library(ggplot2)
library(VIM)
library(plyr)
library(dplyr)
library(stringr)
载入数据
TrainData <- read.csv('../RawData/train.csv', fill = TRUE, na.strings = '')
head(TrainData)
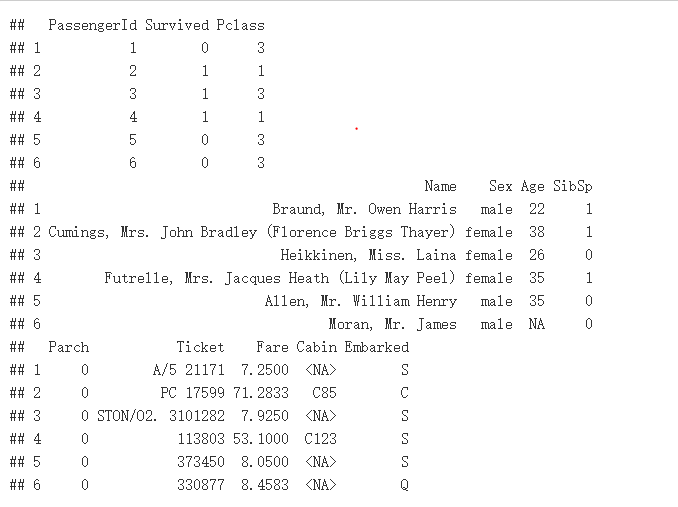
训练数据前六行
查看每列数据的信息
summary(TrainData)
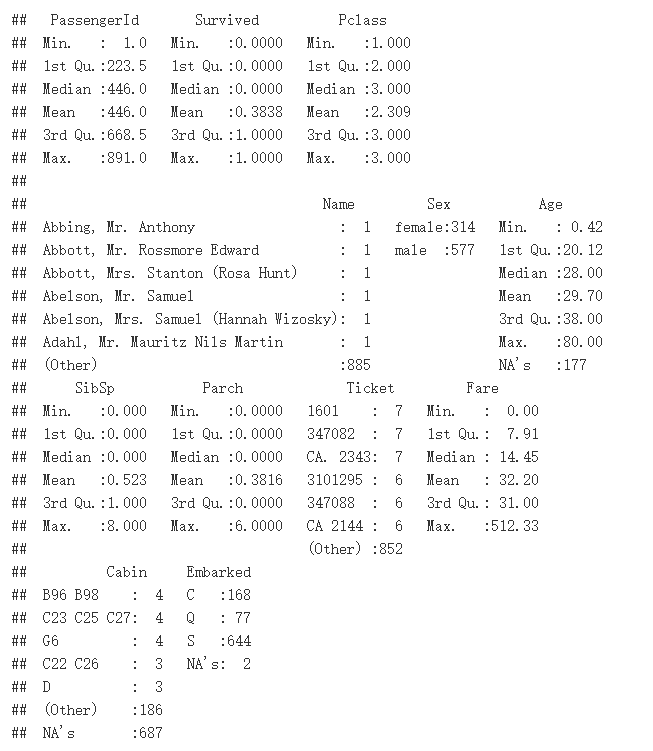
每列数据的信息
- 一共有12列,其中PassengerId、Age、Sibsp、Parch和Fare列为连续型数值变量,其它列为分类变量
- Age、Cabin、Embarked列含有缺失值
缺失值分析
sum(is.na(TrainData$Age))
177
sum(is.na(TrainData$Cabin))
687
sum(is.na(TrainData$Embarked))
2
NaPlot <- aggr(TrainData,
col=c("cyan", "red"),
numbers=TRUE,
labels=names(data),
cex.axis=.7,
gap=3,
ylab=c("Histogram of missing data","Pattern")) #缺失值信息可视化
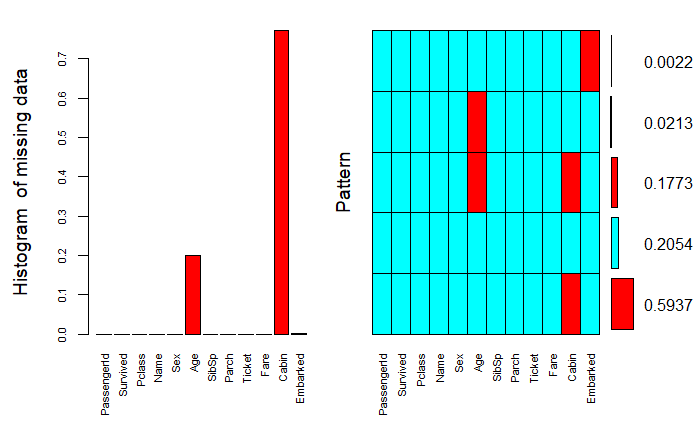
缺失值信息
- Age列含有177个缺失值,缺失率约为20%;
- Cabin列含有687个缺失值,缺失率约为76%,预测的时候可以考虑删除这一列数据
- Embarked列含有2个缺失值,缺失率约为0.2%,后面可以考虑用整列的平均值或众数填充
单变量分析
- Survived取0和1两个值,分别代表乘客在此次事故中死亡或存活。先将其转化为因子变量,再分别统计死亡和存活的人数比例。
结果显示,死亡人数比例约为62%,存活人数比例约为38%。
TrainData$Survived <- as.factor(TrainData$Survived)
ddply(TrainData,
.(Survived),
.fun = function(x){ c(rate = nrow(x)/nrow(TrainData))})
ggplot(TrainData, aes(x = Survived)) +
geom_bar(aes(fill = Survived)) +
