点击这里进入人工智能DBD嘚吧嘚目录,观看全部文章
这可能是爬虫技术无法破解的加密格式。
案例分析
以58房产网站为例,我们爬取的房价以及其他很多数字都是乱码,閏龤龤龤元/月,龒室龤厅龒卫龥龤㎡。
右键检查元素会发觉,看上去正常的数字,在html代码中却是乱码。
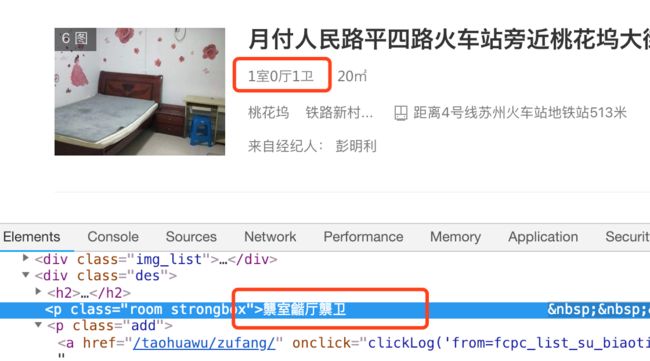
右侧可以注意到这样的元素使用了奇怪的font-family:fangchan-secret(房产-加密)字体样式,如果我们关闭这个strongbox样式,停用这个字体,页面上就会如实的显示乱码了。
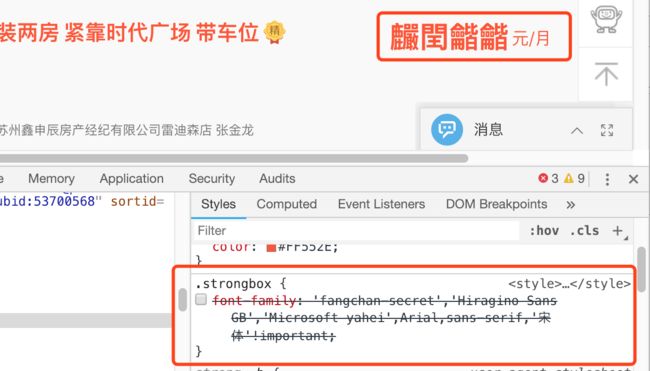
font-family这是一种自定义字体,它可以把乱码显示成正常的数字。
这是一种有效的反爬虫方式,但我还是要鄙视这种处理方式,首先这种乱码对搜索引擎非常不友好,其次用户在页面上复制粘贴得到的也是乱码,用户体验不友好,另外在真的要显示乱码所用字符的极端情况下将无法实现,所以这种手段仅适合加密少量字符。
问题分析
右键查看页面源代码,搜索fangchan-secret可以看到这个字体是JavaScript临时生成的。
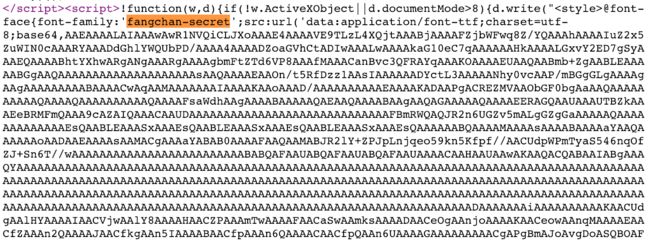
主要的字体信息是一长段大小写字母,我们把它完整复制下来。
为Python安装fonttools字体工具模块,conda install -c mwcraig fonttools,然后使用下面的代码将这段字母存储为ttf字体文件,中间的key部分需要你手工替换。
from fontTools.ttLib import TTFont
import base64
import io
key='''
AAEAAAALAIAAAwAwR1N.........AAA
'''
data = base64.b64decode(key) #base64解码
fonts = TTFont(io.BytesIO(data)) #生成二进制字节
fonts.save('fangchan-secret.ttf')
然后打开百度字体编辑网站,用打开按钮选择刚才生成的fangchan-secret.ttf,就可以看到真实的字体内容。
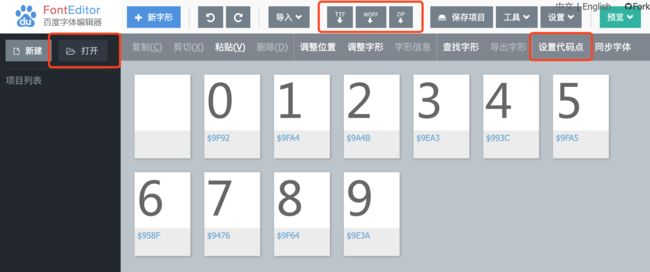
我们看到每个字形都有一个蓝色的编码,如$9A4B这样的字符,这是字符的16进制编码,用chr()命令查看它的真正样子。

