* Always remember to check the quality/availability of the input array/number/anything.
1. Two sum
The complexity of my solution is O(n^2). It's very simple and a little stupid.
There are two others' solution:


which complexity is O(n)
以上这两种方法用的都是hash或dictionary。还有一种方法是夹逼法,先对数组进行排序,然后用两个pointer分别指向数组的第一个和最后一个数字,检查这两个数字相加是否等于target,若等于,则返回这两个数字。否则就比较这两个数字相加后和target的大小,若大于target,便把right pointer向左移一个数字(right --), 若比target小,则 left++。但是这种方法最终返回的是数字,不是index。若需要返回index,则要另外构造一个数字结构,存储最初的数字和index,再依次进行查找。
66. Plus one
Use a variable "carry" to denote whether to carry on this digit. It's very skillful, and need to be often reviewed.
88. Merged sorted array
num1 is long enough to contain both num1 and num2. So compare element in num1 and in num2 one by one, put the biggest in num1[m+n-1]. If the num1 is empty, just copy num2 into num1.
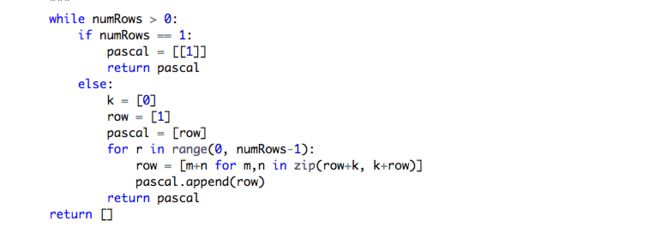
118. Pascal's Triangle
The main principle of Pascal Triangle is:
通过观察杨辉三角可知,下一行的每一个元素都依次由本行中每两个相邻元素之和得到,这个方法可以用一个技巧实现,即:将本行list拷贝出两个副本,将两个副本错1位,然后加在一起。由于错位后,前后各多了一个元素,所以要在错位后的两个list的前后各加一个[0]来补齐(其实,这个0是理所当然的,是杨辉三角的一部分)。
同一行中前后相邻两个元素相加(这是杨辉三角的构成规则),就相当于两个本行元素错位相加。而zip方法,就是从这两行中分别取出第i个位置的元素组成元组(这也是添“0”的原因)。sum()函数正好求出它们的和,进而求出了下一行。然后又yield函数把这一行“塞入”generator--也就是本例中的triangles()。
217. Contains Duplicate
Given an unsorted array, most times it's better to sort it first, then do what you want. In this question, if I didn't sort it first, I need to compare the 'temp' variable to every element in the array, which takes O(n^2). But after sorted the array, we only need to compare 'nums[i]' with 'nums[i-1]' which obviously takes O(n).
219. Contains Duplicates 2
模仿大牛的代码还是挺有用的。
1. set(): 去除重复对象
2. zip的用法:zip可被用来计算相邻两元素两两相减---m=[j-i for i, j in zip(p[:-1], p[1:])]

3. enumerate()

4. 切片
切片操作符中的第一个数(冒号之前)表示切片开始的位置,第二个数(冒号之后)表示切片到哪里结束,第三个数(冒号之后)表示切片间隔数。如果不指定第一个数,Python就从序列首开始。如果没有指定第二个数,则Python会停止在序列尾。注意,返回的序列从开始位置开始,刚好在结束位置之前结束。即开始位置是包含在序列切片中的,而结束位置被排斥在切片外。
这样,shoplist[1:3]返回从位置1开始,包括位置2,但是停止在位置3的一个序列切片,因此返回一个含有两个项目的切片。类似地,shoplist[:]返回整个序列的拷贝。shoplist[::3]返回位置3,位置6,位置9…的序列切片。
你可以用负数做切片。负数用在从序列尾开始计算的位置。例如,shoplist[:-1]会返回除了最后一个项目外包含所有项目的序列切片,shoplist[::-1]会返回倒序序列切片。
121. Best time to buy and sell stock 动态规划
this question can be seen as dynamic programming. Using one local max profit and one global max profit to find the best time to buy and sell stock. Compare the local max profit with 0, cause sometime the stock profit may be negative. then compare the local max profit with the global max profit, which aims to update the global max profit.
local = 0; global = 0;
local = max(local+ prices[i+1]-prices[i], 0)
global = max(local, global)
* do not forget to add the former local max profit
268. Missing Number
To find the element in list1 but not in list2:
list3 = list(set(list1) - set(list2))
list3 = [i for i in list1 if i not in list2]
list3 = list(set(list1).difference(set(list2)))
54. Spiral Matrix
When traverse left and up, we need to add the additional judgement condition, "if rowbegin <= rowend" and "if colbegin <= colend". Aims to avoid traverse back when there is only one row or one column in matrix.
55. Jump Game. 53 Maximum subarray动态规划


396. Rotate Function
变换公式,找出数学规律
238. Product of Array Except Self
Use a middle variable to compute the product.
First, initialise the list as: 1, n_0, n_0*n_1, n_0*n_1*n_2. Then start from the end of the list, times the middle variable P. P start from 1, to n_3, n_3*n_2, n_3*n_2*n_1

15. 3 Sum
在三个数中,固定一个数nums[i] ,将第二个数和第三个数分别从i+1和最后一个数开始。判断三个数相加是否为0,若为0,则将这三个数添加到结果中,然后向右移动left(需要保证left < right),若移动后的数字和移动前的数字一样,则继续移动。 若三个数相加大于0, 则向左移动right(需要保证left < right),若移动后的数字和移动前的数字一样,则继续移动。若三个数相加小于0,继续上边的操作。
记住每次更换固定的数字时,都要重新初始化left和right。并且要保证left < right。
时间复杂度为n^2
39. Combination Sum
运用Backtracking和DFS的思想,因为相加等于target的组合有多个,所以我们维护一个path list,每次向其中添加来自candidates中的一个元素,然后将target减去这个元素得到新的target,继续调用backtracking函数,此时传进去的参数是新的path和新的target。在每次backtracking执行过程中,要注意检查以下几点:
1. 如果target<0: 则返回。 因为backtracking 函数没有返回值,所以返回的是上一次调用这个函数之前的地方。即for循环那里,此时for循环向后移动,程序继续
2.如果target=0:则说明此时的path便是我们想要的结果之一,便将path append到result中,然后返回。
3.如果target>0:便开始for循环,调用backtracking函数,此时的调用应该注意更新参数(path, target)。 ** 在调用函数之前,通过增加判断 if target < c(break)来节省时间。并通过 if path and target 这道题跟第39题的区别就是,这道题不允许重复使用数字,比如candidates中如果有两个1,那结果集中的每个path,也最多只能有两个1。代码需要改变的地方就是for循环中的判断条件。上一题中,由于允许出现重复数字,因此可能会出现(2,2,3),(2,3,2),(3,2,2)这种情况,因此需要对每个path进行排序,来消除重复的path。这一题中,由于每个数字只允许使用一次,所以 1.每次调用backtracking函数,是从i+1开始的: self.backtracking(path + [self.cand[i]], i+1, target - self.cand[i]) 2. 不需要对path进行排序,但是要跳过candidates中的重复项,避免得到重复的path。 if i > index and self.cand[i] == self.cand[i-1]: (continue) **注意这里是 i>index 而不是 i>0,因为for循环的起始点是 index, index每次都会进行更新。 二叉树的中序遍历,可背 中序 inorder:左节点->根节点->右节点 前序 pre-order:根节点-左节点-右节点 后序 post-order: 左节点-右节点-根节点 注意:因为每次pop出来的是最后一个元素,所以push时应该按相反的顺序来push nodelist.append((node.right, False)) nodelist.append((node, True)) nodelist.append((node.left, False)) nodelist.append((node.right, False)) nodelist.append((node.left, False)) nodelist.append((node, True)) nodelist.append((node, True)) nodelist.append((node.right, False)) nodelist.append((node.left, False)) 维护三个pointer: pre, head, next。 pre永远是第一个,初始值应为none,因为第一个node反转后指向的为空。head.next指向pre,pre后移到head, head后移到next. next指向的永远是head.next。 先找到m之前的一个node,标记为mpre,然后m的位置就是mp = mpre.next. 使用一个计数器从0开始,花费 m-1>count 步骤找到mpre。 