文章转至:http://blog.csdn.net/jasonblog/article/details/17842535
通常,在使用Core Data的iOS App上,不同版本上的数据模型变更引发的数据迁移都是由Core Data来负责完成的。
这种数据迁移模式称为Lightweight Migration(可能对于开发人员来说是lightweight),开发人员只要在添加Persistent Store时设置好对应选项,其它的就交付给Core Data来做了:
从命名上可以看出这两个选项分别代表:自动迁移Persistent Store,以及自动创建Mapping Model。
自动迁移Persistent Store很好理解,就是将数据从一个物理文件迁移到另一个物理文件,通常是因为物理文件结构发生了变化。
自动创建Mapping Model是为迁移Persistent Store服务的,所以当自动迁移Persistent Store选项NSMigratePersistentStoreAutomaticallyOption为@(YES)、且找不到Mapping Model时,coordinator会尝试创建一份。
其它初始化场景可以参考Initiating the Migration Process。
既然是尝试创建,便有成功和失败的不同结果。只有当数据模型的变更属于某些基本变化时,才能够成功地自动创建出一份Mapping Model,比如:新增一个字段;删除一个字段;必填字段转换成可选字段;可选字段转换成必填字段,同时提供了默认值等等。
因为可能创建Mapping Model失败,所以考虑容错性的话,可以事先判断下能否成功推断出一份Mapping Model:
利用如上类方法,如果无法创建一份Mapping Model,则会返回nil,并带有具体原因。
以上都建立在Core Data能够自动找到sourceModel和destinationModel的基础上,如果无法找到对应的两份Model,则需要开发人员手工创建NSMigrationManager来进行数据迁移(可以参考Use a Migration Manager if Models Cannot Be Found Automatically)。
版本迁移过程
那么,数据迁移的过程是如何进行的?
首先,发生数据迁移需要三个基本条件:可以打开既有persistent store的sourceModel,新的数据模型destinationModel,以及这两者之间的映射关系Mapping Model。
利用这三样,当调用如下代码时(addPersistentStore):

Core Data创建了两个stack(分别为source stack和destination stack,可以参考Core Data stack),然后遍历Mapping Model里每个entity的映射关系,做以下三件事情:
1. 基于source stack,Core Data先获取现有数据,然后在destination stack里创建当前entity的实例,只填充属性,不建立关系;
2. 重新创建entity之间的关系;
3. 验证数据的完整性和一致性,然后保存。
考虑到第二步是重新建立entity之间的关系,那么应该是在第一步就把所有entity的对象都创建好了,并且保留在内存中,为第二步服务(事实上也是如此)。
完成第二步后,所有数据还是维持在内存中(可能还有两份,因为有两个stack),在完成数据验证后才真正保存。
这样的话,会容易导致内存占用过多,因为Core Data在这个迁移过程中也没有一种机制清理响应的context。所以在数据量较多时,App可能会遇到在数据迁移过程因为内存紧张而被系统干掉。
针对这种情况,我们可以自定义迁移过程。
自定义数据迁移(解决内存问题)
自定义数据迁移的过程通畅分为三步:
第一步是判断是否需要进行数据迁移:
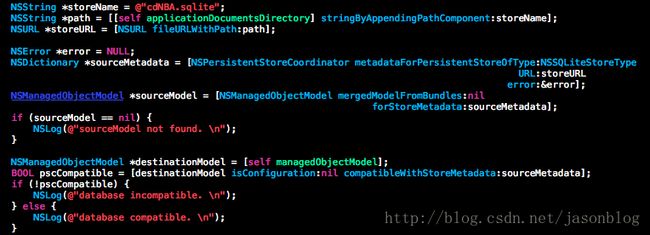
第二步是创建一个Migration Manager对象:

第三步是真正发生数据迁移:
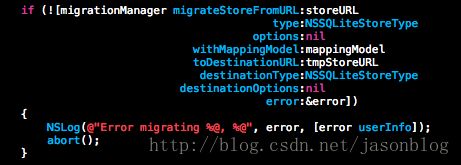
上面三幅图所展示的代码在内存使用量上跟lightweight migration也没什么区别,无法解决内存峰值过高的问题。
虽然Core Data专家Marcus S. Zarra比较倾向坚持使用lightweight migration,不过对于上述内存占用过多的问题,Apple官方推荐使用Multiple Passes来解决。
关于Multiple Passes,官方文档的说明很简明扼要,如有需要,可以参考Stackoverflow上的这么一篇帖子。
用我的话往简单里说就是对数据模型进行划分,把一份Mapping Model拆分成多份,然后分成多次迁移,从而降低内存峰值。这需要对数据库进行全盘的考虑(甚至可能需要变更部分设计),然后通过合理的划分把相关联的Entity放在一份Mapping Model里面(因为要建立关联)。
新的问题
采用上述方案来解决数据迁移过程中内存峰值的问题,我们仍然需要关注迁移所耗费的时间、内存,从而能够在数据上验证方案的有效性,并且在用户交互方面进行一些必要的更改(总不能让用户傻傻地在那边等数据迁移吧)。
虽然可以解决内存峰值的问题,但也引进了其它问题。
1. 需要对数据模型进行划分(以及变更),存在一定的工作量和风险;
2. 需要手工建立多份Mapping Model;
3. 需要手工编写Multiple Passes迁移代码;
4. 需要在每个版本变迁中都再次创建新的Mapping Model,且在跨版本迁移过程存在着其它问题;
5. 数据模型版本多起来,就面临着跨版本迁移的问题,是要为每个历史版本创建到最新模型的Mapping Model,还是只维护最近两个版本的Mapping Model(更早的版本通过相邻版本的Mapping Model依次迁移过来,比较耗时)?
6. 对数据模型重新划分后,无关的Entity简单变更也会引起整个store和model的不兼容,需要迁移,那么是否考虑分库?
7. 这么大的动作服务的用户数是很少的(只有少数用户会遇到,或者是很少),但却是比较资深的(因为消息记录多),疼。。。
8. 这无法解决单个Entity数据量过大的问题,针对这种场景,只能自己手工编码进行小批量的数据迁移;