Chatbot------用PyTorch做对话机器人
引用
[TOC]
导入头文件
使用了from __future__ import xxx可以在python2,python3环境下运行同一份代码而不出错,编写的时候使用python3规范即可。
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from __future__ import unicode_literals
进行数据处理
数据正规化
首先之前将句子中的单词都转换成小写并去处两边的空白格,接着将句子的unicode编码转换成Ascii编码,便于使用正则表达式对文本进行正规化,,再接着为了便于分词,所以我们将无效字符转换成我们能处理的字符,s = re.sub(r"([.!?])", r" \1", s)意思成将句号,感叹号,疑问号后面前面都加上一个空格,\1的意思是与之前()里面匹配的东西原封不动复制一下,所以原来匹配到的是句号那么这次还是句号,原来匹配到的是感叹号这次还是感叹号,s = re.sub(r"[^a-zA-Z.!?]+", r" ", s),意思是将不是大小写字母句号疑问号感叹号的非法字符全部用空格符替换,注意有个+号,是因为将所有连在一起的非法字符只替换一遍,所有加号一定不要忘了,s = re.sub(r"\s+", r" ", s).strip(),意思是将所有的空白符替换成空格,如果多个空白符连接在一起那么只替换一次。
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
s = re.sub(r"\s+", r" ", s).strip()
return s
读取数据
lines = open(datafile, encoding='utf-8').read().strip().split('\n'),datafile是一个query/response中间用\t分隔,
# Read query/response pairs and return a voc object
def readVocs(datafile, corpus_name):
print("Reading lines...")
# Read the file and split into lines
lines = open(datafile, encoding='utf-8').\
read().strip().split('\n')
# Split every line into pairs and normalize
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
voc = Voc(corpus_name)
return voc, pairs
代码写的很有灵性,判断pairs里面的句子长度是不是超过了最大长度,如果超过了最大长度那么就掉。
def filterPair(p):
# Input sequences need to preserve the last word for EOS token
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH
# Filter pairs using filterPair condition
def filterPairs(pairs):
return [pair for pair in pairs if filterPair(pair)]
读取并整合数据,voc就是一个大的单词对应表,里面有word2index,有word2count,有index2word
def loadPrepareData(corpus, corpus_name, datafile, save_dir):
print("Start preparing training data ...")
voc, pairs = readVocs(datafile, corpus_name)
print("Read {!s} sentence pairs".format(len(pairs)))
pairs = filterPairs(pairs)
print("Trimmed to {!s} sentence pairs".format(len(pairs)))
print("Counting words...")
for pair in pairs:
voc.addSentence(pair[0])
voc.addSentence(pair[1])
print("Counted words:", voc.num_words)
return voc, pairs
# Load/Assemble voc and pairs
save_dir = os.path.join("data", "save")
voc, pairs = loadPrepareData(corpus, corpus_name, datafile, save_dir)
# Print some pairs to validate
print("\npairs:")
for pair in pairs[:10]:
print(pair)
根据单词表对句子进行裁剪,首先先把单词表中词频小于MIN_COUNT的单词全部丢弃,然后对于句子判断如果句子中有词频过小的单词,那么整个句子也不用保留。
MIN_COUNT = 3 # Minimum word count threshold for trimming
def trimRareWords(voc, pairs, MIN_COUNT):
# Trim words used under the MIN_COUNT from the voc
voc.trim(MIN_COUNT)
# Filter out pairs with trimmed words
keep_pairs = []
for pair in pairs:
input_sentence = pair[0]
output_sentence = pair[1]
keep_input = True
keep_output = True
# Check input sentence
for word in input_sentence.split(' '):
if word not in voc.word2index:
keep_input = False
break
# Check output sentence
for word in output_sentence.split(' '):
if word not in voc.word2index:
keep_output = False
break
# Only keep pairs that do not contain trimmed word(s) in their input or output sentence
if keep_input and keep_output:
keep_pairs.append(pair)
