小洁写于2018.9.4 高能预警:全文很长,适合用电脑打开,对照练习。如果用手机看,瞄两眼思维导图,记住常用的几个函数名字就可以洗洗睡了。这应该是我写的史上最长教程TOT

1.准备
(1)准备R包
在《小洁详解
小洁补充:除了conflicts外,R还会返回Warning和error。conflicts和warning一样,是可以视而不见的。
install.packages("nycflights13")
library(nycflights13)
library(tidyverse)
(2)准备示例数据
使用nycflights13包的flights作为示例数据。
拿到一个数据首先要观察它。-我忘了谁说的,反正好有道理
那么我仔细端详flights
2013年从纽约市出发的所有336776次航班的信息。
flights #就瞅一眼,看看几行几列
?flights #好好瞅瞅每列表示什么意思
View(flights)#以表格的形式好好瞅瞅
class(flights)#了解他的类别
行列数:336,776 x 19
year,month,day -日期
dep_time sched_dep_time 起飞时间 实际/计划
dep_delay 起飞延误时间
arr_time sched_arr_time 到达时间 实际/计划
arr_delay 到达延误时间
carrier 航空公司缩写
flight 航班号
tailnum 飞机尾号
origin/dest 出发地/目的地
air_time 飞行总时间,单位min
distance 出发地和目的地两机场间的距离,单位英里
hour、minute 计划停歇时间
time_hour
补充:变量类型
int -整数
dbl-双精度浮点数、实数
dttm-日期+时间
lgl-逻辑型变量,仅包括TRUE和FALSE
fctr-因子,R中用因子表示具有固定数目的值的分类。
date-日期型变量
(3)dplyr包的核心函数
- filter 按行筛选
- arrange 给行排序
- select 按列筛选
- mutate 根据原有列生成新列
- summarize 摘要统计
关于行和列的补充:行=观测,列=变量
2.使用filter()进行行筛选
注意:dplyr函数不修改原数据框,只从原数据框中生成新数据框,如果新生成的数据框不赋值给一个新的变量,那么就会丢失。
R要么输出结果,要么赋值。将赋值语句用括号括起来则可以同时完成这两种操作。
filter(flights, month == 1, day == 1) #输出结果
jan1 <- filter(flights, month == 1, day == 1) #赋值
(dec25 <- filter(flights, month == 12, day == 25))#两种操作
(1)比较运算符
>,>=,<,<=,!= ,==
双精度浮点数用near(a,b)取代a==b
(2)逻辑运算符
布尔运算符号 &|!并、或、非

