模块 == 库 (标准库, 第三方库)
注意:文件名不与调用库名重复
sys1.py
sys.path #打印环境变量
sys.argv #打印相对路径
import os
cmd_res = os.system("dir") #执行命令,不保存结果
print("--->" , cmd_res) #输出0,表示执行成功
自己写的模块调用:
·在同一个目录下
·添加到环境变量
·添加到site-packages(在lib中)目录下
pyc里存放的是预编译后的字节码文件,会运行最近更新的文件
布尔值:
·真或假
·1 或 0
列表:
增:
·names.append("Ford") #添加
·names.reserver() #反转列表
·names.extend(names2) #新增列表,且原来列表存在
删:
·names.remove("Jack")
·del names[1] #特定位置删除
·del names2 #删除列表
·names.pop() #默认删除最后一个也可以指定位置
·names.clear() #清空列表
改:
·names.insert(1, "kater") #特定位置插入,直接写需要插入的位置
·names[2] = "Moon" #特定位置替换 --改
·names.sort() #排序:【特殊符号>> 数字>> 大写字母>> 小写字母】--参照ASCII
·name2 = copy.copy(names) #浅copy,复制第一层
name2 = name[:] #同上
name2 = list(name) #同上
·name2 = copy.deepcopy(names) #深copy,完全克隆
查:--顾头不顾尾, 0位置可以省略,范围取值用“ :”
A、根据位置取名字
·print(names)
·print(names[1:3]) #切片处理
·print(names[-1]) #反向切片
·print(names[-2:]) #倒数两个
·print(names[0: -1: 2]) #每隔两个打印
B、根据名字取位置
·print(names. index("Li")) #查询“Li”的位置
·print(names[names.index("oliver")]) #查询“oliver”是否存在
·print(names.count("oliver")) #打印所有 “oliver”个数
元祖 -- tuple
功能和列表相似,只是一旦创建,便不能再修改,又称--只读列表语法
enumerate:把列表中的下标取出来
例如: for index, item in enumerate(product_list):
print(index,item)
\033[31;1m______\033[0m: 输出文字变色
32绿色
41背景红条
42背景绿条
exit()--退出
练习:


定义两个列表,商品列表和购物车空列表,输入工资,判断是否为整数,如果不是则提示错误,是的话,就继续循环
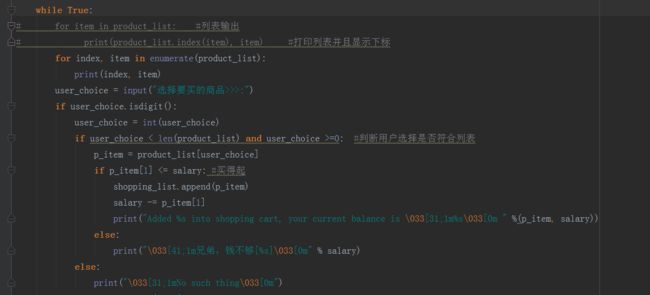
输出商品列表中的商品和下标,用户选择购买的商品,判断用户输入的是否为整数,错误则显示No such thing,符合要求则判断是否符合商品的的下标,判断用户工资是否能够支付,并根据判断结果输出

用户主动推出---quit,并打印已经购买的商品列表和工资,第一次判断不是整数则,显示wrong option
字符串的贼无聊操作:
name = "jams\tses {name} lal {age}"
print(name.capitalize()) #首字母大写
print(name.count("s")) #计数