此时count已经有一定的值,再此count基础上,再花费n-1>count步骤进行reverse。reverse的三个变量分别是: mpre, mp, temp(next). temp为mp的下一个node, 让mp.next指向temp.next, 再将temp指向mp, 即temp.next = mpre.next, 最后将mpre指向temp, 即mpre.next = temp. given 1-2-3-4-5, k=2 return: 4-5-1-2-3 寻找尾节点的同时计算链表长度。 记链表长度为n,则实际移位次数为k=k%n。记len=n-k。 也就是说链表的后k个节点成为新链表的前半部分,链表的前len个节点为新链表的后半部分。 因此head往右第len的节点为新链表的尾,第len+1为新链表的头 两端相连即可,尾部下一个设为NULL即可。 注意: 当 k % len == 0 时,直接返回原list 针对linkedlist的插入排序, 先生成虚拟节点指向head。将head.next 设为空,以head作为最初的sorted list, 逐个加入后边list中的每个元素。因为插入排序是从后向前扫描的,所以永远维护sorted list中的最后一个元素作为pre, unsorted list中的第一个元素作为cur, 标记cur.next为next, 当当前cur被加入到sorted list中时,next 变成为新的cur。 每次比较pre和cur的值,如果pre的值小于等于cur的值,则直接将cur链接在pre之后即可。如果pre大于cur的值,则需要另一个变量prepre, 使prepre从dummy开始,判断prepre.next的值与cur值的大小关系,当prepre.next.val>cur.val时便停止。这时prepre所处的位置的下一个元素应指向cur。但在指向cur之前,应先标记prepre.next为prnext,因为插入cur之后,要将cur.next指向之前的prepre.next。 昨天想了半天,今天看了一下discuss, 原来只要把original list拆成两个list, 第一个list全是比x小的node, 第二个list全是大于等于x的node。再将第一个list指向第二个list,不要忘了将第二个list的最后一个node的next指向none。 1. merge and sort。 while fast and fast.next: slow = head, fast = head.next 循环停止时,slow正好停在上半段最后一个元素,fast停在下半段最后一个元素。 half2 = slow.next 作为下半段的开头。迭代对两个list进行sort,直到最后每一个node构成一个list,再对所有的list进行排序。 需要注意的就是,while停止时,要将slow.next先赋给half2, 然后将它指向空。fast是从head.next开始的,不是从head开始。 当fast从head开始时,需要另一个指针pre,指向前半段的最后一个元素。while中加上pre = slow。 while停止时,pre.next = none。 此时slow指向后半段第一个元素。 二分查找中mid=(l+r)/2 和 mid=l+(r-l)/2 是一样的,二分查找复杂度为log(n) 这题需要注意的问题不多,主要是更新l 和r时不能单纯的将 l=mid, r=mid, 而应该是l = mid+1, r=mid-1。 循环判断条件也应该是l<=r。 具体什么时候可以直接用mid,什么时候要mid+-1,我还没有完全搞清楚 这个要注意的也不多, 找不到元素时返回r+1就好了 用二分查找找出mid, 如果x介于mid*mid和(mid+1)*(mid+1)之间,那mid就是sqrt(x)。所以判断条件就是:mid*mid <= x and x < (mid+1)*(mid+1) 否则的话就相应的更新r或者l 这题的重点在于,可以把这个每行都有序,且行与行之间也都有序的matrix看为一个一维数组来处理,l=0, r=m*n-1. mid = (l+r)/2。知道了总的index,怎样确定它在哪一行哪一列呢? num = matrix[mid/n][mid % n]。 行:mid/n, 列:mid%n。 n 为列数。 与上一题不同的地方在于,这个矩阵不仅每行升序排列,每列也都升序排列。idea就在于: 这里更新的不是l和r, 而是row 和 col。判断条件也变为 while row < m and col >= 0。 不再是二分查找,时间复杂度为o(n), 因为每次都和最右上方的元素比较,一共有n个最右上方的元素,最多比较n次。 for example, if we want to calc (17/2) ret = 0; 17-2 ,ret+=1; left=15 15-4 ,ret+=2; left=11 11-8 ,ret+=4; left=3 3-2 ,ret+=1; left=1 ret=8; 程序如下: 正负号和数字越界这里处理的比较巧妙。 