print("Trimmed from {} pairs to {}, {:.4f} of total".format(len(pairs), len(keep_pairs), len(keep_pairs) / len(pairs)))
return keep_pairs
# Trim voc and pairs
pairs = trimRareWords(voc, pairs, MIN_COUNT)
将句子转换成Tensor
预处理的最后一步,在训练翻译模型的时候我们都是一个句子一个句子进行训练的,但是为了加速训练,最好还是使用Mini-batch进行训练,如果想要使用Mini-batch 进行训练,那么就要让一个batch里面的句子长度一样长,如果一个句子太短了,那么就在EOS_token后面进行0填充,,这样构建出来的Mini_batch的形状是batch_size*max_length,为了编写代码方便,我们需要batch[0]指示所有句子第一个单词(总共有batch_size个),所以我们还需要把这个Mini_batch`的矩阵转置一下。
- 将所有的单词转换成
index,然后加上表示结束的index---EOS_token。
def indexesFromSentence(voc, sentence):
return [voc.word2index[word] for word in sentence.split(' ')] + [EOS_token]
2.itertools.zip_longest函数第一个参数是聚合在一起的元素(l是一个二维矩阵,*l(解压操作)是去除最外面的中括号,所以就变成了一堆聚合在一起的元素了),函数第二个参数是要填充的字符值,函数功能是对长度不一样的聚合在一起的元素,使用fillvalue进行填充,填充成最大元素的长度。
itertools.zip_longest:Make an iterator that aggregates elements from each of the iterables. If the iterables are of uneven length, missing values are filled-in with fillvalue. Iteration continues until the longest iterable is exhausted.
def zeroPadding(l, fillvalue=PAD_token):
return list(itertools.zip_longest(*l, fillvalue=fillvalue))
- 制作掩码矩阵,填充的部分设置为0,非填充的部分设置为1。
def binaryMatrix(l, value=PAD_token):
m = []
for i, seq in enumerate(l):
m.append([])
for token in seq:
if token == PAD_token:
m[i].append(0)
else:
m[i].append(1)
return m
-
inputVar和outputVar是将一个batch的数据进行word和tensor的相互转换。inputVar,第一句是先将sentence转换成index矩阵,第二句是将创建和index矩阵同样大小的Tensor矩阵,torch.tensor([a,b,c,d])创建a * b * c * d大小的Tensor矩阵。接下来两句是对index矩阵进行填充,然后成成对应的Tensor矩阵,torch.LongTensor(list)创建一个和list同样形状的Tensor矩阵,batch2TrainData就是将,随机采样到的小批数据,生成训练中需要的tensor数据。
# Returns padded input sequence tensor and lengths
def inputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
padVar = torch.LongTensor(padList)
return padVar, lengths
# Returns padded target sequence tensor, padding mask, and max target length
def outputVar(l, voc):
indexes_batch = [indexesFromSentence(voc, sentence) for sentence in l]
max_target_len = max([len(indexes) for indexes in indexes_batch])
padList = zeroPadding(indexes_batch)
mask = binaryMatrix(padList)
mask = torch.ByteTensor(mask)
padVar = torch.LongTensor(padList)
return padVar, mask, max_target_len
# Returns all items for a given batch of pairs
def batch2TrainData(voc, pair_batch):
pair_batch.sort(key=lambda x: len(x[0].split(" ")), reverse=True)
input_batch, output_batch = [], []
for pair in pair_batch:
input_batch.append(pair[0])
output_batch.append(pair[1])
inp, lengths = inputVar(input_batch, voc)
output, mask, max_target_len = outputVar(output_batch, voc)
return inp, lengths, output, mask, max_target_len
# Example for validation
small_batch_size = 5
batches = batch2TrainData(voc, [random.choice(pairs) for _ in range(small_batch_size)])
input_variable, lengths, target_variable, mask, max_target_len = batches
print("input_variable:", input_variable)
print("lengths:", lengths)
print("target_variable:", target_variable)
print("mask:", mask)
print("max_target_len:", max_target_len)
构建模型
Encoder