- 复杂的筛选条件简化 %in%
filter(flights, month == 11 | month == 12)
filter(flights, month %in% c(11, 12))
- 复杂的筛选条件简化 !
!(x & y)等价于!x | !y,!(x | y)等价于!x & !y
tips:括号要从内向外计算
filter(flights, !(arr_delay > 120 | dep_delay > 120))
filter(flights, arr_delay <= 120, dep_delay <= 120)
(3)缺失值
NA,表示有一个值,但是不知道具体是啥,相当于个陌生人。而NULL相当于,根本没人。。。
NA与NULL的区分:一个元素值全为NA的向量,它的长度是存在的,就等于元素的个数。而如果把一个向量的所有元素的值都设为NULL,这个向量就变成了“空值”,其长度为0,表明“空无一物”。(出处:Mountain's_blog)
df <- tibble(x = c(1, NA, 3))
filter(df, x > 1)
filter(df, is.na(x) | x > 1) #is.na(x)判断是否为缺失值
3.arrange()
arrange(flights, year, month, day)
arrange(flights, desc(dep_delay))
无论正序倒序,空值排在最后
df <- tibble(x = c(5, 2, NA))
arrange(df, x)
arrange(df, desc(x))
如果要将NA排在最前面,则需要使用
arrange(flights, desc(is.na(dep_time)), dep_time)
关于3.3的练习
(2)对比了一下中英文的问题和答案,感觉“出发时间最早”,作者想表达的可能是提前出发时间最长的(比如有一班提前43分钟飞走的,恕我孤陋寡闻不知道有这种操作啊),而不是半夜12点起飞的。有点歧义。
(3)fastest,我以为要距离除以飞行时间这样算。我认为应该是
mutate(flights,vic=distance/air_time) %>%arrange(desc(vic)) %>%select(year,month,day,vic,everything())
结果给出的答案是飞行时间最短的,应该是不严谨,欢迎发表不同意见。
(4)第四题英文原文说的是Which flights traveled the longest? Which traveled the shortest?
中文书籍翻译为飞行时间最长、最短,英文答案则认为是距离最长、最短,这个歧义也是哈哈。没有什么深究的意义,个人偏向于距离,至于真正表达的意思应该只有hadley大神自己清楚了。
小洁续写于2018.9.10
4.select()按列筛选
#1. 根据列名单独选择某几列
select(flights, year, month, day)
#2.连选几列
select(flights, year:day)
#3.连选+反选
select(flights, -(year:day))
#4.辅助函数-选择列名符合以下要求的
starts_with("abc"): 以abc开头的
ends_with("xyz"): 以xyz结尾的
contains("ijk"):包含ijk的
matches("(.)\\1"): 匹配正则表达式的
#5.重命名
rename(flights, tail_num = tailnum) #将tailnum修改为tail_name
#6.某几列移动到开头,everything表示其余各列
select(flights, time_hour, air_time, everything())
p42练习
-------------------------------------------------(我又偷窥答案了)-------------------------------------------------------------
(2)select()函数多次计入一个变量名,会自动去重复,只保留第一次。
(3)one_of()
vars <- c("year", "month", "day", "dep_delay", "arr_delay")
select(flights, one_of(vars))
var是character vector(特征向量),这样写出的select()只不必写多个向量名。
(4)select辅助函数默认忽略大小写,如需修改:
select(flights, contains("TIME", ignore.case = FALSE))
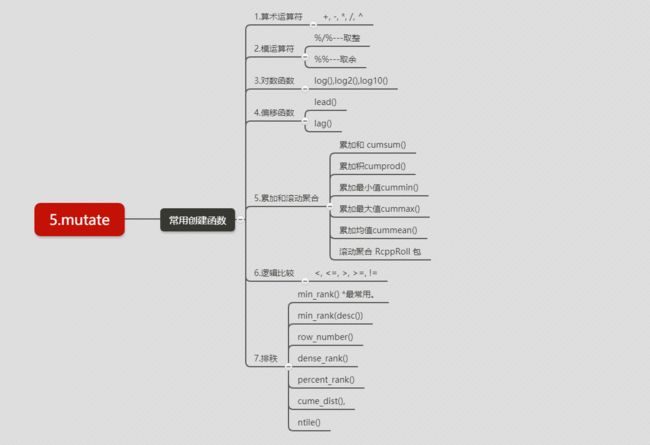
5.mutate() 生成新列
mutate和transmute的区别:mutate生成新列后,添加新列到数据框末尾,生成新数据框。transmute则是只保留新生成的列。这里说的是生成,是指原有列加减乘除等计算出的结果作为新列。
生成新列gain和speed:
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
mutate(flights_sml,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
新列可以直接参与另一新列的生成,原文“一旦创建,新列就可以立即使用”。这里指的是可以根据新列进行新的计算,再生成新列。
mutate(flights_sml,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
transmute():只保留新列。
transmute(flights,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
6.使用summarize()进行分组摘要
其实应该是使用group_by和summarize()进行分组摘要。如果没有group_by,就会把整个数据框作为一个整体,会变成一行。
书中的代码中有na.rm = TRUE,删掉的话会变成:

group_by函数会使summarise更有用。按照某列来分组,分别汇总摘要。
ex:计算每天的平均延误时间
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))
(1)管道操作
管道操作会简化代码,数据框名不必重复写多次。
#level一-生成中间产物,不喜欢
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))
#level二-这个是我习惯的方式
summarise(group_by(flights, year, month, day), delay = mean(dep_delay, na.rm = TRUE))
#level三-管道操作连接两步,数据框名在括号里面
group_by(flights, year, month, day) %>% summarise(delay = mean(dep_delay, na.rm = TRUE))
#level四-管道操作连接两步,数据框名在括号里面
flights %>%group_by( year, month, day) %>% summarise(delay = mean(dep_delay, na.rm = TRUE))
完成数据准备需要分组--摘要统计--筛选。
管道操作连接多行命令时,将管道符号%>%放在上一行末尾。
(2)缺失值
上面提到,代码中有na.rm = TRUE,删掉的话会变成:
这是因为缺失值会“传染”,也就是说用于计算平均值的数中有空值,那么结果就是空值。
下面这个例子也是一样,分组后计算出的dep_delay仍然都是空值。
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))