有5种不同解法,至少应该理解两种,包括binary search的 https://discuss.leetcode.com/topic/21837/5-different-choices-when-talk-with-interviewers 是33的follow up, 存在重复数字的情况,尚不明白 https://discuss.leetcode.com/topic/20593/python-easy-to-understand-solution-with-comments https://discuss.leetcode.com/topic/13759/python-3-different-ac-solutions 不理解 binary search的 https://discuss.leetcode.com/topic/22705/python-140ms-beats-100-and-works-for-n-sum-n-2 python for N-sum https://discuss.leetcode.com/topic/17110/my-straightforward-python-solution http://blog.csdn.net/wzy_1988/article/details/17057929 1. 中缀转换到reverse polish notation:(帮助理解解题思路) 第一步:按照运算符的优先级对所有的运算单位加括号~ 式子变成拉:((a+(b*c))-(d+e)) 第二步:转换中缀与后缀表达式 后缀:把运算符号移动到对应的括号后面 则变成拉:((a(bc)*)+(de)+)- 把括号去掉:abc*+de+-后缀式子出现 2. 需要注意的地方有: a. 将数字append到stack中时,应该把数字转换为int型 b. 注意计算顺序。第一个pop出来的元素在运算符右边,第二个pop出来的元素在运算符左边!!!! c. 除法需注意: python中1/-22= -1,但leetcode要求 1/-22=0,所以除法运算应写为: stack.append(int(float(num2)/float(num1))) 或者 #stack.append(int(num2*1.0/num1)) d. 判断运算符时注意使用elif 维护一个数组dp, dp[i]=true 意味着 s[:i+1]在worddict中, dp[0]应该被初始为true dp初始化:dp = [False] * (len(s)+1) 注意长度应为s的长度再加1 双层for循环,每次的判断条件为dp[i]==true and s[i:j+1] in worddict, then dp[j+1]== true 最后返回结果为dp的最后一个元素dp[-1] 利用每个元素出现两次,以及位操作异或的性质来解决这个问题。因为两个相同的元素异或结果是0,利用这个特点我们可以对所有数组元素进行异或,如果出现两次的元素就会自行抵消,而最终剩下的元素则是出现一次的元素。这个方法只需要一次扫描,即O(n)的时间复杂度,而空间上也不需要任何额外变量 I like to think about the number in 32 bits and just count how many 1s are there in each bit, and "sum %= 3" will clear it once it reaches 3. After running for all the numbers for each bit, if we have a 1, then that 1 belongs to the single number, we can simply move it back to its spot by doing "ans |= sum << i" ; This has complexity of O(32n), which is essentially O(n) and very easy to think and implement. Plus, you get a general solution for any times of occurrence. Say all the numbers have 5 times, just do "sum %= 5". ** 当把剩余的一个1 还原为十进制整数时,在python中需要注意负号的情况。 if i == 31: res -= 1<<31 For a 32 bit number, if i == 31, we are on the bit telling us whether the number is negative or not. if we are on the bit that tells us the sign, and the number that appears not three times has a 1 here", then take the largest 32 bit integer and subtract it from our res. If the number that we are looking for is negative, this will give the correct answer. 