2)
return shannonEnt
在计算得到香农熵之后就可以通过计算信息增益来寻找最好的分类特征
def splitDataset(dataset, axis, value):
###根据特征值划分数据集 axis:特征下标 value:特征值
retDataset=[]
for featVec in dataset:
if featVec[axis] == value:
reducedFeatvec = featVec[:axis]
reducedFeatvec.extend(featVec[axis+1:])
retDataset.append(reducedFeatvec)
return retDataset
def chooseBestFeatureToSplit(dataset):
###在当前数据集寻找最适合划分数据集的特征,通过计算根据每种特征划分数据集的信息熵之和,寻找熵增最大的特征
numFeats = len(dataset[0]) - 1
baseEntropy = calcShannonEnt(dataset)
bestInfoGain = 0.0
bestFeat = -1
for i in range(numFeats):
featValues = set([data[i] for data in dataset])
newEntropy = 0.0
for value in featValues:
resDataset = splitDataset(dataset, i, value)
prop = len(resDataset) / float(len(dataset))
newEntropy += prop * calcShannonEnt(resDataset)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeat = i
return bestFeat ##返回特征下标
递归构建决策树
在每次分类动作进行时根据最佳特征尽可能将相同分类分配在同一组数据中
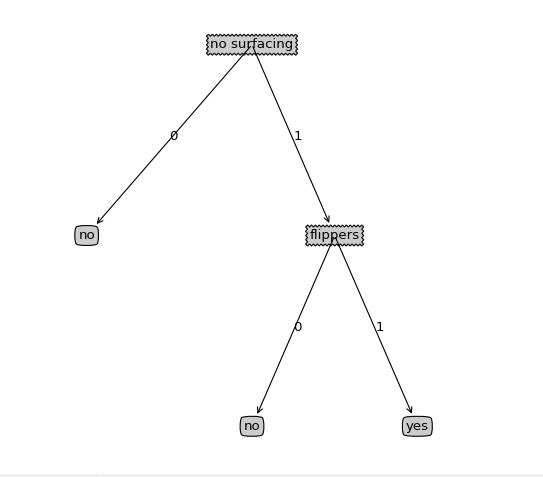
Example
'no surfacing','flippers','is_fish'
1 1 yes
1 1 yes
1 0 no
0 1 no
0 1 no
其决策树:
决策树构建代码:
def majorityCnt(classList):
###寻找当前类标签出现最多的标签 classList:标签值集合
return Counter(classList).most_common()[0][0]
def createTree(dataset, inputLabels):
####inputLabels: 特征标签
labels = inputLabels[:] ##防止输入标签被更改
classList = [data[-1] for data in dataset]
###当前数据集的所有标签值相同,分类结束,返回标签
if classList.count(classList[0]) == len(classList):
return classList[0]
###当前已经根据所有特征划分数据集,返回最多的标签值
if len(dataset[0]) == 1:
return majorityCnt(classList)
bestFeatIndex = chooseBestFeatureToSplit(dataset)
bestFeatValues = set([data[bestFeatIndex] for data in dataset])
bestFeatLabel = labels[bestFeatIndex]
del labels[bestFeatIndex] ###划分数据集会移除该特征,对应特征标签也要移除
trees = {bestFeatLabel:{}}
for value in bestFeatValues:
new_labels = labels[:] ###这里必须创建新的list对象,传参后引用会影响当前labels的值
trees[bestFeatLabel][value] = createTree(splitDataset(dataset, bestFeatIndex, value), new_labels)
return trees
绘制决策树
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle='sawtooth', fc='0.8')
leafNode = dict(boxstyle='round4', fc='0.8')
arrow_args = dict(arrowstyle="<-")
def plotNode(nodeText, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeText, xy=parentPt, xycoords='axes fraction', \
xytext=centerPt, textcoords='axes fraction', va='center', ha='center', bbox=nodeType, arrowprops=arrow_args)
def getNumLeafs(trees):
numLeafs = 0
firstStr = trees.keys()[0]
secondDict = trees[firstStr]
for key in secondDict.keys():
if isinstance(secondDict[key],dict):
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(trees):
maxDepth = 0
firstStr = trees.keys()[0]
secondDict = trees[firstStr]
for key in secondDict.keys():
if isinstance(secondDict[key], dict):
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0]
cntrPt = (plotTree.x0ff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.y0ff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.y0ff = plotTree.y0ff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if isinstance(secondDict[key], dict):
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.x0ff = plotTree.x0ff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.x0ff, plotTree.y0ff), cntrPt, leafNode)
plotMidText((plotTree.x0ff, plotTree.y0ff), cntrPt, str(key))
plotTree.y0ff = plotTree.y0ff + 1.0 / plotTree.totalD
def createPlot(tree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(tree))
plotTree.totalD = float(getTreeDepth(tree))
plotTree.x0ff = -0.5 / plotTree.totalW
plotTree.y0ff = 1.0
plotTree(tree, (0.5, 1.0), '')
plt.show()
调用createPlot()函数即可绘制决策树
构建分类器
根据现有的决策树构建分类器
def classify(tree, featLabels, testVec):
### {'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
firstStr = tree.keys()[0]
secondDict = tree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if key == testVec[featIndex]:
if isinstance(secondDict[key], dict):
classLabels = classify(secondDict[key], featLabels, testVec)
else:
classLabels = secondDict[key]
return classLabels