nn.GRU(input_size,hidden_size,n_layers,...),第一个参数输入vector的长度,第二个根据GRU的计算公式,是输出和隐藏vector的长度(因为是上一个time_step的输出和这个阶段的h共同组合成这个阶段的输出),n_layers就是需要堆叠的GRU的层数,如果大于1的话,就是将n层GRU摞起来,nn.Embedding(voc_size,dimension,..),第一个参数是表示需要embedding的单词的数目,dimension是embedding之后每一个单词的vector的长度,torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False),将一个填充过的tensor打包起来,input的形状是max_length * batch_size,如果batch_first=True则更换两者的顺序,并且输入是一个已经排好序(降序)的tensor矩阵,长的在前,短的在后,lengths是batch中输入序列每个元素的长度的一个列表,这一函数的作用就是打包,进行批处理(将多个Tensor结合在一起,而且排序也是很有必要的,能和原来的元素一对应起来),torch.nn.utils.rnn.pad_packed_sequence,是上个函数的逆操作,相当于解压操作,接下来一句,因为我们使用的是双向的LSTM所以会有两倍的输出,我们将其相加起来组成最后的输出,。
Packs a Tensor containing padded sequences of variable length.Input can be of size T x B x * where T is the length of the longest sequence (equal to lengths[0]), B is the batch size, and * is any number of dimensions (including 0). If batch_first is True B x T x * inputs are expected.The sequences should be sorted by length in a decreasing order, i.e. input[:,0] should be the longest sequence, and input[:,B-1] the shortest one.This function accepts any input that has at least two dimensions. You can apply it to pack the labels, and use the output of the RNN with them to compute the loss directly.
class EncoderRNN(nn.Module):
def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = embedding
# Initialize GRU; the input_size and hidden_size params are both set to 'hidden_size'
# because our input size is a word embedding with number of features == hidden_size
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
def forward(self, input_seq, input_lengths, hidden=None):
# Convert word indexes to embeddings
embedded = self.embedding(input_seq)
# Pack padded batch of sequences for RNN module
packed = torch.nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
# Forward pass through GRU
outputs, hidden = self.gru(packed, hidden)
# Unpack padding
outputs, _ = torch.nn.utils.rnn.pad_packed_sequence(outputs)
# Sum bidirectional GRU outputs
outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
# Return output and final hidden state
return outputs, hidden
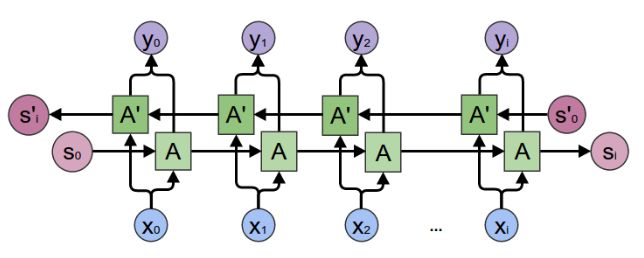
Attention
完成了一个关于注意力机制的类,这样就不用每个模型都写一个attention了,拿来即用,W是一个矩阵变换,在函数中相当于torch.nn.Linear,就是实现这个W转换,所以在__init__里面的首先要初始化这个能进行W变换的submodule,torch.nn.Linear(in_features, out_features, bias=True),以general为例,in_features是h_hat_s的长度,out_features就是经过线性变换以后特征的维度,(hidden.expand(encoder_output.size(0), -1, -1),作用是将某一个维度是1的维扩大到指定的维度,这个例子中hidden 的形状是1*n*m ,然后扩展到encoder_output.size(0)*n*m,-1表示不扩展这个维度,值得注意的是扩展维度并不会多耗费内存,只是更改了视图(view)把stride设置为0,torch.cat(A,B,n)表示在第n维上连接两个tensor,torch.sum(input,dims,keepdim=False...)表示在维度(可以为一个列表)上进行加法,并使用torch.squeeze()对结果进行挤压,如果keepdim=True则不进行挤压,tensor.t()对tensor进行转置,这个函数只能对tensor是二维张量,将矩阵进行转置,
that have a very special property when used with Module s - when they’re assigned as Module attributes they are automatically added to the list of its parameters, and will appear e.g. in parameters() iterator. Assigning a Tensor doesn’t have such effect.
