1. 前言
最近几天都耗在了词向量的训练以及可视化上,期间遇到了一些坑,也了解到一些容易忽略的知识点,在此一并记录下来,给自己也给大家一个警示。
2. keras中的TensorBoard
TensorBoard作为keras中回调函数(callback)的一种,能够从多方面监控训练的过程,及时反馈给使用者。
想象一下,通常模型的训练过程就像抛出一架纸飞机,“发射后不用管”,这往往会造成纸飞机的过早坠落,而使用回调函数来辅助训练的模型,像一架无人机,使用者能根据实际情况实时操控,也就是说使用者只要设定好想要监控训练的回调函数,在训练过程中就能完成各种任务。例如使用TensorBoard监控训练指标、验证指标、可视化词嵌入,可视化模型等。我们熟悉的keras进度条就是一个回调函数!
回调函数有多个,我们甚至能根据自己的实际需求自定义回调函数。这些放到以后再讲,今天我们只谈TensorBoard在keras中的用法。
2.1 使用TensorBoard
TensorBoard是一个基于浏览器的可视化工具,它内置在TensorFlow中。因此在使用它之前,应确保keras后端是TensorFlow。TensorBoard有如下功能:
1.监控指标
2.可视化模型架构
3.可视化词嵌入
4.可视化梯度与激活值
使用TensorBoard很简单,模型训练完成后,TensorBoard的一些日志信息也已经生成。我们需要把日志信息提取出来。在命令行中输入如下命令:
tensorboard --logdir=my_log_data
其中my_log_data是你之前模型训练时fit函数创建的文件夹,名字可以修改成你所需要的。上述命令其实也启动了TensorBoard的服务器,因此每次训练完成后我们都要输入上面的命令。
此时我们可以输入http://localhost:6006打开可视化工具了。有时候打不开是由于端口号被其他进程占用,此时输入如下命令:
tensorboard --logdir=my_log_data -port=8008
将默认的端口号修改为8008,或者直接查看进程列表,看是哪个进程占用了6006端口,将其杀死即可。
现在我们可以查看TensorBoard的各种功能了~
2.2 TensorBoard函数
上文说了训练完毕后怎么使用TensorBoard,接下来说明怎么在训练之前调用它。ps.不是本末倒置...
首先放上Tensorboard的函数原型:
keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=32, write_graph=True, write_grads=False, write_images=False, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None, embeddings_data=None, update_freq='epoch')
参数
- log_dir: 用来保存被 TensorBoard 分析的日志文件的文件名。
- histogram_freq: 对于模型中各个层计算激活值和模型权重直方图的频率(训练轮数中)。 如果设置成 0 ,直方图不会被计算。对于直方图可视化的验证数据(或分离数据)一定要明确的指出。
- write_graph: 是否在 TensorBoard 中可视化图像。 如果 write_graph 被设置为 True,日志文件会变得非常大。
- write_grads: 是否在 TensorBoard 中可视化梯度值直方图。 histogram_freq 必须要大于 0 。
- batch_size: 用以直方图计算的传入神经元网络输入批的大小。
- write_images: 是否在 TensorBoard 中将模型权重以图片可视化。
- embeddings_freq: 被选中的嵌入层会被保存的频率(在训练轮中)。
- embeddings_layer_names: 一个列表,会被监测层的名字。 如果是 None 或空列表,那么所有的嵌入层都会被监测。
- embeddings_metadata: 一个字典,对应层的名字到保存有这个嵌入层元数据文件的名字。 查看 详情 关于元数据的数据格式。 以防同样的元数据被用于所用的嵌入层,字符串可以被传入。
- embeddings_data: 要嵌入在 embeddings_layer_names 指定的层的数据。 Numpy 数组(如果模型有单个输入)或 Numpy 数组列表(如果模型有多个输入)。 Learn ore about embeddings。
- update_freq: 'batch' 或 'epoch' 或 整数。当使用 'batch' 时,在每个 batch 之后将损失和评估值写入到 TensorBoard 中。同样的情况应用到 'epoch' 中。如果使用整数,例如 10000,这个回调会在每 10000 个样本之后将损失和评估值写入到 TensorBoard 中。注意,频繁地写入到 TensorBoard 会减缓你的训练。
上述引自keras官方中文文档,回调函数 Callbacks - keras中文文档
我们进行词向量可视化用到的参数如下:
