redis 基本数据结构.
redis的基本数据结构主要有: SDS动态字符串,链表,字典,哈希表,跳跃表,整数集合,压缩列表.
SDS 动态字符串
typedef char *sds;
struct sdshdr {
//记录已使用的长度
int len;
//记录buf中未使用字符串
int free;
//字节数据,保存字符串
char buf[];
};
分配内存时,会多分配一个字节来存放'\0'结束标记.

注意: 在sdshdr结构体中,buf未分配内存时,buf是不占空间的
int main(){
printf("int --- %ld\n",sizeof(int));
printf("struct sdshdr --- %ld\n", sizeof(struct sdshdr));
return 0;
}
输出:
int --- 4
struct sdshdr --- 8
//分配空间
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
if (init) {
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
if (sh == NULL) return NULL;
sh->len = initlen;
sh->free = 0;
if (initlen && init)
memcpy(sh->buf, init, initlen);
sh->buf[initlen] = '\0';
return (char*)sh->buf;
}
//获取字符串长度
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
//获取未使用空间
static inline size_t sdsavail(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->free;
}
优点:
- 常数复杂度获取字符串的长度
- 杜绝缓冲区溢出
- 减少修改字符串时重新分配内存的次数
- 空间预分配
- 惰性回收
- 二进制安全
-
兼容部分C字符串
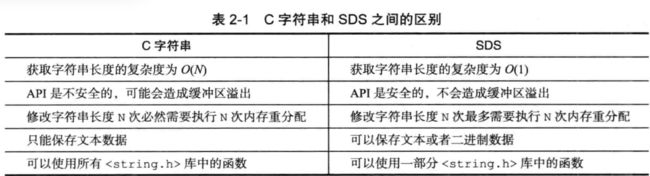
链表
/*
* 双端链表节点
*/
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
/*
* 双端链表迭代器
*/
typedef struct listIter {
// 当前迭代到的节点
listNode *next;
// 迭代的方向
int direction;
} listIter;
/*
* 双端链表结构
*/
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;
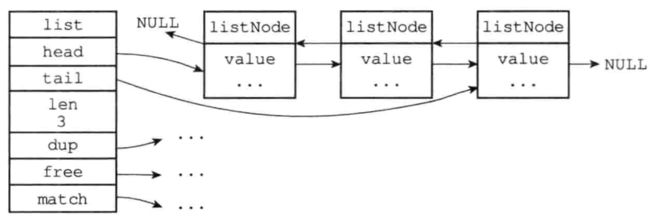
字典
Key-Value
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
哈希表
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
字典
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
字典的普通状态:
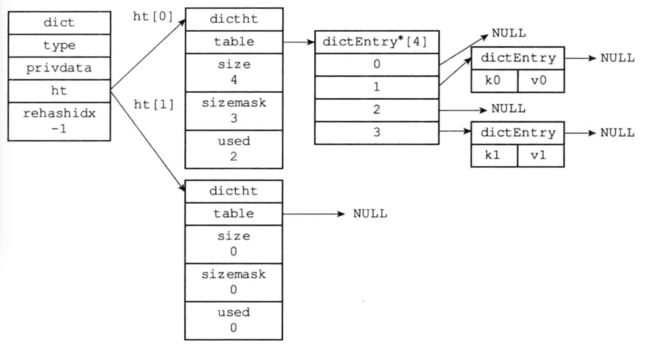
- 索引值计算
h = dictHashKey(ht, key) & ht->sizemask; - 解决键冲突
当有两个或以上数量的键被分配到哈希表上的同一索引的时候,我们称这些键发生了冲突,redis通过链地址法来解决冲突 - rehash
当哈希表保存的键值对数量太多或者太少时,要进行rehash
渐进式rehash: https://www.jianshu.com/p/9c84856cd5c0
跳跃表
跳跃表节点
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
跳跃表
/*
* 跳跃表
*/
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;

