第一部分 初始、redis
redis概念
redis客户端和服务端可以再不同的设备上
redis是远程的
redis是基于内存的
所有东西都是放在内存的,这就代表redis的操作非常高速,它的速度远远高于基于硬盘的MySQL,但是所有数据都是放在内存中,它也是一个比较吃内存的
redis是非关系型数据库,关系型数据库需要之前定义数据字典,而redis则不需要。
redis的应用场景
缓存,当我们的系统接口比较慢的时候,我们可以把接口的某些数据缓存起来。当下次进行请求的时候,我们就不需要在MySQL中做比较耗时的sql操作了。而是直接去redis缓存中将所需要的MySQL数据读取出来。这是提升系统性能最常用的方法之一。
其次是队列结构买这个结构提供了push和pop操作。我们可以把redis当做队列来使用。
我们可以吧redis当做数据库存储来使用,所有的增删改查都在redis中操作。不需要借助MySQL来进行数据存储。这个做的原因是redis有非常完备的硬盘持久化机制。
redis安装
Linux+CentOS
redis2.8.13

redis server
make
redis cli
sudo make install
redis的数据类型


常用命令:set/get/decr/incr/mget等;
应用场景:String是最常用的一种数据类型,普通的key/value存储都可以归为此类;
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
set string1 yejianfeng
get string1
set string2 4
get string2
4
incr string2
5
decrby string2 2
get string2
3
list类型
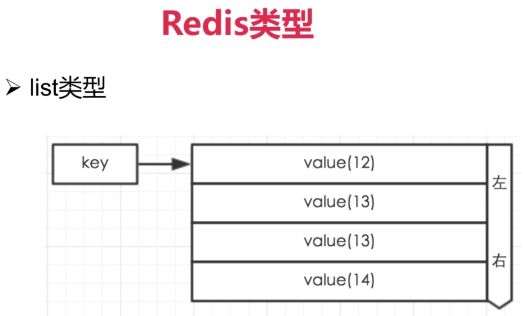
常用命令:lpush/rpush/lpop/rpop/lrange等;
应用场景:Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
可以从左边或右边推入
pop push
lpush list1 12
lpush list2 13
rpop list1
12
并不要求数据唯一
lpush list2 12
lpush list2 13
lpush list2 13
llen list2
3 (有三个数,,不要求数据元素是唯一的)
set类型
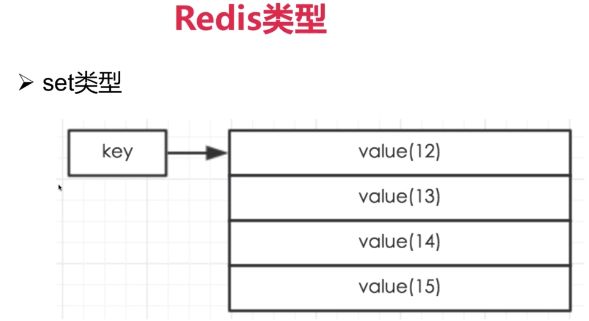
常用命令:sadd/spop/smembers/sunion等;
应用场景:Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的;
实现方式:set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
提供一种无序的数据
sadd set1 12
scard set1
1
sadd set1 13
sadd set1 13
(第二次插入是唯一的)
sismember set1 13
srem set1 13 删除13
sismember set1 13

值都不一样,,,没有相同的项
sadd set1 12
scard set1
1
sadd set1 13
sadd set1 13
12 13.
sismember set1 13
1
srem set1 13;
sismember set1 13
hash类型
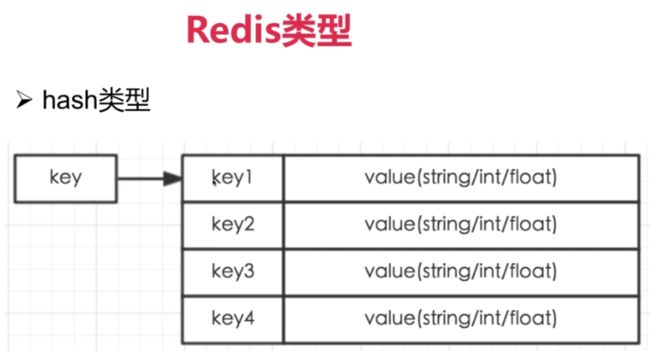
常用命令:hget/hset/hgetall等
应用场景:我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日;
实现方式:Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口。如图所示,Key是用户ID, value是一个Map。这个Map的key是成员的属性名,value是属性值。这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据。当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
hset hash1 key1 12
hget hash1 key1
"12"
hset hash1 key2 12
hset hash1 key3 13
hlen hash1
3
hset hash1 key3 14
hget hash1 key3
"14"
hmget hash1 key1 key2 //这是插入多个吧
"12"
"13"
sort set类型

常用命令:zadd/zrange/zrem/zcard等;
应用场景:Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
可以看成排行榜。。
数值是唯一的。。。。
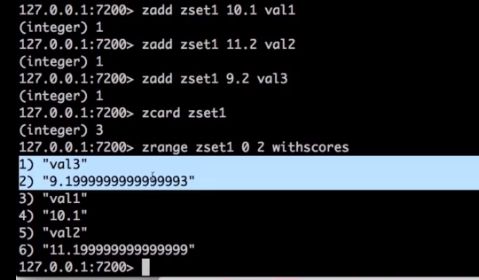
zadd zset1 10.1 val1
zadd zset1 11.2 val2
zadd zset1 9.2 val3
zcard zset1
3
zrange zset1 0 2 withscores
zrank zset1 val2
2
zadd zset1 12.2 val3
0
zrange zet1 0 2 withscores
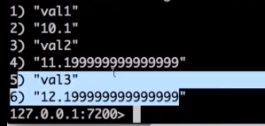
如果score相同的情况下,是按val的字母排序

第二部分 操作redis
PHP的redis扩展安装
-v 版本 -m是版本。


php --ini
PHP操作redis的五种类型