print(name.center(50, "-")) #居中,补上--
print(name.endswith("s")) #判断是否已s结尾,true or false
print(name.expandtabs(tabsize=10)) #将\t转化为空格
print(name.find("a")) #切片
print(name.format(name='Liu', age='18')) #格式化输出,常用
print(name.format_map( {'name':'Liu','age':16} ) ) #格式化输出,字典
print(name.isalnum()) #判断是否是拉丁数字和英文字符
print(name.isalpha()) #判断是否是纯英文字符
print(name.isdigit()) #判断是否是整数
print(name.isidentifier()) #判断是否是一个合法的标识符
print(name.isupper()) #判断是否是全部大写
print(name.index('s')) #判断‘s'是否存在于,并打印存在个数
print(name.title()) #判断首字母是否大写
print('+'.join(['1','2'])) #输出 1+2
print(name.ljust(30,'*')) #右边添加
print(name.rjust(30,'$')) #左边添加
print(name.lower()) #把大写变小写
print(name.upper()) #把小写变大写
print('\nAllowed'.lstrip()) #去除左边的空格或回车
print('Allowed\n'.rstrip()) #去除右边的空格或回车
p = str.maketrans("adcdef",'123456')#对应位置替换
print("aecdf Li".translate(p))
print('Allowed C'.replace('l','L',1)) #替换
print('Allowed C'.split()) #把字符串按照空格(默认)分成列表,也可以按照()中的输入分割,去除()内的
print('1+2+3+4'.split('+'))
print('1+2\n+3+4'.splitlines()) #\n隔开
print('Allowed'.zfill(30))
字典:字典是一种key-value 的数据模型,通过字母,符号来查找对应的内容
key(尽量不写中文))+ 内容
增:
info["stu1101"] = "武藤兰" #改或添加
info.update(b) #有的就更新,没有就创建,b为某列表
c = dict.fromkeys([6,7,8],[1,{"name":"Allowed"},666]) #批量添加
删:
del info["stu1101"] #删除,python内置通用方法
info.pop("stu1101") #同上
改:
c[7][1]['name'] = "Jack" #全都修改
c.setdefault("taiwan",{"www.baidu.com":[1,2]}) #如果key存在则不修改,不存在就添加
查:
print(info.get('stu1105')) #具体查找
print('stu1103' in info) #查找字典中是否存在
for i in info:
print(i, info[i]) #循环输出
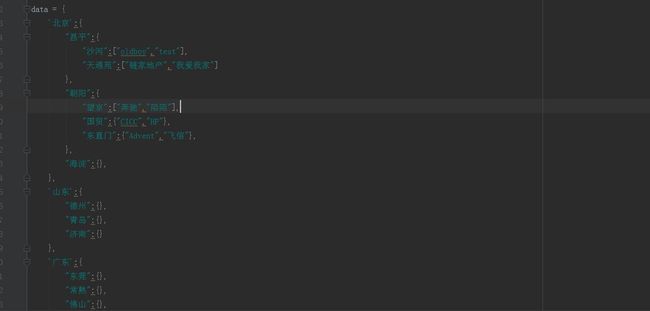
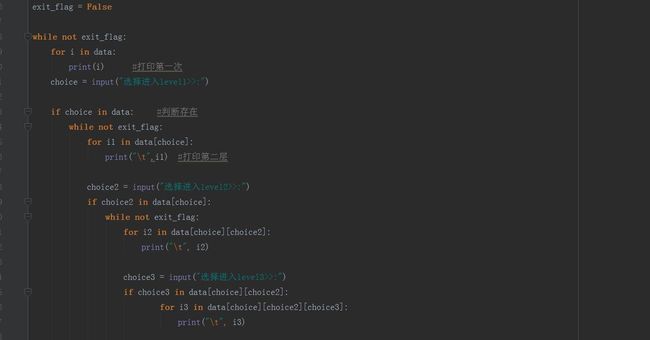
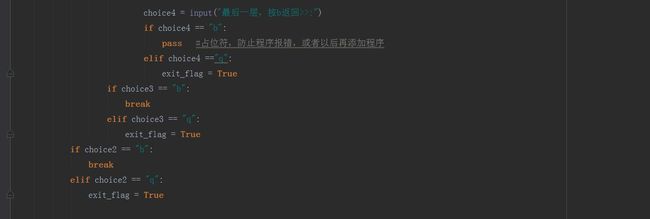
三级菜单: