Block Cache
RocksDB使用Block cache作为读cache。用户可以指定Block cache使用LRUCache,并可以指定cache的大小。
Block cache分为两个,一个是用来缓存未被压缩的block数据,另一个用来缓存压缩的block数据。
处理读请求时,先查找未压缩的block cache,再查找压缩的block cache。压缩的block cache可以替换操作系统的page cache。
用法如下
std::shared_ptr cache = NewLRUCache(capacity);
BlockBasedTableOptions table_options;
table_options.block_cache = cache;
Options options;
options.table_factory.reset(new BlockBasedTableFactory(table_options));
table_options.block_cache_compressed = another_cache;
LRUCache
默认RocksDB会创建一个容量为8M的LRUCache。
LRUCache内部对可以使用的容量进行了分片(Shard,下面习惯性地称之为分桶),每个桶都维护了自己的LRU list和用于查找的hash table。
用户可以指定几个参数
- capacity: cache的总容量
- num_shard_bits:2^num_shard_bits为指定的分桶数量。如果不指定,则会计算得到一个分桶数,最大分桶数为64个。
默认计算分桶数量的方法
指定的capacity / min_shard_size,其中min_shard_size为每个shard最小的大小,为512KB
- strict_capacity_limit:有一些场景,block cache的大小会大于指定的cache 容量,比如cache中的block都因为外部有读或者Iterator引用而无法被淘汰,这些无法淘汰的block总大小超过了总容量。这种情况下,如果strict_capacity_limit为false,后续的读操作仍然可以将数据插入到cache中。可能造成应用程序OOM。
该选项是限制每个分桶的大小,不是cache的总体使用大小。
- high_pri_pool_ratio:LRUCache提供了优先级的功能,该选项可以指定高优先级的block在每个桶中可以占的比例。
类图
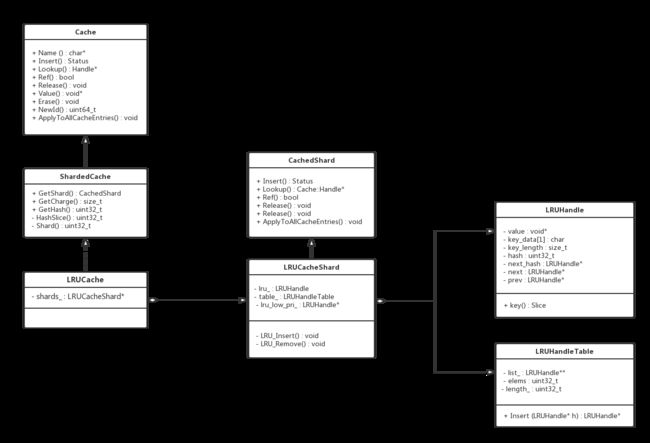
类图展示了各个类中的主要成员和一些操作。
- Cache
定义了Cache的接口,包括Insert, Lookup, Release等操作。 - ShardedCache
支持对Cache进行分桶,分桶数量为2^num_shard_bits,每个桶的容量相等。
分桶的依据是取key的hash值的高num_shard_bits位
(num_shard_bits_ > 0) ? (hash >> (32 - num_shard_bits_)) : 0;
- LRUCache
维护了一个shard数组,每个shard,即每个桶,都是一个LRUCacheShard用来cache分过来的key value。 - CacheShard
定义了一个桶的接口,包括Insert, Lookup, Release等操作,Cache的相关调用经过分桶处理后,都会调用指定桶的对应操作。 - LRUCacheShard
维护了一个LRU list和hash table,用来实现LRU策略,他们的成员类型都是LRUHandle。 - LRUHandleTable
hash table的实现,根据key再次做了分组处理,并且尽量保证每个桶中只有一个元素,元素类型为LRUHandle。提供了Lookup, Insert, Remove操作。 - LRUHandle
保存key和value的单元,并且包含前向和后续指针,可以组成双向循环链表作为LRU list。
保存了引用计数和是否在cache中的标志位。详细说明如下
LRUHandle can be in these states:
- Referenced externally AND in hash table.
In that case the entry is not in the LRU. (refs > 1 && in_cache == true) - Not referenced externally and in hash table. In that case the entry is
in the LRU and can be freed. (refs == 1 && in_cache == true) - Referenced externally and not in hash table. In that case the entry is
in not on LRU and not in table. (refs >= 1 && in_cache == false)
All newly created LRUHandles are in state 1. If you call LRUCacheShard::Release on entry in state 1, it will go into state 2.