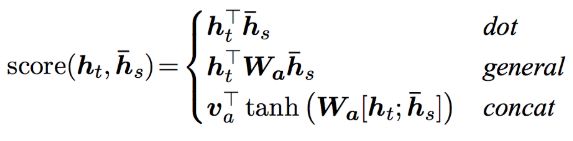 @三种attention方式|center
@三种attention方式|center
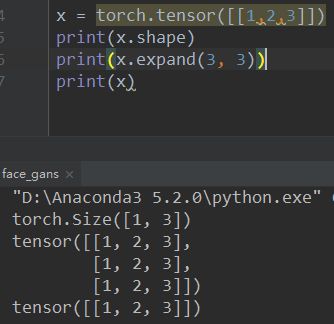 @tensor.expand()|center
@tensor.expand()|center
# Luong attention layer
class Attn(torch.nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = torch.nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = torch.nn.Linear(self.hidden_size * 2, hidden_size)
self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# Calculate the attention weights (energies) based on the given method
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# Transpose max_length and batch_size dimensions
attn_energies = attn_energies.t()
# Return the softmax normalized probability scores (with added dimension)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
Decoder
nn.Dropout(),embedded = self.embedding_dropout(embedded)就是随机归0一些tensor,tensorA.bmm(tensorB)相当于torch.bmm(tensorA,tensorB)都是对两个tensor进行批量相乘,注意第一维度是batch_size,tensor.squeeze(tensorA,dim=None),如果不指定维度那么会将张量里面的所有维度为1的全部消除[2,1,2,1,2]->[2,2,2],如果指定了dim=1,[2,1,2,1,2]->[2,2,1,2]。torch.tanh的目的是加入一些非线性变换,注意rnn_output, hidden = self.gru(embedded, last_hidden)这里得到的是一个时间步里面的结果,每次一个输出和一个隐藏状态,做.transpose(0,1)也是因为训练的时候batch_size在第一维现在要求是第零维。。
m = nn.Dropout(p=0.2)
input = torch.randn(20, 16)
output = m(input)
print(output)
class AttnDecoderRNN(nn.Module):
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# Note: we run this one step (word) at a time
# Get embedding of current input word
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# Forward through unidirectional GRU
rnn_output, hidden = self.gru(embedded, last_hidden)
# Calculate attention weights from the current GRU output
attn_weights = self.attn(rnn_output, encoder_outputs)
# Multiply attention weights to encoder outputs to get new "weighted sum" context vector
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# Concatenate weighted context vector and GRU output using Luong eq. 5
rnn_output = rnn_output.squeeze(0)
context = context.squeeze(1)
concat_input = torch.cat((rnn_output, context), 1)
concat_output = torch.tanh(self.concat(concat_input))
# Predict next word using Luong eq. 6
output = self.out(concat_output)
output = F.softmax(output, dim=1)
# Return output and final hidden state
return output, hidden
LossFunction
torch.gather(input, dim, index, out=None),这个函数的作用是将input按照dim所指定的维度,按照index中的次序进行收集,输出的尺寸和index是一样的,比如下面的例子dim=1指示对input的第1维进行收集,且有2个第一维,所以index的尺寸是2*n,此处n=2,指示了每个第一维元素应该如何收集([1,2]按照[0,0]收集,[3,4]按照[0,1]收集),input和index的维度,只能是dim所指示的哪一个维度可以不一样,其他的必须完全一样。tensor.masked_select(mask).mean(),torch.masked_select(input, mask, out=None) → Tensor,将input按照mask的中为1的元素的顺序收集成一个一维的tensor,mask不是必须要和input同一纬度,但是必须是可以broadcastable。
If input is an n-dimensional tensor with size (x0,x1...,xi−1,xi,xi+1,...,xn−1) and dim =i, then index must be an n-dimensional tensor with size (x0,x1,...,xi−1,y,xi+1,...,xn−1) where y≥1 and out will have the same size as index.
Returns a new 1-D tensor which indexes the input tensor according to the binary mask mask which is a ByteTensor.The shapes of the mask tensor and the input tensor don’t need to match, but they must be broadcastable.