geom_text(stat = 'count',
aes(label = scales::percent(..count../nrow(TrainData))),
vjust = 0)
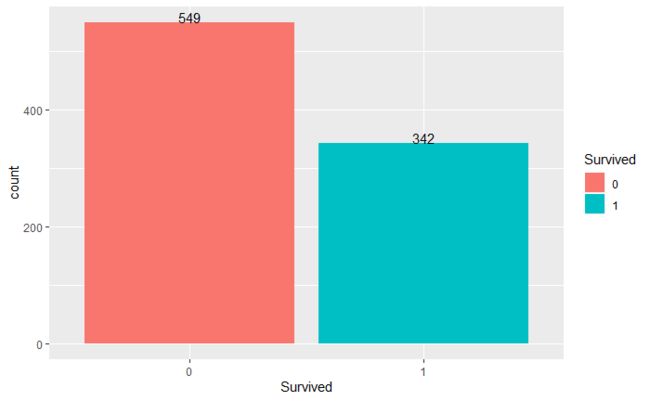
存活人数和遇难人数
| Survived | rate |
|---|---|
| 0 | 0.6161616 |
| 1 | 0.3838384 |
- Pclass代表乘客的船舱等级,1代表上等舱,2代表中等舱,3代表下等舱。先将其转化为因子变量,再分别统计每个阶层的人数比例。
结果显示,上等舱人数占比约为24%,中等舱人数占比约为21%,下等舱人数占比约为55%。
TrainData$Pclass <- as.factor(TrainData$Pclass)
ggplot(TrainData, aes(x = Pclass)) +
geom_bar(aes(fill = Pclass)) +
geom_text(stat = 'count',
aes(label = scales::percent(..count../nrow(TrainData))),
vjust = 0)

乘客在各个等级的船舱的数量分布
- Sex表示乘客的性别。在所有乘客中,约65%为男性,约35%为女性。男性人数接近女性人数的两倍。
ggplot(TrainData, aes(x = Sex)) +
geom_bar(aes(fill = Sex)) +
stat_count(aes(label = scales::percent(..count../nrow(TrainData))),
vjust=0,
geom="text",
position="identity")

男女乘客的数量分布
- Embarked代表乘客上船的地点,S是英国的南安普顿港,C是法国瑟堡,Q是爱尔兰昆士敦。从图中可以发现绝大多数乘客从南安普顿上的船,比例达72.3%。
ggplot(TrainData, aes(x = Embarked, fill = Embarked)) +
geom_bar(stat = 'count') +
geom_text(stat = 'count',
aes(label = scales::percent(..count../nrow(TrainData))),
vjust = 0)

在各个港口登船的乘客的数量分布
- Age表示乘客的年龄。暂不考虑缺失值,约50%的乘客的年龄位于20-40岁之间,为青壮年。最小的乘客还未满一岁。
ggplot(TrainData, aes(y = Age)) +
geom_boxplot(fill = 'cyan4')
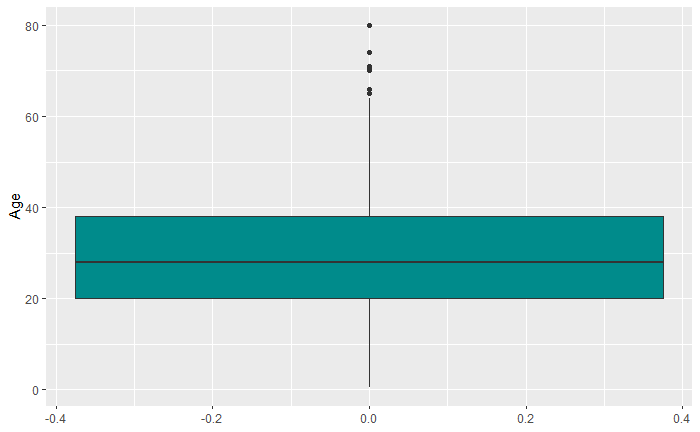
乘客的年龄分布
- SibSp表示一起在船上的兄弟姐妹和配偶的数量,Parch表示一起在船上的父母和孩子的数量。将它们放在一起考虑,构建新的特征:家庭规模(FamilySize)。结果显示,超过半数的乘客为独自一人,将近30%的乘客有一位或两位亲友陪同。
TrainData$FamilySize <- with(TrainData, SibSp + Parch + 1)
ggplot(TrainData, aes(x = factor(FamilySize), fill = factor(FamilySize))) +
geom_bar(stat = 'count') +
geom_text(aes(label = scales::percent(..count../nrow(TrainData))),
stat = 'count',
vjust = -0.5)
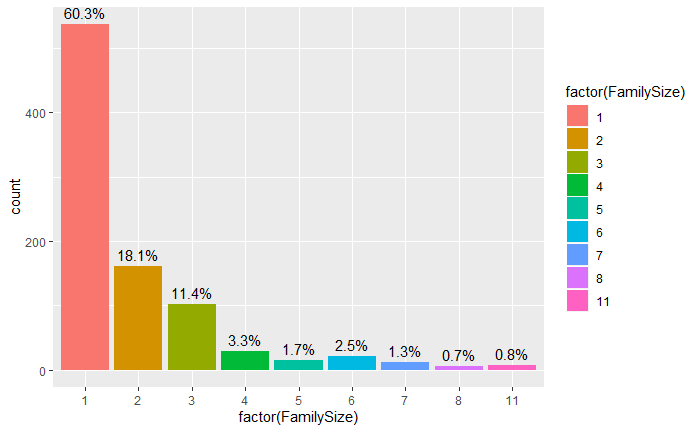
同船的家庭人数分布
- Ticket表示票号,Fare表示票价。在查看每列数据的信息时,发现部分票号存在重复,如一共有7位乘客的票号为‘1601’。结合票价信息和乘客的家庭人数,可知购买的票中团体票和家庭票,需要将票价平摊到每位乘客上。图中显示,75%的乘客票价低于25。
TrainData <- add_count(TrainData, Ticket, name='TicketCount')
TrainData$Fare <- with(TrainData, Fare/TicketCount)
TrainData <- TrainData[, -c(14)]
ggplot(TrainData, aes(y = Fare)) +
geom_boxplot(fill= 'cyan4')
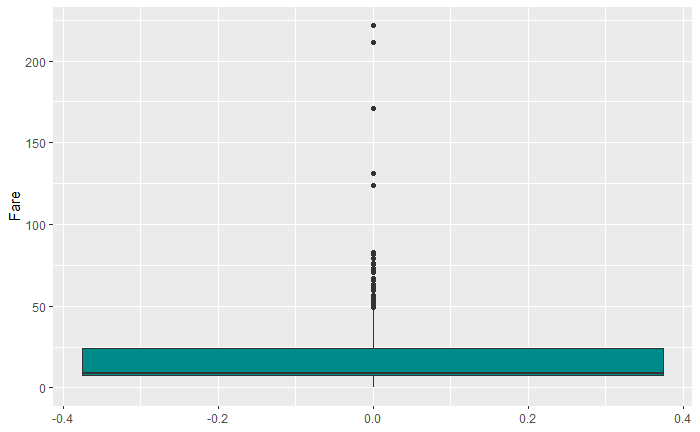
票价分布
- 观察乘客的名字信息,发现其中包括对乘客的称呼,如Mr、Mrs、Master等。称呼中隐含了乘客的性别、婚姻状况、身份以及社会地位等,所以有必要将其提取出来作为一个新的特征。结果显示,对乘客的称呼中,Mr占58%,代表普通男性;Miss占20%,代表未婚女性;Mrs占14%,代表已婚女性;Master占4.49%,代表有少爷、硕士或者师傅等头衔的人;其它的称呼所占比例都低于1%。
tmp <- str_match(TrainData$Name, pattern = ',(.+?)\\.')[ ,2]
TrainData$Title <- str_trim(tmp)
ddply(TrainData, .(Title),
.fun = function(x){c(Frac = scales::percent(nrow(x)/nrow(TrainData)))})

不同称号的乘客所占的比例
多变量分析
- 首先来看一下性别与存活率之间的关系。如图所示,女性乘客中存活率高达74.2%,男性乘客中存活率只有18.9%,前者明显高于后者,体现了在逃生时Lady First的人道主义原则。
SexSurviving <- ddply(TrainData, .(Sex),
summarize,
rate = mean(as.numeric(as.character(Survived))))
ggplot(SexSurviving, aes(x = Sex, y = rate, fill = Sex)) +
geom_bar(stat = 'identity') +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5)
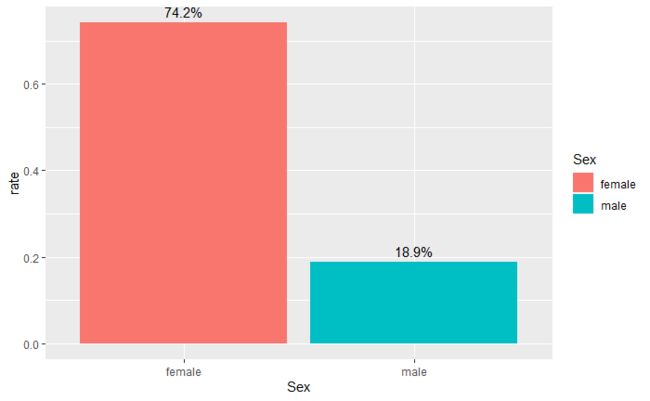
性别与存活率之间的关系
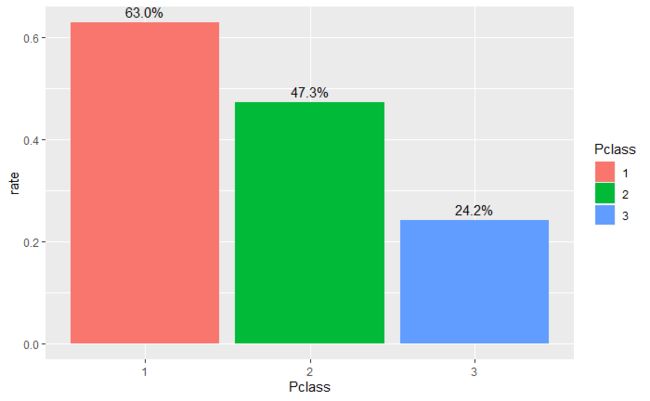
- 接着,再来看一下不同等级的船舱中乘客的存活率。上等舱乘客存活率最高,达到63.0%;中等舱次之,为47.3%;下等舱的最低,只有24.2%。这说明船舱的等级越高,乘客逃生的条件可能就更加有利。
PclassSurviving <- ddply(TrainData, .(Pclass),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(PclassSurviving, aes(x = Pclass, y = rate, fill = Pclass)) +
geom_bar(stat = 'identity') +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5)
不同等级的船舱中乘客的存活率
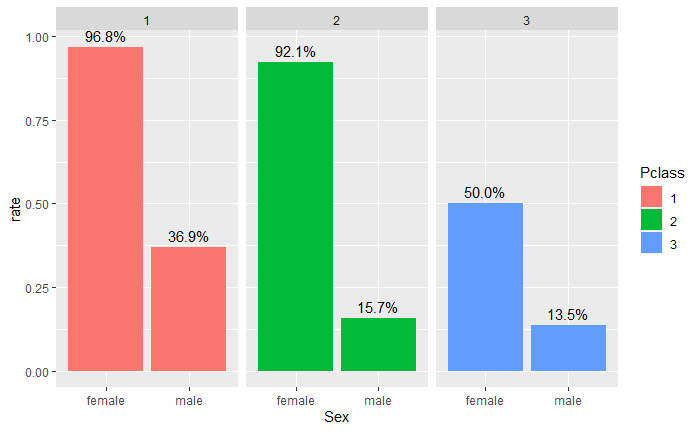
- 下图表示的是不同等级船舱中男女的生存率。在上等舱和中等舱中,女性乘客的存活比例分别高达96.8%和92.1%,只有少数几位女性乘客遇难,而同舱中男性乘客的存活比例则很低。这说明在上等舱和中等舱中,绝大多数逃生机会留给了女性,Lady First的原则体现得更加明显。
SexPclaSur <- ddply(TrainData, .(Sex, Pclass),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(SexPclaSur, aes(x = Sex, y = rate, fill = Pclass)) +
geom_bar(stat = 'identity') +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5) +
facet_wrap(~Pclass)
不同等级船舱中男女的生存率
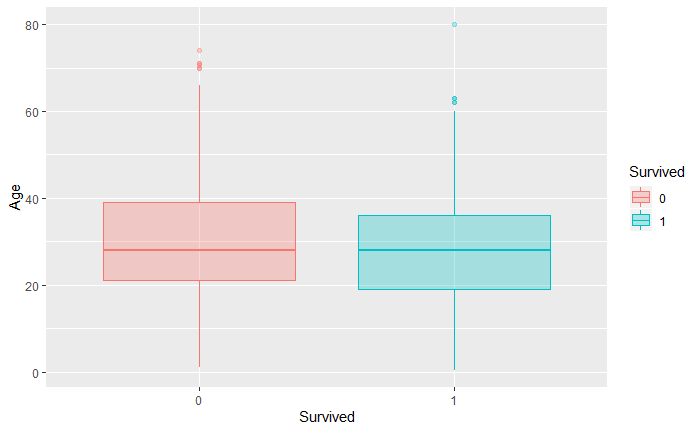
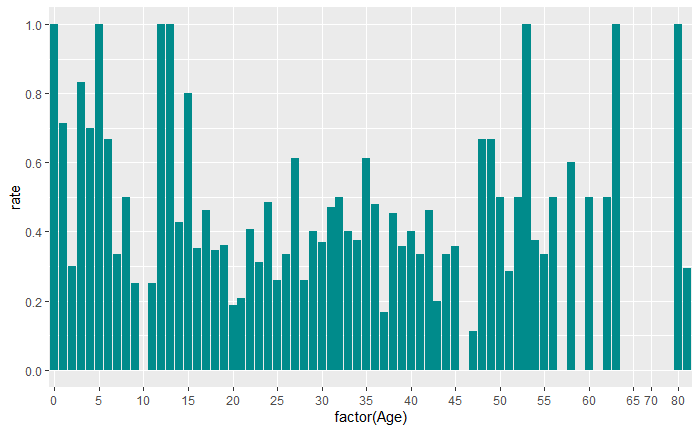
- 存活乘客和遇难乘客的年龄分布的中位数大致相当,都是28岁左右。在上四分位数和下四分位数上遇难乘客比存活乘客稍低。再来看各个年龄的存活率,不难看出年龄的两头(一老一幼)的存活率较高,有的甚至达到了100%,中间年龄段的存活率相对更低,说明在逃生时老幼乘客是处在优先位置的。
ggplot(TrainData, aes(x = Survived, y = Age, fill = Survived, color = Survived)) +
geom_boxplot(alpha = 0.3)
存活乘客和遇难乘客的年龄分布
tmp <- TrainData
tmp$Age <- as.integer(tmp$Age)
AgeSurviving <- ddply(tmp, .(Age),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(AgeSurviving, aes(x = factor(Age), y = rate)) +
geom_bar(stat = 'identity', fill = 'cyan4') +
scale_y_continuous(breaks=seq(0, 1, 0.2)) +
scale_x_discrete(breaks=seq(0, 80, 5))
各个年龄的存活率
- 对不同等级船舱里的存活乘客和遇难乘客的年龄分布进行研究,结果显示,从上等舱到下等舱,乘客的年龄呈下降的趋势,并且在每个等级的船舱里,存活乘客的年龄相较遇难乘客更加年轻化.
ggplot(TrainData, aes(x = Pclass, y = Age, fill = Survived, color = Survived)) +
geom_boxplot(alpha = 0.3)
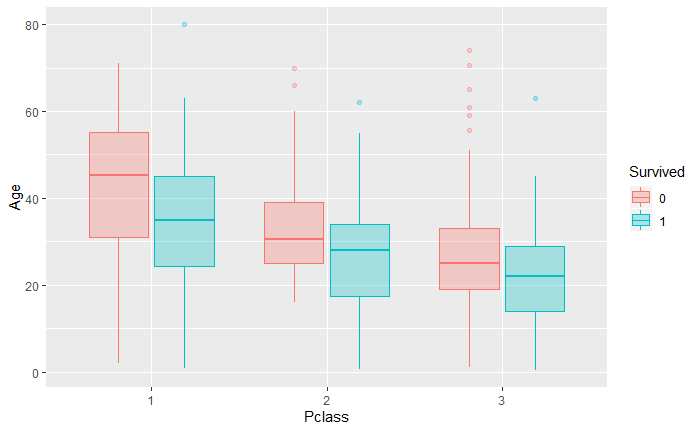
不同等级船舱里的存活乘客和遇难乘客的年龄分布
- 在研究称呼与存活率的关系之前,先来了解各种称呼代表着乘客的何种身份。
- Mr,先生
- Mrs,太太/夫人
- Miss,对未婚妇女用,
- Ms,美国近来用来称呼婚姻状态不明的妇女
- Mme,是Madame的简写,表夫人或太太
- Mlle, 小姐,未婚女子
- Lady, 女士,指成年女子
- Master,佣人对未成年男少主人的称呼,相当于汉语的"少爷"
- Don,西语中对贵族或有封号的男性平民的尊称
- jonkheer,贵族
- Rev = reverend,用于基督教的牧师
- Dr = doctor,医生/博士
- Col = Colonel,上校
- Major,少校
- Sir,贵族头衔,用于爵士或准男爵的名字或姓名前面
- The Countess,女伯爵
- Capt = Captain,某个组织的领导者,如船长、机长等
十七种称呼中有的称呼代表的乘客身份是类似的,所以需要对其进行归类。
- {Mr} : Mr,指普通男性
- {Mrs, Mme, Lady} : Mrs,指已经结婚的女性
- {Miss, Ms, Mlle} : Miss,指未结婚的女性
- {Master, Don, Jonkheer, Sir, the Countess} : Royalty,指贵族
- {Col, Major, Capt} : Officer,军官或者领导
- {Rev, Dr} - Specialist,某一领域的专家
结果显示,未结婚和已结婚的女性存活率最高,分别达70.3%和79.5%。其次是身份高贵的乘客和担任军官职位的乘客,存活率分别达56.8%和40%。最低的是普通男性乘客,存活率仅有15.7%。这不仅仅再一次体现了在逃生过程中女士优先的原则,也体现了社会地位更高的乘客获得了更好的逃生条件。
Mr <- c('Mr')
Mrs <- c('Mrs', 'Mme', 'Lady')
Miss <- c('Miss', 'Ms', 'Mlle')
Royalty <- c('Master', 'Don', 'Jonkheer', 'Sir', 'the Countess')
Officer <- c('Col', 'Major', 'Capt')
Specialist <- c('Rev', 'Dr')
TrainData[which(TrainData$Title %in% Mr), 14] <- 'Mr'
TrainData[which(TrainData$Title %in% Mrs), 14] <- 'Mrs'
TrainData[which(TrainData$Title %in% Miss), 14] <- 'Miss'