To move from state 1 to state 3, either call LRUCacheShard::Erase or LRUCacheShard::Insert with the same key.
To move from state 2 to state 1, use LRUCacheShard::Lookup.
Before destruction, make sure that no handles are in state 1. This means that any successful LRUCacheShard::Lookup/LRUCacheShard::Insert have a matching RUCache::Release (to move into state 2) or LRUCacheShard::Erase (for state 3)
LRUCache结构如下

Insert的实现
从上到下逐层分析LRUCache的Insert实现。
RocksDB中,通过一个选项指定所使用的Cache大小,在open的时候传给DB。
auto cache = NewLRUCache(1 * 1024 * 1024 * 1024);
BlockBasedTableOptions bbt_opts;
bbt_opts.block_cache = cache;
调用Insert的一例如下
// 从option选项中获取bock cache的指针
Cache* block_cache = rep->table_options.block_cache.get();
// ...
if (block_cache != nullptr && block->value->cachable()) {
s = block_cache->Insert(
block_cache_key,
block->value,
block->value->usable_size(),
&DeleteCachedEntry,
&(block->cache_handle),
priority);
...
LRUCache的Insert实现在它的基类ShardedCache中,先对key做hash,hash的方法类似murmur hash,然后根据hash值确定存入到哪一个桶(Shard)中。可以认为一个桶就是一个独立的LRUCache,其类型是LRUCacheShard。
// util/sharded_cache.cc
Status ShardedCache::Insert(const Slice& key, void* value, size_t charge,
void (*deleter)(const Slice& key, void* value),
Handle** handle, Priority priority) {
uint32_t hash = HashSlice(key);
return GetShard(Shard(hash))
->Insert(key, hash, value, charge, deleter, handle, priority);
}
通过key确定分桶后,调用对应LRUCacheShard的Insert方法。
Status LRUCacheShard::Insert(const Slice& key, uint32_t hash, void* value,
size_t charge,
void (*deleter)(const Slice& key, void* value),
Cache::Handle** handle, Cache::Priority priority);
LRUCacheShard的三个主要的成员变量,Insert主要是对这三个成员变量的操作。
class LRUCacheShard : public CacheShard {
...
private:
LRUHandle lru_; // 链表的头结点
LRUHandle* lru_low_pri_; // 指向低优先级部分的头结点
LRUHandleTable table_; // 自己实现的一个hash table
};
一个LRUCache的底层实现,是依赖一个链表和一个HashTable,链表用来维护成员的淘汰的顺序和高低优先级,HashTable用来进行快速的查找。他们的成员类型是LRUHandle*。后面会详细了解他们的功能,下面分析一下Insert的实现,分为下面几步:
- 根据key value等参数构造LRUHandle
- 加shard级别锁,开始对LRUCacheShard做修改
- 根据LRU策略和空间使用情况进行成员淘汰
- 根据容量选择是否插入
- 如果计算发现,插入后的总的使用量仍然大于cache的容量,并且传入了需要严格限制flag,则不进行插入操作。这里有一个小点是,参数中handle是一个输出参数,插入成功后,赋值为指向cache中的LRUHandle成员的指针。如果用户传入的handle为null,说明用户不需要返回指向成员的handle指针,虽然插入失败,但是不报错;否则将handle赋值为null后报错。
- 如果释放了足够的空间,或者不需要严格限制空间使用,则开始进行插入操作。首先插入到hash table中,如果已经存在key对应的entry,则置换出来后,进行释放。
插入后,如果handle为null,说明插入后没人有持有对这个元素的引用,插入到LRU list中等待被淘汰。否则,暂时不将该元素插入到LRU list中,而是赋值给handle,等调用者释放了对该元素的引用,再插入到LRU list中
- 释放被淘汰的元素和插入失败的元素。
Status LRUCacheShard::Insert(const Slice& key, uint32_t hash, void* value,
size_t charge,
void (*deleter)(const Slice& key, void* value),
Cache::Handle** handle, Cache::Priority priority) {
LRUHandle* e = reinterpret_cast(
new char[sizeof(LRUHandle) - 1 + key.size()]);
... // 填充e
autovector last_reference_list; // 保存被淘汰的成员
{
MutexLock l(&mutex_);
// 对LRU list进行成员淘汰
EvictFromLRU(charge, &last_reference_list);
if (usage_ - lru_usage_ + charge > capacity_ &&
(strict_capacity_limit_ || handle == nullptr)) {
if (handle == nullptr) {
// Don't insert the entry but still return ok, as if the entry inserted
// into cache and get evicted immediately.