>>> t = torch.tensor([[1,2],[3,4]])
>>> torch.gather(t, 1, torch.tensor([[0,0],[1,0]]))
tensor([[ 1, 1],
[ 4, 3]])
>>> x = torch.randn(3, 4)
>>> x
tensor([[ 0.3552, -2.3825, -0.8297, 0.3477],
[-1.2035, 1.2252, 0.5002, 0.6248],
[ 0.1307, -2.0608, 0.1244, 2.0139]])
>>> mask = x.ge(0.5)
>>> mask
tensor([[ 0, 0, 0, 0],
[ 0, 1, 1, 1],
[ 0, 0, 0, 1]], dtype=torch.uint8)
>>> torch.masked_select(x, mask)
tensor([ 1.2252, 0.5002, 0.6248, 2.0139])
def maskNLLLoss(inp, target, mask):
nTotal = mask.sum()
crossEntropy = -torch.log(torch.gather(inp, 1, target.view(-1, 1)))
loss = crossEntropy.masked_select(mask).mean()
loss = loss.to(device)
return loss, nTotal.item()
训练
一个时间步的训练
train指示一个Mini_batch的一个时间步的训练。tensor.topk(n),返回tensor最大的n个数及其下标_, topi = decoder_output.topk(1),decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])此处的是一个batch,所以先取到topi[i]在top[i].item()取出元素。torch.nn.utils.clip_grad_norm_(decoder.parameters(), clip)进行梯度裁剪,防止梯度爆炸,第二个参数是max norm of the gradients,正规化以后梯度的最大值。
>>> x = torch.arange(1., 6.)
>>> x
tensor([ 1., 2., 3., 4., 5.])
>>> torch.topk(x, 3)
(tensor([ 5., 4., 3.]), tensor([ 4, 3, 2]))
def train(input_variable, lengths, target_variable, mask, max_target_len, encoder, decoder, embedding,
encoder_optimizer, decoder_optimizer, batch_size, clip, max_length=MAX_LENGTH):
# Zero gradients
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# Set device options
input_variable = input_variable.to(device)
lengths = lengths.to(device)
target_variable = target_variable.to(device)
mask = mask.to(device)
# Initialize variables
loss = 0
print_losses = []
n_totals = 0
# Forward pass through encoder
encoder_outputs, encoder_hidden = encoder(input_variable, lengths)
# Create initial decoder input (start with SOS tokens for each sentence)
decoder_input = torch.LongTensor([[SOS_token for _ in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Set initial decoder hidden state to the encoder's final hidden state
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Determine if we are using teacher forcing this iteration
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# Forward batch of sequences through decoder one time step at a time
if use_teacher_forcing:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# Teacher forcing: next input is current target
decoder_input = target_variable[t].view(1, -1)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
else:
for t in range(max_target_len):
decoder_output, decoder_hidden = decoder(
decoder_input, decoder_hidden, encoder_outputs
)
# No teacher forcing: next input is decoder's own current output
_, topi = decoder_output.topk(1)
decoder_input = torch.LongTensor([[topi[i][0] for i in range(batch_size)]])
decoder_input = decoder_input.to(device)
# Calculate and accumulate loss
mask_loss, nTotal = maskNLLLoss(decoder_output, target_variable[t], mask[t])
loss += mask_loss
print_losses.append(mask_loss.item() * nTotal)
n_totals += nTotal
# Perform backpropatation
loss.backward()
# Clip gradients: gradients are modified in place
_ = torch.nn.utils.clip_grad_norm_(encoder.parameters(), clip)
_ = torch.nn.utils.clip_grad_norm_(decoder.parameters(), clip)
# Adjust model weights
encoder_optimizer.step()
decoder_optimizer.step()
return sum(print_losses) / n_totals
训练
training_batches = [batch2TrainData(voc, [random.choice(pairs) for _ in range(batch_size)]) for _ in range(n_iteration)],首先把所有的训练数据采样下来。然后每个循环拿出一小批数据进行训练。if loadFilename:start_iteration = checkpoint['iteration'] + 1很有灵性的写法,虽然感觉用处不会很大,input_variable, lengths, target_variable, mask, max_target_len = training_batch,从training_batch中取出各个字段。保存数据这一段写的太经典了。
if (iteration % save_every == 0):
directory = os.path.join(save_dir, model_name, corpus_name, '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size))
if not os.path.exists(directory):
os.makedirs(directory)
torch.save({
'iteration': iteration,
'en': encoder.state_dict(),
'de': decoder.state_dict(),
'en_opt': encoder_optimizer.state_dict(),
'de_opt': decoder_optimizer.state_dict(),
'loss': loss,
'voc_dict': voc.__dict__,
'embedding': embedding.state_dict()
}, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))
def trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer, embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size, print_every, save_every, clip, corpus_name, loadFilename):
# Load batches for each iteration
training_batches = [batch2TrainData(voc, [random.choice(pairs) for _ in range(batch_size)])
for _ in range(n_iteration)]
# Initializations
print('Initializing ...')