call_list=[keras.callbacks.TensorBoard(log_dir='my_log_data',embeddings_freq=1,
embeddings_data=x_train)]
其中embeddings_data是你的模型嵌入层的输入数据,必须要指定。
然后我们将这个call_list列表传入fit函数:
model_new.fit(x_train,shuffle=True,epochs=epochs,batch_size=batch_size,validation_data=(x_val,None),callbacks=call_list)
接下来就是2.1的操作了。
2.3词向量可视化遇到的坑
2.3.1 嵌入层维度
如果使用Keras构建的模型中第一层是输入层Input,第二层是嵌入层Eembedding,那么嵌入层的输入维度是(samples,sequence_maxlen),输出维度是(samples,sequence_maxlen,word_dim),而把嵌入层的权重提取出来就成了词向量。词向量的维度是(num_words,word_dim)。
大家可能会对上面的维度产生疑惑。“输入维度矩阵 * 词向量维度矩阵!=输出维度矩阵?”其实keras内部替我们处理好了,只要输入代表序列的整数列表,keras会自动把它转换成形如(samples,sequence_maxlen,num_words)的张量送入嵌入层。
举个例子,一个数据集中有1200条文本,每条文本的平均长度(字数)为100(sequence_maxlen),那么我们把它分为训练集1000(samples)条,验证集200条,设定词典数为10000(num_words)字。然后将其向量化成(1000,100)的输入张量送入嵌入层进行训练。文本形如[1,999,23,8476,...,3392]这样的格式。列表中的整数代表每个字在词典中的索引位置。我们设定生成的词向量维度为50(word_dim)维。
注意,重点来了,如果按上文的例子进行训练,最后用TensorBoard可视化词向量时我们会发现PCA中词向量的维度竟然变成了5000维(100*50),并且PCA陷入了卡顿,如下图所示。这是怎么回事?维度不应该是50么?
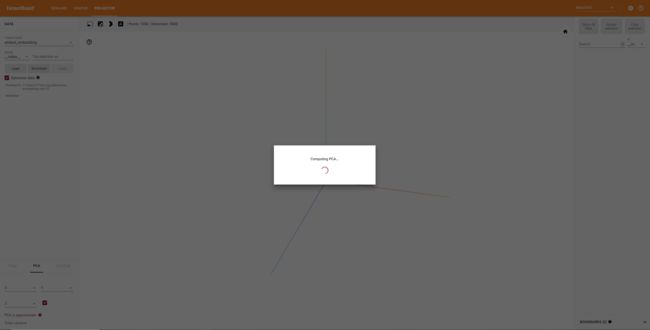
有问题找源码。从keras源码上我们能看到Keras中回调函数的源码,其中TensorBoard类中有这么一段代码:
for layer in self.model.layers:
if layer.name in embeddings_layer_names:
embedding_input = self.model.get_layer(layer.name).output
embedding_size = np.prod(embedding_input.shape[1:])
embedding_input = tf.reshape(embedding_input,
(step, int(embedding_size)))
shape = (self.embeddings_data[0].shape[0], int(embedding_size))
embedding = tf.Variable(tf.zeros(shape),
name=layer.name + '_embedding')
embeddings_vars[layer.name] = embedding
batch = tf.assign(embedding[batch_id:batch_id + step],
embedding_input)
self.assign_embeddings.append(batch)
self.saver = tf.train.Saver(list(embeddings_vars.values()))
注意看第四行embedding_size,里面提到了
embedding_size = np.prod(embedding_input.shape[1:])
这行代码说我们的嵌入层维度=embedding_input形状从第2个维度开始的累计乘积。
而embedding_input = self.model.get_layer(layer.name).output
embedding_input是嵌入层的输出,没错,就是输出。其格式为(1000,100,50)。
所以embedding_size=100*50=5000维。
至此我们才知道为什么PCA会显示5000维,原来这是写在源码里的,此时PCA显示的维度可称为是句向量的维度(相当于将词向量前后拼接了)。
找到了原因,那么我们来寻找解决办法。目前有2种方法来解决这一问题:
保存训练完毕后的嵌入层权重,单独使用PCA来进行可视化(抛开TensorBoard)
模型第一层的输入数据我们把它变形成(samples,num_words),即分词时我们将每条文本拆开成一个个词,此时samples=你想可视化的词的个数。num_words=词典中的所有词个数,然后再利用TensorBoard进行可视化。
以上就是Keras中TensorBoard可视化词向量的一些要点,觉得有帮助的还请点个喜欢哦~
参考文献
《python深度学习》
可视化词向量