0. 普通分布式文件系统设计思路
- 文件以多副本的方式,整个文件存放到单机中。
- 缺点:
- 文件不管有多大都存储在一个节点上,在进行数据处理的时候很难进行并行处理,节点可能就称为网络瓶颈,很难进行大数据处理;
- 存储负载很难均衡,每个节点的利用率很低;
1. HDFS概述及设计目标
- 什么是HDFS
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
- 源自于Google的GFS论文。
- 发表于2003年,HDFS是GFS的克隆版。
- HDFS的设计目标
- 非常巨大的分布式文件系统。
- 运行在普通廉价的硬件上。
- 易扩展、为用户提供性能不错的文件系统服务。
2. HDFS架构
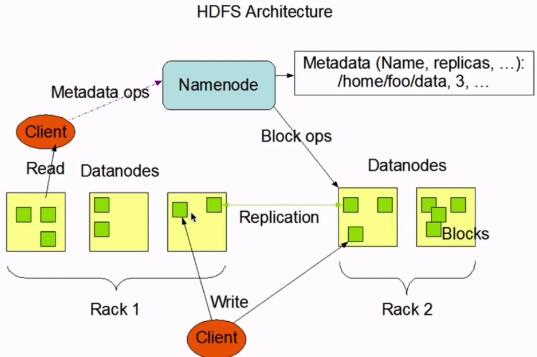
hdfs架构.jpg
- HDFS是一个Master(NameNode/NN)/Slave(DateNode/DN)(一个Master带多个Slaves)
- 一个文件会被拆分成多个Block(BlockSize,按照大小拆分),存放多节点;
- NameNode:
- 负责客户端请求的相应
- 负责元数据(文件的名称、副本系数、Block存放的DataNode)的管理
- 管理副本的复制
- DateNode:
- 存储用户的文件对应的数据块(Block)。
- 要定期想NameNode发送心跳信息,汇报本身及其所有的block信息,健康状况。
- A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software.(一个NameNode多个DateNode)
- The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.(生产建议NameNode和DateNode部署在不同机器上);
- replication factor:副本系统、副本因子
- All blocks in a file except the last block are the same size.
3. HDFS副本机制
-
创建和配置
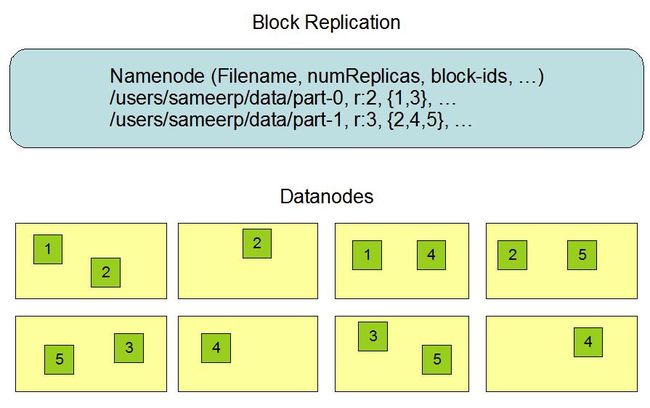 hdfs副本机制.jpg
hdfs副本机制.jpg -
副本存放策略
-
会随机挑选机架和机器(优先选择不同机架和机器存放数据)
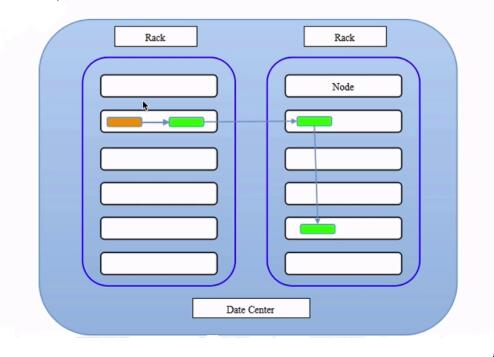 hdfs副本存放策略.jpg
hdfs副本存放策略.jpg
-
4. HDFS环境搭建(伪分布式)
-
JDK安装
- 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app
- 添加到系统环境变量: ~/.bash_profile
- export JAVA_HOME=/home/hadoop/app/jdk1.7.0_70
- export PATH=$JAVA_HOME/bin:$PATH
- 使环境变量生效: source ~/.bash_profile
- 验证java是否安装完成:java -v
-
Hadoop安装
下载地址:http://hadoop.apache.org/releases.html
使用ftp工具上传至Linux服务器
tar -zxvf解压到/usr/local/hadoop目录
-
修改/usr/local/hadoop/etc/hadoop/core-site.xml
fs.defaultFS hdfs://localhost:9000 -
修改修改/usr/local/hadoop/etc/hadoop/core-site.xml
dfs.replication 1
-
SSH安装
- 使用yum安装ssh客户端: yum install ssh
- 设置linux免密登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys -
初始化HDFS
$ bin/hdfs namenode -format -
启动HDFS
$ sbin/start-dfs.sh -
验证是否启动成功
$ jps 2356 NameNode 2695 SecondaryNameNode 12314 Jps 2477 DataNode- 出现NameNode,DataNode,SecondaryNameNode表示启动成功。
5. HDFS shell
-
HDFS Shell命令列表
hdfs dfs -appendToFile... # hdfs dfs -cat [-ignoreCrc] ... #查看文件内容 hdfs dfs -checksum ... hdfs dfs -chgrp [-R] GROUP PATH... hdfs dfs -chmod [-R] ] ... hdfs dfs -copyToLocal [-f] [-p] [-ignoreCrc] [-crc] ... hdfs dfs -count [-q] [-h] [-v] [-t [ ]] [-u] [-x] [-e] ... hdfs dfs -cp [-f] [-p | -p[topax]] [-d] ... #拷贝 hdfs dfs -createSnapshot [ ] hdfs dfs -deleteSnapshot hdfs dfs -df [-h] [ ...] hdfs dfs -du [-s] [-h] [-v] [-x] ... hdfs dfs -expunge hdfs dfs -find ... ... hdfs dfs -get [-f] [-p] [-ignoreCrc] [-crc] ... hdfs dfs -getfacl [-R] hdfs dfs -getfattr [-R] {-n name | -d} [-e en] hdfs dfs -getmerge [-nl] [-skip-empty-file] hdfs dfs -head hdfs dfs -help [cmd ...] hdfs dfs -ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [ ... #查看文件列表 hdfs dfs -mkdir [-p] ... #创建目录 hdfs dfs -moveFromLocal ... hdfs dfs -moveToLocal hdfs dfs -mv ... hdfs dfs -put [-f] [-p] [-l] [-d] ... #上传 hdfs dfs -renameSnapshot hdfs dfs -rm [-f] [-r|-R] [-skipTrash] [-safely] ... hdfs dfs -rmdir [--ignore-fail-on-non-empty] ... hdfs dfs -setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ] hdfs dfs -setfattr {-n name [-v value] | -x name} hdfs dfs -setrep [-R] [-w] ... hdfs dfs -stat [format] ... hdfs dfs -tail [-f] hdfs dfs -test -[defsz] hdfs dfs -text [-ignoreCrc] ... #查看文件内容 hdfs dfs -touchz ... hdfs dfs -truncate [-w] ... hdfs dfs -usage [cmd ...]
6. Java API操作HDFS
-
Windows远程连接Linux虚拟机HDFS环境配置
下载Hadoop并解压
修改/etc/hadoop/hadoop-env.cmd,设置环境变量
-
配置Hadoop环境变量,HADOOP_HOME
@rem The java implementation to use. Required. set JAVA_HOME=D:\software\jdk8u131
- 下载winutils,Windows Hadoop工具。
- 选择版本,解压拷贝到hadoop/bin目录下
- 查看是否配置成功,cmd下hadoop version输出版本信息
-
Windows Hadoop开发环境搭建,使用Maven
-
Pom配置
UTF-8 3.1.0 5.2.0 org.apache.hadoop hadoop-client ${hadoop.version} org.junit.jupiter junit-jupiter-api ${junit.version} test com.typesafe.play play-logback_2.12 2.6.15 cloudera https://repository.cloudera.com/artifactory/cloudera-repos/ -
将Linux中Hadoop配置文件拷贝到工程/resources目录下
- core-site.xml
- hdfs-site.xml
-
Junit Tests测试用例
import org.apache.commons.lang.ArrayUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.util.Progressable; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.*; import java.net.URI; /** * Hadoop HDFS Java API 操作 */ class HDFSApplicationTests { private static final Logger _LOGGER = LoggerFactory.getLogger(HDFSApplicationTests.class); private FileSystem fileSystem = null; private Configuration configuration = null; /** *初始化HDFS
* @throws Exception */ @BeforeEach void setUp () throws Exception { _LOGGER.info("HDFSApplicationTests#setUp"); configuration = new Configuration(); //修改host文件 URI uri = new URI("hdfs://ko-hadoop:8020"); fileSystem = FileSystem.get(uri, configuration, "K.O"); } /** *注销HDFS
* @throws Exception */ @AfterEach void tearDown () throws Exception { configuration = null; fileSystem = null; _LOGGER.info("HDFSApplicationTests#tearDown"); } /** *创建文件夹
* @throws IOException */ @Test void mkdir () throws IOException { fileSystem.mkdirs(new Path("/hdfsapi/test")); } /** *创建文件
*注意DataNode端口是否开启
* @throws IOException */ @Test void createFile () throws IOException { FSDataOutputStream outputStream = fileSystem.create(new Path("/hdfsapi/test/a.txt")); outputStream.write("Hello Hadoop!".getBytes()); outputStream.flush(); outputStream.close(); } /** *读取hdfs中文件数据
* @throws Exception */ @Test void cat () throws Exception { FSDataInputStream inputStream = fileSystem.open(new Path("/hdfsapi/test/a.txt")); byte[] b = new byte[1024]; inputStream.read(b); inputStream.close(); _LOGGER.info("HDFSApplicationTests#cat: {}", new String(b)); } /** *重命名文件
* @throws Exception */ @Test void rename () throws Exception { Path oldPath = new Path("/hdfsapi/test/a.txt"); Path newPath = new Path("/hdfsapi/test/b.txt"); boolean success = fileSystem.rename(oldPath, newPath); assert success; } /** *上传本地文件到HDFS服务器
* @throws Exception */ @Test void copyFromLocalFile () throws Exception { Path localPath = new Path("D:/tmp/hadoop.txt"); Path hdfsPath = new Path("/hdfsapi/test"); fileSystem.copyFromLocalFile(localPath, hdfsPath); } /** *上传本地文件到HDFS服务器, 带进度条
* @throws Exception */ @Test void copyFromLocalFileWithProgress () throws Exception { InputStream in = new BufferedInputStream( new FileInputStream( new File("D:/install/VMware-workstation-full-14.1.1-7528167.exe"))); FSDataOutputStream out = fileSystem.create(new Path("/hdfsapi/test/vmware-14.exe"), new Progressable() { public void progress() { System.out.print("-"); //带进度提醒信息 } }); IOUtils.copyBytes(in, out, 4096); } /** *下载HDFS文件
* @throws Exception */ @Test void copyToLocalFile () throws Exception { Path hdfsPath = new Path("/hdfsapi/test/b.txt"); Path localPath = new Path("D:/tmp/h.txt"); fileSystem.copyToLocalFile(hdfsPath, localPath); } /** *打印HDFS文件列表
* @throws Exception */ @Test void listFiles () throws Exception { FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/hdfsapi/test")); if (ArrayUtils.isNotEmpty(fileStatuses)) { for (FileStatus fileStatus : fileStatuses) { //1. 是否是文件夹 String isDir = fileStatus.isDirectory() ? "文件夹" : "文件"; //2. 有几个副本 short replication = fileStatus.getReplication(); //3. 文件大小 long len = fileStatus.getLen(); //4. 全路径 String path = fileStatus.getPath().toString(); //5. 输出 _LOGGER.info("文件夹还是文件? {}", isDir); _LOGGER.info("有{}个副本.", replication); _LOGGER.info("文件大小: {}kb", len); _LOGGER.info("全路径: {}", path); } } } /** *删除HDFS文件
* @throws Exception */ @Test void delete () throws Exception { boolean success = fileSystem.delete(new Path("/hdfsapi/test"), true); assert success; } }
-
7. HDFS文件读写流程
8. HDFS的优缺点
- HDFS的优点
- 数据冗余、硬件容错
- 处理流式的数据访问
- 适合处理大文件
- 存储在廉价的机器上
- HDFS的缺点
- 低延迟的数据访问
- 不适合小文件存储