start_iteration = 1
print_loss = 0
if loadFilename:
start_iteration = checkpoint['iteration'] + 1
# Training loop
print("Training...")
for iteration in range(start_iteration, n_iteration + 1):
training_batch = training_batches[iteration - 1]
# Extract fields from batch
input_variable, lengths, target_variable, mask, max_target_len = training_batch
# Run a training iteration with batch
loss = train(input_variable, lengths, target_variable, mask, max_target_len, encoder,
decoder, embedding, encoder_optimizer, decoder_optimizer, batch_size, clip)
print_loss += loss
# Print progress
if iteration % print_every == 0:
print_loss_avg = print_loss / print_every
print("Iteration: {}; Percent complete: {:.1f}%; Average loss: {:.4f}".format(iteration, iteration / n_iteration * 100, print_loss_avg))
print_loss = 0
# Save checkpoint
if (iteration % save_every == 0):
directory = os.path.join(save_dir, model_name, corpus_name, '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size))
if not os.path.exists(directory):
os.makedirs(directory)
torch.save({
'iteration': iteration,
'en': encoder.state_dict(),
'de': decoder.state_dict(),
'en_opt': encoder_optimizer.state_dict(),
'de_opt': decoder_optimizer.state_dict(),
'loss': loss,
'voc_dict': voc.__dict__,
'embedding': embedding.state_dict()
}, os.path.join(directory, '{}_{}.tar'.format(iteration, 'checkpoint')))
模型评估
贪婪搜索
decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_toke,*一个常数就是将tensor的每一个元素都乘以这个常数,做成1*1的tensor可能就是因为说明这一批就只有一个元素,torch.max(input,dim),返回inputTensor中指定维度的最大值以及下标,如果不指定维度那么只返回最大的数,这个指定维度是便利所有元素值所得到的最大的元素,是总体的最大元素,所以input的维度可以是m*n,贪婪搜索decoder只用将所有的输入序列进行一次encoder,但是对decoder要运行max_length次,比较有意思的事是,all_tokens首先谁初始化成起始符0,然后每次将最有可能的那个词使用torch.cat连接起来,因为torch.max输出的decoder_input是一维的,而输入要求是二维的所有还要使用torch.unsqueeze进行扩维。
>>> a = torch.randn(4, 4)
>>> a
tensor([[-1.2360, -0.2942, -0.1222, 0.8475],
[ 1.1949, -1.1127, -2.2379, -0.6702],
[ 1.5717, -0.9207, 0.1297, -1.8768],
[-0.6172, 1.0036, -0.6060, -0.2432]])
>>> torch.max(a, 1)
(tensor([ 0.8475, 1.1949, 1.5717, 1.0036]), tensor([ 3, 0, 0, 1]))
>>> a = torch.randn(1, 3)
>>> a
tensor([[ 0.6763, 0.7445, -2.2369]])
>>> torch.max(a)
tensor(0.7445)
class GreedySearchDecoder(nn.Module):
def __init__(self, encoder, decoder):
super(GreedySearchDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input_seq, input_length, max_length):
# Forward input through encoder model
encoder_outputs, encoder_hidden = self.encoder(input_seq, input_length)
# Prepare encoder's final hidden layer to be first hidden input to the decoder
decoder_hidden = encoder_hidden[:decoder.n_layers]
# Initialize decoder input with SOS_token
decoder_input = torch.ones(1, 1, device=device, dtype=torch.long) * SOS_token
# Initialize tensors to append decoded words to
all_tokens = torch.zeros([0], device=device, dtype=torch.long)
all_scores = torch.zeros([0], device=device)