思路没有问题,就是一直叠加balance += gas[i] - cost[i]。 需要注意的是,当balance小于0时,要对balance 和 start 进行更新:balance = 0; start = i + 1。意思就是从下一个station继续出发。这是题目没有说清楚的地方,即油不够时,可以挪到下一个station重新开始。。 BFS用queue, DFS用stack。 用queue时是popleft(),从左边取第一个。用stack是pop(),取最后一个。 **注意python中的字符串可以直接以数组的形式访问,无需再改写成数组。 ** s[l].isalnum() 检测字符串/字符 是否由字母或数字组成。not s[l].isalnum() 意思就是不是字母或数字 ** 当字符串为空时,也算回文序列 1. 注意边缘情况:当树为空时,返回 0!! 跟257题思路相同,但边缘情况返回值不同 给定一个三角形,输出最短路径和。每一个元素只能向下一层与它相邻的两个元素移动。Each step you may move to adjacent numbers on the row below. 这道题比较适合从下往上遍历,可以不用处理头尾特殊情况。 先初始化一个数组用来存放当前行和下一行相邻元素相加的最小和,注意⚠️ 数组大小应该是triangle最后一行大小再加1. 加1是因为要考虑最后一行的最后一个数组,参考动态规划的递归式来理解: rowmin[i] = row[i] + min(rowmin[i], rowmin[i+1]) 这个递归式的含义是,对每一行的每一个元素,保存这个元素与下一行相邻两个元素中最小的那个的和。rowmin要初始化为0. 双层循环结束后,rowmin的第一个元素就是minimum path,因为第一层只有一个元素。 时间复杂度为:把每个元素遍历一次,需要 n^2 空间复杂度为:O(n) 又是树的题目。理解题意时有很重要的一点就是,因为已经初始化了所有的node的next指针为null,所以每一行最后边那个node是不用管的,它的next已经指向了null。 使用一个pre指针,让它总是指向root while循环的判断条件为while root.left,因为我们在当前行就可以执行完下一行的任务,所以无需将root循环到最后一行。 if 循环的判断语句为if root.next,意思是检查当前root的next是指向空,还是已经指向了某个node,如果它不指向空,我们就root.right.next = root.next.left, 并把root.next作为新的root 如果它指向空,root = pre.left ; pre = root; 我们就把pre.left作为新的root, 即向右移动了一个node。40. Combination Sum II
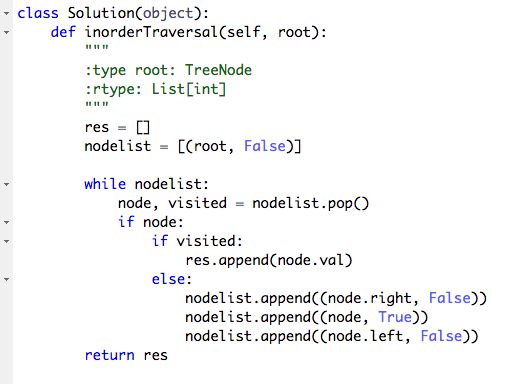
94. Binary Tree Inorder Traversal
inorder:
pre-order:
post-order:
206. Reverse Linked List
92. Reverse Linked List II
61. Rotate List
(a+b)>>1 == (a+b)/2
147. Insertion Sort List
86. Partition List
148. Sort List
binary search
34. Search for a Range
35. Search Insert Position
69. Sqrt(x)
74. Search a 2D Matrix
240. Search a 2D Matrix II

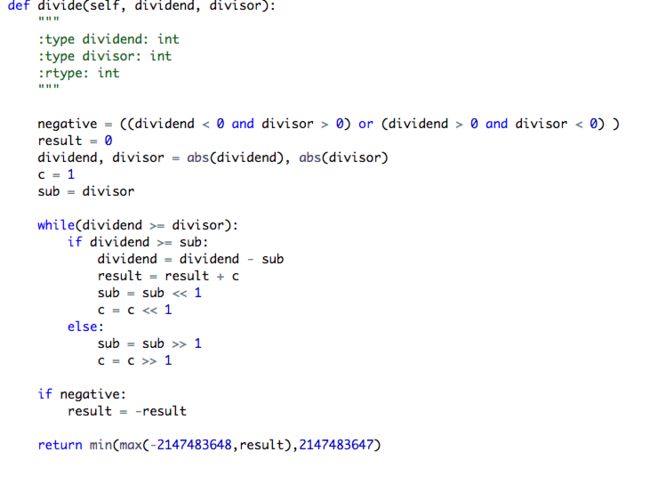
29. Divide Two Integers
50. Pow(x, n)
81. Search in Rotated Sorted Array II
209. Minimum Size Subarray Sum
167. Two Sum II - Input array is sorted
15. 3Sum
16. 3Sum Closest
18. 4Sum
13. Roman to Integer
43. Multiply Strings
150. Evaluate Reverse Polish Notation
139. Word Break ----- 动态规划
136.Single Number
137. Single Number II
134. Gas Station
133. Clone Graph------图问题
125. Valid Palindrome
129. Sum Root to Leaf Numbers
120. Triangle---动态规划
116. Populating Next Right Pointers in Each Node