na.rm = TRUE这个参数会在计算前移除缺失值。
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))
移除后计算的方法,还可以用filter筛出非空行列,再行计算。(笨办法)
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
(3)计数
示例:找出平均延误时间最长的飞机
(根据tailname进行分组,得到的时全年同一架飞机的各种数据)
补充:关于count()和n()的探索:统计每个航空公司各有多少趟航班
carriers <- group_by(flights, carrier)
s1 <- summarise(carriers, n())
s2 <- count(flights,carrier)
mu <- mutate(carriers, n = n())
s3 <- distinct(mu,n)
s4 <- distinct(mu,carrier,n)
四种方法统计的结果是一致的,distinct是去重复。
(4)常用的摘要函数

(5)按多个变量分组
(其实表达的意思是 多级分组)
#先按照年月日分组,也就是按天
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))
#再按照月份汇总摘要
(per_month <- summarise(per_day, flights = sum(flights)))
#再按年汇总,只有一年的数据所以成了一行
(per_year <- summarise(per_month, flights = sum(flights)))
(6)取消分组 ungroup
也就是说将分好组的数据框可逆返回到原始数据。
daily %>%
ungroup() %>% # no longer grouped by date
summarise(flights = n()) # all flights
7.分组新变量
(1)找出每个分组中最差的成员
原文“找出每个分组中最差的成员”在例子中,是选择每天延误时间最长的10趟航班
flights_sml %>%
group_by(year, month, day) %>%
filter(rank(desc(arr_delay)) < 10)
(2)找出(数量)大于某个阈值的所有分组
找出最受欢迎的目的地,也就是dest中出现次数高的(高于阈值365)。
思路是;分组,计数,筛选
popular_dests <- flights %>%
group_by(dest) %>%
filter(n() > 365)
(3)对数据进行标准化以计算分组指标
例:筛选延误的航班,计算各航班的延误时间占目的地总延误时间的比例,并显示指定列。
popular_dests %>%
filter(arr_delay > 0) %>%
mutate(prop_delay = arr_delay / sum(arr_delay)) %>%
select(year:day, dest, arr_delay, prop_delay)
文章结尾一般都要写点碎碎念,反正正文这么长,不是真爱也看不到这里。
由于周三看牙 周四报销 周末外出,上周的学习断断续续,这篇文章花了一个多星期完成,不开心。
今日事多,一团乱麻。希望眼前的狼狈过后,只剩下我热爱的工作和未来。祝老师们节日快乐。也祝自己成为优秀的讲师。
短短几天,经历了强东叔被陷害,马爸爸宣布明年今日不再担任阿里巴巴董事局主席。
明年,我也将离开学校,投身到我热爱的工作。希望明年今日的珠海风景独好,希望明年今日的我已经圆满地毕业,可以骄傲地过个教师节;希望明年还能做到日更公众号,经常带给豆豆一些惊喜和欢笑,带给未来老板一些刮目相看,带给小粉丝们一些收获和快乐。
突然很好奇明年今天粉丝会有多少?到时候一定会把这篇翻出来做个对比。
非凡即底线,继续加油↖(ω)↗


友情链接:
生信技能树公益视频合辑:学习顺序是linux,r,软件安装,geo,小技巧,ngs组学!
B站链接:https://m.bilibili.com/space/338686099
YouTube链接:https://m.youtube.com/channel/UC67sImqK7V8tSWHMG8azIVA/playlists
生信工程师入门最佳指南:https://mp.weixin.qq.com/s/vaX4ttaLIa19MefD86WfUA
学徒培养:https://mp.weixin.qq.com/s/3jw3_PgZXYd7FomxEMxFmw
资料大全:https://mp.weixin.qq.com/s/QcES9u1vYh-l6LMXPgJIlA