# Iteratively decode one word token at a time
for _ in range(max_length):
# Forward pass through decoder
decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden, encoder_outputs)
# Obtain most likely word token and its softmax score
decoder_scores, decoder_input = torch.max(decoder_output, dim=1)
# Record token and score
all_tokens = torch.cat((all_tokens, decoder_input), dim=0)
all_scores = torch.cat((all_scores, decoder_scores), dim=0)
# Prepare current token to be next decoder input (add a dimension)
decoder_input = torch.unsqueeze(decoder_input, 0)
# Return collections of word tokens and scores
return all_tokens, all_scores
评估函数
-
indexes_batch = [indexesFromSentence(voc, sentence)]得到句子的index下标,句子sentence是问答系统的一个句子,lengths的Tensor矩阵,input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)将batch_size放在了第二维,decoded_words = [voc.index2word[token.item()] for token in tokens],index2word是voc实例里面的一个属性。 -
input(">")作用是先输出一个>然后获取直到回车的字符串并返回,然后对输入的句子进行noramlizeString,加空格,去除非字母的符号,output_words[:] = [x for x in output_words if not (x == 'EOS' or x == 'PAD')]很有灵性的一段代码,去除结束符和填充符号,但是写[:]好像没用呀。print('Bot:', ' '.join(output_words))将列表中的元素连接成字符串。
"""
output_words[:]相当先把output_words的元素全部复制一遍然后存到以地址output_words[:]开始的地方。
严格的说,python没有赋值,只有名字到对象的绑定。所以L1=L是把L所指的对象绑定到名字L1上,而L2=L[:]则是把L通过切片运算取得的新列表对象绑定到L2上。前者两个名字指向同一个对象,后者两个名字指向不同对象。换句话说,L1和L是指的同一个东西,那么修改L1也就修改了L;L2则是不同的东西,修改L2不会改变L。注意这个引用的概念对于所有的东西都成立,例如容器内部存储的都是引用。
"""
i=[1,2,3,4,5]
l=i[:]
i[2]=9
print(i)
print(l)
---------------------
[1, 2, 9, 4, 5]
[1, 2, 3, 4, 5]
---------------------
i=[1,2,3,4,5]
i[:]=[6,7,8]
print(i)
--------------------
[6, 7, 8]
[6, 7, 8]
def evaluate(encoder, decoder, searcher, voc, sentence, max_length=MAX_LENGTH):
### Format input sentence as a batch
# words -> indexes
indexes_batch = [indexesFromSentence(voc, sentence)]
# Create lengths tensor
lengths = torch.tensor([len(indexes) for indexes in indexes_batch])
# Transpose dimensions of batch to match models' expectations
input_batch = torch.LongTensor(indexes_batch).transpose(0, 1)
# Use appropriate device
input_batch = input_batch.to(device)
lengths = lengths.to(device)
# Decode sentence with searcher
tokens, scores = searcher(input_batch, lengths, max_length)
# indexes -> words
decoded_words = [voc.index2word[token.item()] for token in tokens]
return decoded_words
def evaluateInput(encoder, decoder, searcher, voc):
input_sentence = ''
while(1):
try:
# Get input sentence
input_sentence = input('> ')
# Check if it is quit case
if input_sentence == 'q' or input_sentence == 'quit': break
# Normalize sentence
input_sentence = normalizeString(input_sentence)
# Evaluate sentence
output_words = evaluate(encoder, decoder, searcher, voc, input_sentence)
# Format and print response sentence
output_words[:] = [x for x in output_words if not (x == 'EOS' or x == 'PAD')]
print('Bot:', ' '.join(output_words))
except KeyError:
print("Error: Encountered unknown word.")
运行模型
-
__dict__,python中的类,都会从object里继承一个__dict__属性,这个属性中存放着类的属性和方法对应的键值对。一个类实例化之后,这个类的实例也具有这么一个__dict__属性。但是二者并不相同。
In [26]: class A:
...: some = 1
...: def __init__(self,num):
...: self.num = num
...:
In [27]: a = A(10)
In [28]: print(a.__dict__)
{'num': 10}
In [30]: a.age = 10
In [31]: print(a.__dict__)
{'num': 10, 'age': 10}
- 加载模型,1.首先创建模型,2.使用
model.load_state_dict(embedding_sd)加载模型参数。
embedding = nn.Embedding(voc.num_words, hidden_size)
if loadFilename:
embedding.load_state_dict(embedding_sd)
# Initialize encoder & decoder models
encoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)
decoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)
if loadFilename:
encoder.load_state_dict(encoder_sd)
decoder.load_state_dict(decoder_sd)
encoder = encoder.to(device)
decoder = decoder.to(device)
# Configure models
model_name = 'cb_model'
attn_model = 'dot'
#attn_model = 'general'
#attn_model = 'concat'
hidden_size = 500
encoder_n_layers = 2
decoder_n_layers = 2
dropout = 0.1
batch_size = 64
# Set checkpoint to load from; set to None if starting from scratch
loadFilename = None
checkpoint_iter = 4000
#loadFilename = os.path.join(save_dir, model_name, corpus_name,
# '{}-{}_{}'.format(encoder_n_layers, decoder_n_layers, hidden_size),
# '{}_checkpoint.tar'.format(checkpoint_iter))
# Load model if a loadFilename is provided
if loadFilename:
# If loading on same machine the model was trained on
checkpoint = torch.load(loadFilename)
# If loading a model trained on GPU to CPU
#checkpoint = torch.load(loadFilename, map_location=torch.device('cpu'))
encoder_sd = checkpoint['en']
decoder_sd = checkpoint['de']
encoder_optimizer_sd = checkpoint['en_opt']
decoder_optimizer_sd = checkpoint['de_opt']
embedding_sd = checkpoint['embedding']
voc.__dict__ = checkpoint['voc_dict']
print('Building encoder and decoder ...')
# Initialize word embeddings
embedding = nn.Embedding(voc.num_words, hidden_size)
if loadFilename:
embedding.load_state_dict(embedding_sd)
# Initialize encoder & decoder models
encoder = EncoderRNN(hidden_size, embedding, encoder_n_layers, dropout)
decoder = LuongAttnDecoderRNN(attn_model, embedding, hidden_size, voc.num_words, decoder_n_layers, dropout)
if loadFilename:
encoder.load_state_dict(encoder_sd)
decoder.load_state_dict(decoder_sd)
# Use appropriate device
encoder = encoder.to(device)
decoder = decoder.to(device)
print('Models built and ready to go!')
运行模型
# Configure training/optimization
clip = 50.0
teacher_forcing_ratio = 1.0
learning_rate = 0.0001
decoder_learning_ratio = 5.0
n_iteration = 4000
print_every = 1
save_every = 500
# Ensure dropout layers are in train mode
encoder.train()
decoder.train()
# Initialize optimizers
print('Building optimizers ...')
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)
if loadFilename:
encoder_optimizer.load_state_dict(encoder_optimizer_sd)
decoder_optimizer.load_state_dict(decoder_optimizer_sd)
# Run training iterations
print("Starting Training!")
trainIters(model_name, voc, pairs, encoder, decoder, encoder_optimizer, decoder_optimizer,
embedding, encoder_n_layers, decoder_n_layers, save_dir, n_iteration, batch_size,
print_every, save_every, clip, corpus_name, loadFilename)
运行模型,与模型进行交流
将最后一行的注释取掉就可以与machine交流了。
# Set dropout layers to eval mode
encoder.eval()
decoder.eval()
# Initialize search module
searcher = GreedySearchDecoder(encoder, decoder)
# Begin chatting (uncomment and run the following line to begin)
# evaluateInput(encoder, decoder, searcher, voc)