last_reference_list.push_back(e);
} else {
delete[] reinterpret_cast(e); // 没搞清楚这里为什么立刻删除,而不是像上面那样加到last_reference_list中稍后一起删除
*handle = nullptr;
s = Status::Incomplete("Insert failed due to LRU cache being full.");
}
} else {
LRUHandle* old = table_.Insert(e);
usage_ += e->charge;
if (old != nullptr) {
old->SetInCache(false);
if (Unref(old)) {
usage_ -= old->charge;
// old is on LRU because it's in cache and its reference count
// was just 1 (Unref returned 0)
LRU_Remove(old);
last_reference_list.push_back(old);
}
}
if (handle == nullptr) {
LRU_Insert(e);
} else {
// 当调用者调用Release方法后,会调用LRU_Insert方法,将该元素插入到LRU list中
*handle = reinterpret_cast(e);
}
s = Status::OK();
}
}
// 释放被淘汰的元素
for (auto entry : last_reference_list) {
entry->Free();
}
return s;
}
上面的流程中,有两次插入,分别是hash table的插入和链表的插入。
LRUHandleTable
- LRUHandleTable内部根据LRUHandle元素中的hash值分桶
- 每个桶是一个链表
- 插入时插入到链表的尾部。
- 如果元素数量大于桶的数量,则对桶的数量调整为之前的两倍,为的是让一个桶的链表长度尽量小于等于1.
class LRUHandleTable {
public:
...
LRUHandle* Insert(LRUHandle* h);
...
private:
...
uint32_t length_; // 桶的数量,默认数量为16
uint32_t elems_; // 元素总数
LRUHandle** list_; // 一维数组,数组的成员为每个链表的头指针
};
hash table的Insert实现:
- 根据key和hash值,找到对应的桶,在桶中沿着链表找到key和hash值对应的节点
- 如果key和hash值对应的节点已经存在,则用新的节点替换老的节点,将老节点返回
- 如果key和hash值对应的节点不存在,则插入到链表结尾,并且判断是否需要对hash table扩容
LRUHandle* LRUHandleTable::Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
// 如果key已经存在,则替换老的元素
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
// 如果key不存在,则判断元素总数和桶的数量是否需要扩容
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
Resize();
}
}
return old;
}
LRUHandle** LRUHandleTable::FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)]; // 根据hash值找到对应的桶
// 沿着链表比较key和hash值,直到链表尾部
while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
LRU list
LRU list按优先级分为两个区,高优先级区和低优先级区
- lru_为链表头,也是高优先级的表头
- lru_low_pri_为低优先级的表头
- 当high_pri_pool_ratio_为0时,表示不分优先级,则高优先级和低优先级的表头都是LRU list的表头
插入时,不论是高优先级插入还是低优先级插入,都插入到表头位置。
Insert实现如下
void LRUCacheShard::LRU_Insert(LRUHandle* e) {
assert(e->next == nullptr);
assert(e->prev == nullptr);
if (high_pri_pool_ratio_ > 0 && e->IsHighPri()) {
// Inset "e" to head of LRU list.
e->next = &lru_;
e->prev = lru_.prev;
e->prev->next = e;
e->next->prev = e;
e->SetInHighPriPool(true);
high_pri_pool_usage_ += e->charge;
MaintainPoolSize();
} else {
// Insert "e" to the head of low-pri pool. Note that when
// high_pri_pool_ratio is 0, head of low-pri pool is also head of LRU list.
e->next = lru_low_pri_->next;
e->prev = lru_low_pri_;
e->prev->next = e;
e->next->prev = e;
e->SetInHighPriPool(false);
lru_low_pri_ = e;
}
lru_usage_ += e->charge;
}
以上就是LRUCache的插入流程。
写的比较匆忙, 很多细节也没有提到, 有写的不对或者不明确的地方, 请指正, 谢谢!
参考资料:
https://github.com/facebook/rocksdb/wiki/Block-Cache