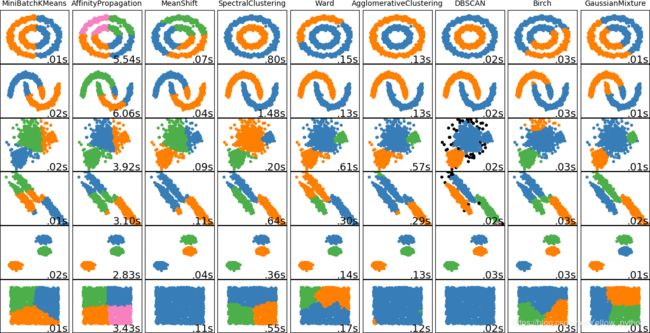
1、常见聚类方法简介
聚类是机器学习中一种重要的无监督算法,它可以将数据点归结为一系列特定的组合。在数据科学中聚类会从数据中发掘出很多分析和理解的视角,让我们更深入的把握数据资源的价值、并据此指导生产生活。
在聚类的过程中,我们要严防变量的相关性,相关性会影响聚类的效果。比如说聚类的时候交易次数和交易金额呈现相关性,我们应该只取其中的一个变量。
常见的聚类方法有【5】:
k-means:计算数据点与剧类中心的距离
dbscan:邻域内点的数量满足阈值则此点成为核心点并以此开始新一类的聚类
Mean-Shift(均值漂移算法:通过计算滑窗内点的均值更新滑窗的中心点。最终消除临近重复值的影响并形成中心点
高斯混合模型:通过假设数据点符合均值和标准差描述的高斯混合模型来实现的
层次聚类法:有自顶向下和自底向上两种方式。其中自底向上的方式,最初将每个点看做是独立的类别,随后通过一步步的凝聚最后形成独立的一大类,并包含所有的数据点。这会形成一个树形结构,并在这一过程中形成聚类。
(待全部熟悉后整理成表格形式)
2、dbscan原理【1】
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
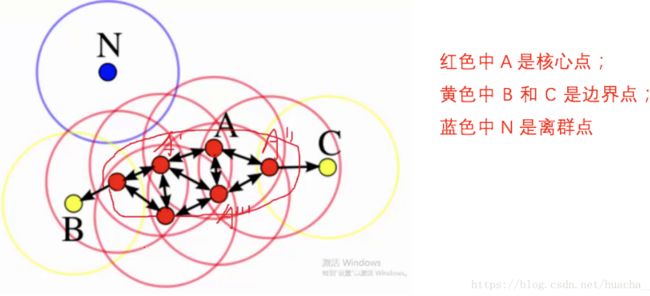
下面这些点是分布在样本空间的众多样本,现在我们的目标是把这些在样本空间中距离相近的聚成一类。我们发现A点附近的点密度较大,红色的圆圈根据一定的规则在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。其它没有被收纳的根据一样的规则成簇。(形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。
上面提到了红色圆圈滚啊滚的过程,这个过程就包括了DBSCAN算法的两个参数:
半径r:即圈的大小(多维的时候,r为按照多维向量计算的欧式距离)
最小点数MinPts:这个参数就是圈住的点的个数,也相当于是一个密度
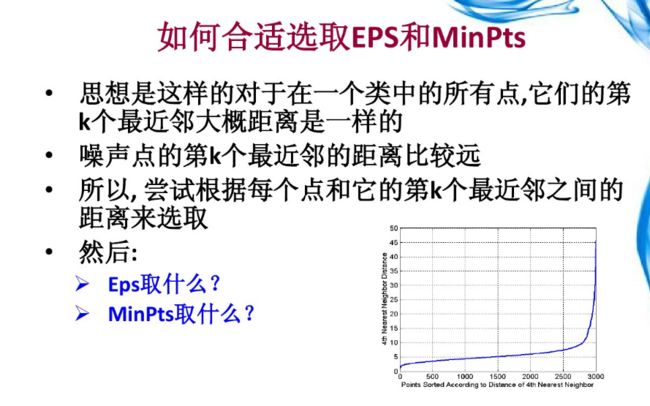
这两个参数比较难指定,公认的指定方法简单说一下:
最小点数MinPts:一般这个值都是先设置偏小一些,然后进行多次尝试
半径r:半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点,比如:

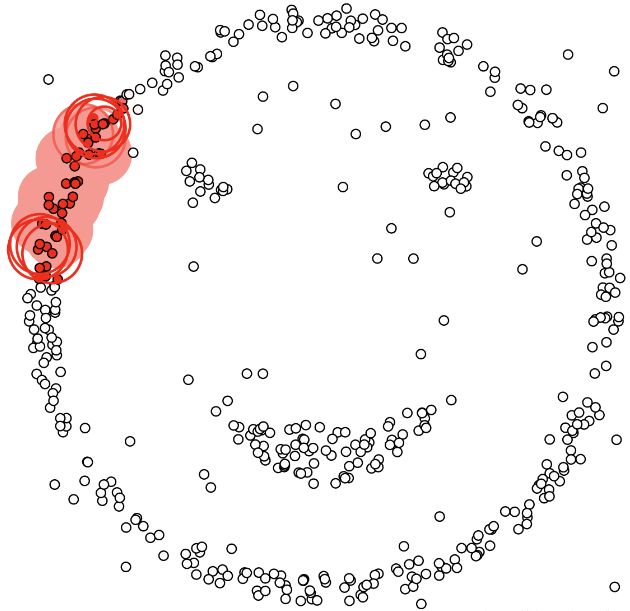
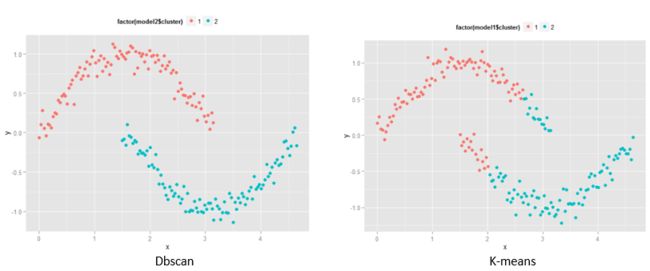
基于密度这点有什么好处呢,我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,是不规则的形状,这个时候,那些传统的聚类算法显然就悲剧了。于是就思考,样本密度大的成一类呗。呐这就是DBSCAN聚类算法。
不过,dbscan也会将一些有偏差的点给判断成离群点:即当数据密度变化剧烈时,不同类别的密度阈值点和领域半径会产生很大的变化,在高维空间中准确估计领域半径是较为困难的。
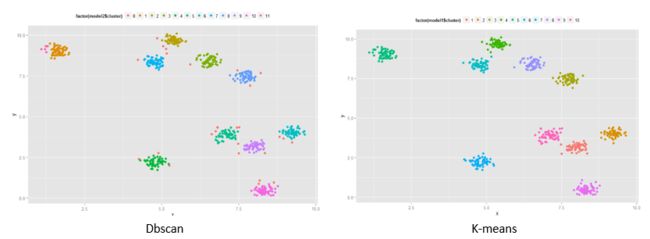
3、dbscan过程的可视化
从这个互动模型中你可以清楚的感受到dbscan方法的原理【2】:
DBSCAN算法过程可视化
可以用轮廓系数来评估聚类的效果【6】:

s(i) 接近1:样本i聚类合理
s(i) 接近-1:样本i更适合分到别的簇
s(i)接近0:样本i在两个簇的边界上
4、python实际使用与关注事项【1】
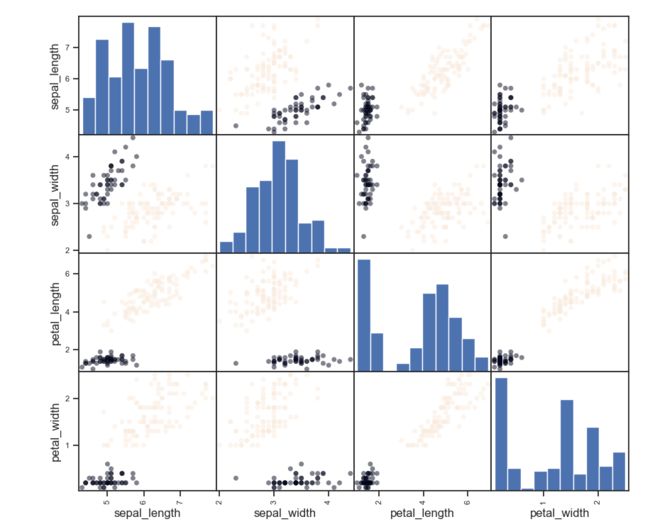
用iris数据集进行聚类,4维空间难以直接可视化,两两变量观察如下,实际上给分成了4类:
import seaborn
import pandas as pd
from sklearn.clusterimport DBSCAN
df= sns.load_dataset("iris")
X = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
db = DBSCAN(eps=1.0, min_samples=3).fit(X)
labels = db.labels_
df['cluster_db'] = labels
df.sort_values('cluster_db')
print(pd.scatter_matrix(X, c=df.cluster_db, figsize=(10,10), s=100))
轮廓系数计算:
from sklearn import metrics
score = metrics.silhouette_score(X,df.cluster_db)
5、其它的补充

参考资料
【1】https://blog.csdn.net/huacha__/article/details/81094891 DBSCAN聚类算法——机器学习(理论+图解+python代码)
【2】https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/ DBSCAN算法过程可视化
【3】https://www.naftaliharris.com/blog/visualizing-k-means-clustering/ k-means算法过程可视化
【4】https://www.cnblogs.com/hdu-2010/p/4621258.html 基于密度聚类的DBSCAN和kmeans算法比较
【5】http://m.elecfans.com/article/683501.html 机器学习中五种常用的聚类算法
【6】https://baike.baidu.com/item/%E8%BD%AE%E5%BB%93%E7%B3%BB%E6%95%B0/17361607?fr=aladdin 轮廓系数
【7】https://blog.csdn.net/Yellow_python/article/details/81461056 sklearn各聚类算法比较