1.安装elasticsearch (安装之前需要安装Java1.8版本以上。)
配置Java
检测是否有java环境,rpm -qa | grep jdk或者java
如果有 先卸载掉之前的java环境: rpm -e nodeps 进程名称 没有请看第三步
安装jdk ,导入安装包,一般在 /usr/local/ 下创建一个 java目录作为安装目录
解压文件到java目录下
配置环境变量: vi /etc/profile ,在文件最后添加以下信息:根据自己的安装包修改以及安装路径
#set java environment
JAVA_HOME=/usr/local/java/jdk1.8.0_131
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
保存profile 文件,并退出
执行source /etc/profile 使更改的配置立即生效
1.8. 验证是否安装成功,java -version
配置elasticsearch yum源
# vim /etc/yum.repos.d/elasticsearch.repo
输入:
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
# yum makecache
# yum install elasticsearch
启动命令:service elasticsearch start
若用 bin/elasticsearch启动,则需要将root用户改成elsearch ;用户组 : su elsearch
curl -XGET 'localhost:9200/?pretty',
出现
{
"name" : "Amalgam",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "q1JTidLuTNecwBbFNJCUFQ",
"version" : {
"number" : "2.4.1",
"build_hash" : "c67dc32e24162035d18d6fe1e952c4cbcbe79d16",
"build_timestamp" : "2016-09-27T18:57:55Z",
"build_snapshot" : false,
"lucene_version" : "5.5.2"
},
"tagline" : "You Know, for Search"
}
即配置成功;
需配置外网访问更改es配置
# vim /etc/elasticsearch/elasticsearch.yml
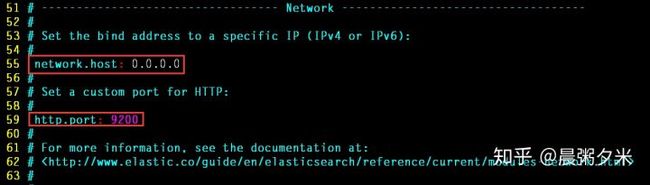
在阿里云开放端口9200/9400(外网)
2. 配置ik,head等插件;
2.1 head:
直接通过es plugins安装
./bin/plugin install mobz/elasticsearch-head
2.2 ik:
中文分词: es版本2.4.6 对应 ik插件版本: 1.10.6 ;
Github 参考link:medcl/elasticsearch-analysis-ik
支持更新热词等功能; 安装的坑: 解压前需要使用maven对下载的es-ik源码进行编译
参数设置:ik_max_word 和 ik_smart 什么区别?
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中 华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会 穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合Phrase 查询。 (个人认为适用于Titile)
3. 通过mongo-connector将数据导入es
参考文档:https://blog.csdn.net/werfhksdhf/article/details/83647882
①对应es2.4, 下载对应版本的mongo-connector以及pip install elastic2-doc-manager库。若服务器中有多个python;先升级到python2.7以上后,将各个版本中的mongo-connector删除后再重新安装。否则将出现bash : no command mongo-connector类似的命令;注意环境变量配置。
②需要开启mongodb复制集
若正常启动 mongo-connector
mongo-connector -m 47.94.14.59:27017 -t 47.94.14.59:9200 -d elastic2_doc_manager -n aituwen.posts
-m 以及 -t 后面分别是mongo端口和es端口; 导入数据100万条,需要40分钟左右;
4. ik分词器的使用及热词库使用
首先修改aituwen的分词器,问题:从mongo-connector导入的数据自动指定了索引mapping结构;
参考
ES 09 - Elasticsearch如何定制分词器 (自定义分词策略)www.cnblogs.com
先将索引close;
POST address/_close
执行:
PUT aituwen/_settings
{
"analysis": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
成功后将索引open
POST address/_open
分词效果查看:
GET aituwen/_analyze
{
"analyzer": "ik_max_word",
"text": "我爱北京天安门"
}
GET aituwen/_analyze
{
"analyzer": "standard",
"text": "我爱北京天安门"
}
ik 配置: 官方文档 https://github.com/medcl/elasticsearch-analysis-ik
IKAnalyzer.cfg.xml位于 {plugins}/elasticsearch-analysis-ik-*/config/IKAnalyzer.cfg.xml
热更新 IK 分词使用方法
目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现更新热分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
操作示例与效果展示:
在kibana/sense中查看分词效果:
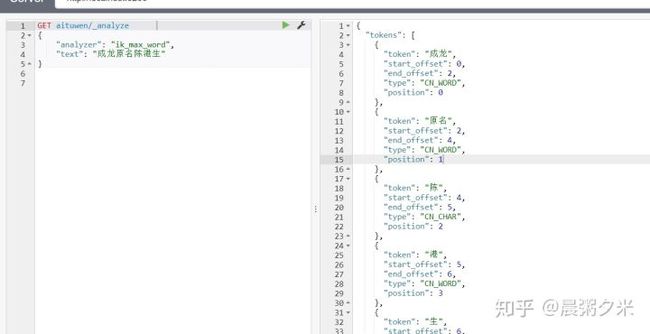
可以看到 ①陈港生三个词被分开,②ik分词起作用,原名两字成功分词。
进入plugins/ik/config/custom,在mydict.dic中添加 陈港生
service elasticsearch restart
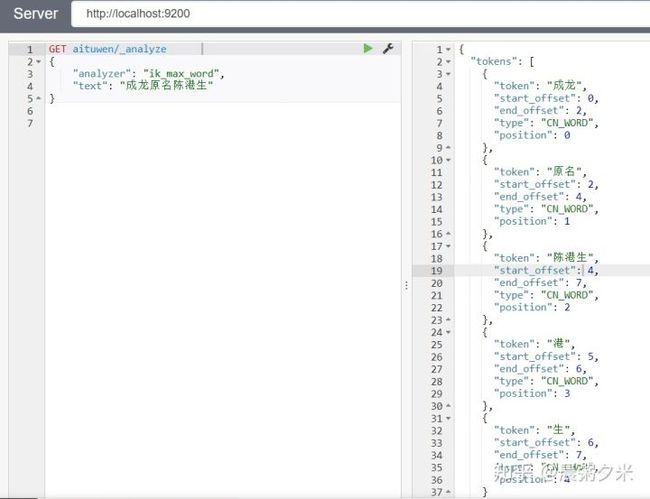
可以看到陈港生三个字作为一个独立分词。