//随机获取层数
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level- 跳跃表是有序集合的底层实现
- 跳跃表根据分值的大小进行排序,当分值大小相同时,按照成员对象的大小排序
详细跳跃表讲解:
(http://blog.csdn.net/gqtcgq/article/details/50613896)
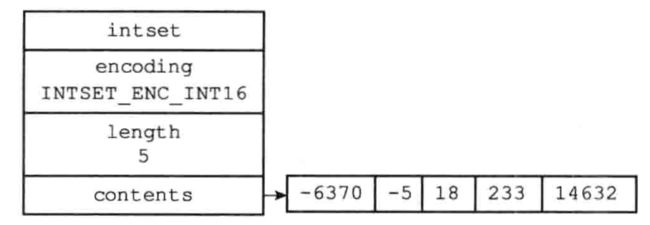
整数集合
整数集合是集合键的底层实现之一,当一个集合只包含整数值,并且这个集合元素不多时,redis会使用整数集合作为集合键的底层实现.
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
encoding: 表示整数集合中,存放的是那种长度的整数:16位,32位,64位.
- 升级
当添加一个整数到整数集合中时,如果新元素的长度比集合中的编码方式都要长时,要发生升级动作 , 整数集合只支持升级操作,不支持降级操作.
/* Insert an integer in the intset
*
* 尝试将元素 value 添加到整数集合中。
*
* *success 的值指示添加是否成功:
* - 如果添加成功,那么将 *success 的值设为 1 。
* - 因为元素已存在而造成添加失败时,将 *success 的值设为 0 。
*
* T = O(N)
*/
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
// 计算编码 value 所需的长度
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
// 默认设置插入为成功
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
// 如果 value 的编码比整数集合现在的编码要大
// 那么表示 value 必然可以添加到整数集合中
// 并且整数集合需要对自身进行升级,才能满足 value 所需的编码
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
// T = O(N)
return intsetUpgradeAndAdd(is,value);
} else {
// 运行到这里,表示整数集合现有的编码方式适用于 value
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
// 在整数集合中查找 value ,看他是否存在:
// - 如果存在,那么将 *success 设置为 0 ,并返回未经改动的整数集合
// - 如果不存在,那么可以插入 value 的位置将被保存到 pos 指针中
// 等待后续程序使用
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
// 运行到这里,表示 value 不存在于集合中
// 程序需要将 value 添加到整数集合中
// 为 value 在集合中分配空间
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 如果新元素不是被添加到底层数组的末尾
// 那么需要对现有元素的数据进行移动,空出 pos 上的位置,用于设置新值
// 举个例子
// 如果数组为:
// | x | y | z | ? |
// |<----->|
// 而新元素 n 的 pos 为 1 ,那么数组将移动 y 和 z 两个元素
// | x | y | y | z |
// |<----->|
// 这样就可以将新元素设置到 pos 上了:
// | x | n | y | z |
// T = O(N)
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
// 将新值设置到底层数组的指定位置中
_intsetSet(is,pos,value);
// 增一集合元素数量的计数器
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
// 返回添加新元素后的整数集合
return is;
}
升级操作:
/* Upgrades the intset to a larger encoding and inserts the given integer.
*
* 根据值 value 所使用的编码方式,对整数集合的编码进行升级,
* 并将值 value 添加到升级后的整数集合中。
*
* 返回值:添加新元素之后的整数集合
*
* T = O(N)
*/
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
// 当前的编码方式
uint8_t curenc = intrev32ifbe(is->encoding);
// 新值所需的编码方式
uint8_t newenc = _intsetValueEncoding(value);
// 当前集合的元素数量
int length = intrev32ifbe(is->length);
// 根据 value 的值,决定是将它添加到底层数组的最前端还是最后端
// 注意,因为 value 的编码比集合原有的其他元素的编码都要大
// 所以 value 要么大于集合中的所有元素,要么小于集合中的所有元素
// 因此,value 只能添加到底层数组的最前端或最后端
int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */
// 更新集合的编码方式
is->encoding = intrev32ifbe(newenc);
// 根据新编码对集合(的底层数组)进行空间调整
// T = O(N)
is = intsetResize(is,intrev32ifbe(is->length)+1);
/* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
// 根据集合原来的编码方式,从底层数组中取出集合元素
// 然后再将元素以新编码的方式添加到集合中
// 当完成了这个步骤之后,集合中所有原有的元素就完成了从旧编码到新编码的转换
// 因为新分配的空间都放在数组的后端,所以程序先从后端向前端移动元素
// 举个例子,假设原来有 curenc 编码的三个元素,它们在数组中排列如下:
// | x | y | z |
// 当程序对数组进行重分配之后,数组就被扩容了(符号 ? 表示未使用的内存):
// | x | y | z | ? | ? | ? |
// 这时程序从数组后端开始,重新插入元素:
// | x | y | z | ? | z | ? |
// | x | y | y | z | ? |
// | x | y | z | ? |
// 最后,程序可以将新元素添加到最后 ? 号标示的位置中:
// | x | y | z | new |
// 上面演示的是新元素比原来的所有元素都大的情况,也即是 prepend == 0
// 当新元素比原来的所有元素都小时(prepend == 1),调整的过程如下:
// | x | y | z | ? | ? | ? |
// | x | y | z | ? | ? | z |
// | x | y | z | ? | y | z |
// | x | y | x | y | z |
// 当添加新值时,原本的 | x | y | 的数据将被新值代替
// | new | x | y | z |
// T = O(N)
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* Set the value at the beginning or the end. */
// 设置新值,根据 prepend 的值来决定是添加到数组头还是数组尾
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
// 更新整数集合的元素数量
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
压缩列表
压缩列表是列表键和哈希键的底层实现之一,当一个列表键只包含少量列表项,并且每个列表项要么是小数值,要么是长度比较短的字符串,那么redis会用压缩列表作为列表键的底层实现.
压缩列表整体结构:

空 ziplist 示例图:
area |<---- ziplist header ---->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 1 byte
+---------+--------+-------+-----------+
component | zlbytes | zltail | zllen | zlend |
| | | | |
value | 1011 | 1010 | 0 | 1111 1111 |
+---------+--------+-------+-----------+
^
|
ZIPLIST_ENTRY_HEAD
&
address ZIPLIST_ENTRY_TAIL
&
ZIPLIST_ENTRY_END
非空 ziplist 示例图
area |<---- ziplist header ---->|<----------- entries ------------->|<-end->|
size 4 bytes 4 bytes 2 bytes ? ? ? ? 1 byte
+---------+--------+-------+--------+--------+--------+--------+-------+
component | zlbytes | zltail | zllen | entry1 | entry2 | ... | entryN | zlend |
+---------+--------+-------+--------+--------+--------+--------+-------+
^ ^ ^
address | | |
ZIPLIST_ENTRY_HEAD | ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_TAIL
entry结构:
/*
* 保存 ziplist 节点信息的结构
*/
typedef struct zlentry {
// prevrawlen :前置节点的长度
// prevrawlensize :编码 prevrawlen 所需的字节大小
unsigned int prevrawlensize, prevrawlen;
// len :当前节点值的长度
// lensize :编码 len 所需的字节大小
unsigned int lensize, len;
// 当前节点 header 的大小
// 等于 prevrawlensize + lensize
unsigned int headersize;
// 当前节点值所使用的编码类型
unsigned char encoding;
// 指向当前节点的指针
unsigned char *p;
} zlentry;

previous_entry_length
以字节为单位,记录了压缩列表前一个节点的长度.,该属性的长度可以是1字节,或者5字节. 如果前节点的长度小于254字节,则previous_entry_length的长度为1字节,如果前一节点的长度大于254字节,则previous_entry_length的长度为5字节.其属性的第一字节被设置为0xFE,而后4个字节保存前一节点的长度.-
encoding
记录节点的content属性保存数据的类型及长度
字节数组编码

整数编码

-
content
保存节点的值
字节数组:

整数值:

连锁更新:
有一种情况,在一个压缩列表中,有多个连续的,长度在250字节---253字节的节点,他们的previous_entry_length长度都是1字节,当我们在头部插入一个大于254字节长度的节点时,第二个节点要用5个字节来保存前一个节点的长度,但是现在只有1个字节,要进行扩容到5字节,而第三个节点要保存第二个节点的长度,由于第二个节点的previous_entry_length属性由1字节变为了5字节,第二个节点的整体长度也超过了254,第三个节点也需要扩容.这样一直更新下去,就会发生连锁更新.
连锁更新最坏的复杂度为O(N²);
添加节点到要列表或者从压缩列表删除节点,都会发生连锁更新操作,但是这个几率并不高.
参考----