TrainData[which(TrainData$Title %in% Royalty), 14] <- 'Royalty'
TrainData[which(TrainData$Title %in% Officer), 14] <- 'Officer'
TrainData[which(TrainData$Title %in% Specialist), 14] <- 'Specialist'
tmp <- ddply(TrainData, .(Title),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(tmp, aes(x = Title, y = rate, fill = Title)) +
geom_bar(stat = 'identity') +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
geom_text(stat = 'identity',
aes(label = scales::percent(rate)),
vjust = 0)
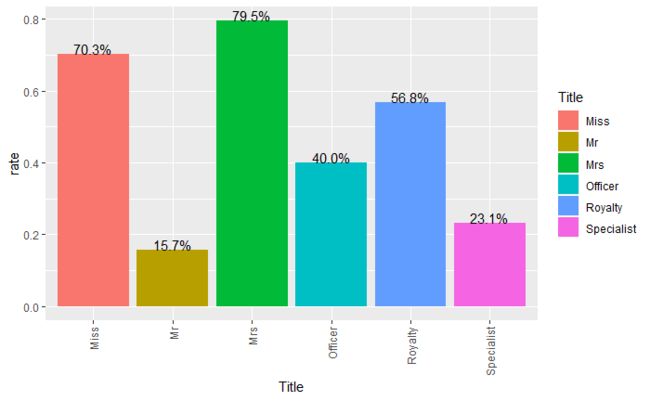
称呼与存活率的关系
- 乘客的家庭人数(包括乘客本人)与存活率关系图显示,当乘客的家庭人数在2-4人时,其存活率较高;当乘客是独自一人或者家庭人数过多时,其存活率相对低很多。这可能是因为在逃生过程中,小规模的家庭能够互相帮助,互相安抚情绪,从而获得更高的逃生成功率。而独自一人的乘客和家庭规模很大的乘客,要么孤立无援,要么人太多行动缓慢,其逃生成功率大大降低。
tmp <- ddply(TrainData, .(FamilySize),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(tmp, aes(x = factor(FamilySize), y = rate, group = 1)) +
geom_line(color = 'brown2') +
geom_point(size = 2) +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5)
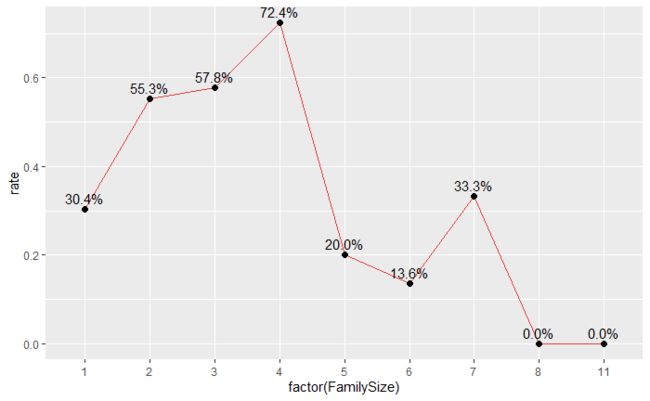
乘客的家庭人数(包括乘客本人)与存活率的关系
- 不同船舱等级的票价分布图显示,从上等舱到下等舱,票价不断下降,这与我们的常识是相符的。并且还发现,上等舱与中等舱的票价差,比中等舱与下等舱的票价差要大很多,这说明上等舱主要是面向少部分富有的乘客,而中等舱和下等舱面向的是数量更多的普通乘客。在存活乘客和遇难乘客的票价分布图中,存活乘客的票价分布要比遇难乘客的票价分布偏贵,这与之前分析得到的船舱等级越高乘客存活率越高是相契合的。
ggplot(TrainData, aes(x = Pclass, y = Fare, fill = Pclass, color = Pclass)) +
geom_boxplot(alpha = 0.5)
ggplot(TrainData, aes(x = Survived, y = Fare, fill =Survived, color = Survived)) +
geom_boxplot(alpha = 0.5)
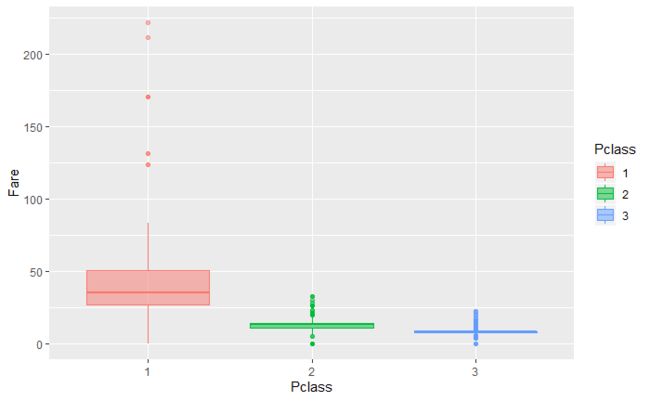
不同船舱等级的票价分布
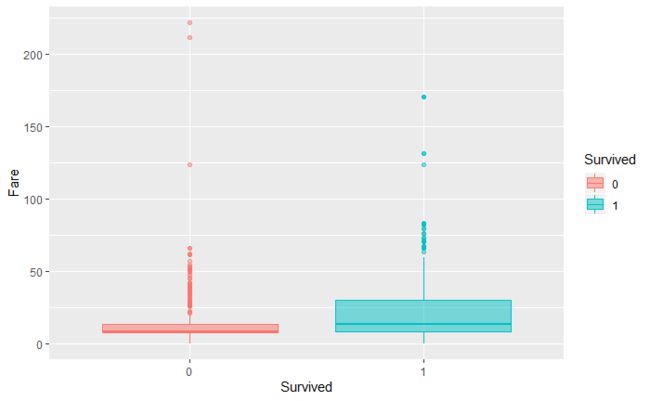
存活乘客和遇难乘客的票价分布图
- 从登陆港口与存活率的折线图中可以看出,乘客在不同的港口上船,生还率是不同的。瑟堡最高,昆士敦次之,南安普顿最低。可能的原因是在法国瑟堡登船的乘客中头等舱乘客的比例在三个港口中是最高的。
tmp <- ddply(TrainData[!is.na(TrainData$Embarked), ], .(Embarked),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(tmp, aes(x = Embarked, y = rate, group = 1)) +
geom_line(color = 'brown2', na.rm = TRUE) +
geom_point(size = 2, na.rm = TRUE) +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5)
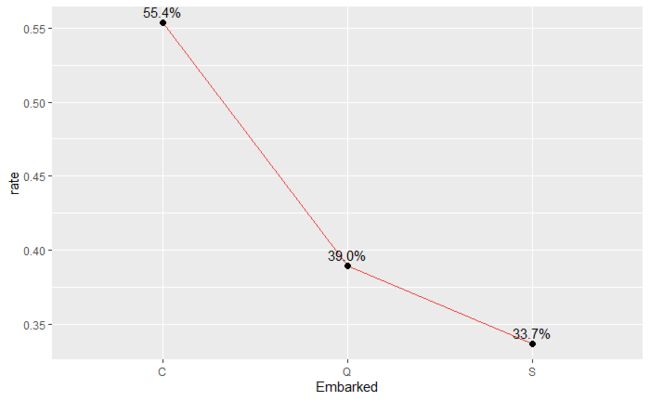
登陆港口与存活率的折线图
- 前面提到Cabin列有76%的缺失数据,从统计学的角度来看,船舱号缺失并不一定代表该数据遗漏掉了,有可能是该名乘客本来就没有船舱,就有点像火车上的站票一样。为了减少信息的损失,对有船舱号的乘客和船舱号缺失的乘客的成活率进行分析,发现有船舱号的乘客的存活率是船舱号缺失的乘客的两倍,说明有船舱号的乘客可能占据了更有利的逃生条件。
TrainData$HasCabin <- as.factor(as.numeric(!is.na(TrainData$Cabin)))
tmp <- ddply(TrainData, .(HasCabin),
summarise,
rate = mean(as.numeric(as.character(Survived))))
ggplot(tmp, aes(x = HasCabin, y = rate, fill =HasCabin)) +
geom_bar(stat = 'identity', alpha = 0.5) +
geom_text(aes(label = scales::percent(rate)), vjust = -0.5) +
scale_fill_discrete(labels = c('No', 'Yes'))

有船舱号的乘客和船舱号缺失的乘客的成活率
总结
在泰坦尼克号事件中,一个乘客存活几率的大小,受到许多因素的影响。当乘客的性别为女、乘客买的是上等舱,乘客的社会地位高、乘客是儿童老人,乘客
从法国瑟堡上的船,或者乘客的船舱号数据没有缺失的时候,乘客的存活率相对较高。