这就是说,fangchan-secret字体把罕见的字符显示为0~9数字了。
解决方案
对字体数据进一步处理。
cmap=fonts.getBestCmap() #十进制ascii码到字形名的对应
for char in cmap:
print(char,hex(char),chr(char),cmap[char])
这个代码输出类似下面这个内容:
其中各个内容的关系如下图(上面的输出并没有包含字形图):

我们可以从字体文件中找到字符、编码和字形名,可以用工具查看到字形图,但如何把0x9476对应到6这个数字就只能靠人眼识别了,这也是加密的意义所在了。——我们无法用代码直接实现字符到字形所表示数字的对应关系。
这是死穴。
但很多时候没有那么糟糕,毕竟只是10个数字被加密,我们只要凭人眼建立10个字符乱码到真实数字的对应关系就可以解决问题,例如,假设我们搞定这个字典就不怕了:
numdict={
'鑶':0,
'閏':1,
'餼':2,
'驋':3,
'鸺':4,
'麣':5,
'齤':6,
'龒':7,
'龤':8,
'龥':9
}
但对于58房产网,这样还不够,因为他们的网站会每隔几秒钟就变化fangchan-secret的key,就是那一长串AAEAAAALAIAAAwAwR1N.........AAA。
反复对比之后发觉,它只是随机变化字符龥...和字形名glyph00007...之间的对应关系,而字形名和字形之间的关系并不变,比如说glyph00007几秒前对应龒几秒后又对应齤,但它总是对应字形6这个不变。
也就是说下面这个对应是固定的:
glyphdict = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
而实际上我们可以从fongchan-secret中读取到字符和字形名之间的对应关系,类似:
chrdict={
'鑶':'glyph00006',
'閏':'glyph00004',
'餼':'glyph00001',
'驋':'glyph00002',
'鸺':'glyph00003',
'麣':'glyph00009',
'齤':'glyph00010',
'龒':'glyph00008',
'龤':'glyph00007',
'龥':'glyph00005'
}
综上我们就可以间接实现乱码到数字的转换了。
最终代码
首先注意这个multReplace多个替换函数的作用:
#使用字典批量替换
import re
def multReplace(text, rpdict):
rx = re.compile('|'.join(map(re.escape, rpdict)))
return rx.sub(lambda match:rpdict[match.group(0)], text)
它可以批量执行replace的功能。rx是一个竖线分割的或者表达式,比如'a|b|c|d,这个表达式可以匹配出符合abcd任何一个字母匹配的列表。
rx.sub()方法传入了一个lambda函数,表示可以对rx匹配列表中的每个匹配都执行一个替换,效果如下:

下面是解密字体函数:
#解密58房产的字体加密
from fontTools.ttLib import TTFont
import base64
import re
import io
def decode58Fangchan(html,key):
glyphdict = {
'glyph00001': '0',
'glyph00002': '1',
'glyph00003': '2',
'glyph00004': '3',
'glyph00005': '4',
'glyph00006': '5',
'glyph00007': '6',
'glyph00008': '7',
'glyph00009': '8',
'glyph00010': '9'
}
data = base64.b64decode(key) #base64解码
fonts = TTFont(io.BytesIO(data)) #生成二进制字节
cmap = fonts.getBestCmap() #十进制ascii码到字形名的对应{38006:'glyph00002',...}
chrMapNum = {} #将变为{‘龥’:'1',...}
for asc in cmap:
chrMapNum[chr(asc)] = glyphdict[cmap[asc]]
return multReplace(html,chrMapNum)
读取本地爬取的文件进行解密:
from bs4 import BeautifulSoup
import html
with open('./pages/2.html', 'r') as f:
text = html.unescape(f.read()) #将閏室变为閏室
key = re.findall(r"base64,(.*)'\).format", text)[0] #用正则表达式提取AAE..AAA
dehtml = decode58Fangchan(text, key)
soup = BeautifulSoup(dehtml)
moneyTags = soup.find_all('div', 'money')
print(','.join([m.b.text.strip() for m in moneyTags]))
输出结果如下所示:

如果不进行字体解密的乱码结果如下:

动态字体
这样的字体加密文件如何实现的?
这里是一些思路和资源:
- 把多个svg文件合成为svg字体。Nodejs可以使用svgtofont模块,依照官方案例,把从网站下载(如iconfont网站)的多个svg图形文件放到icon文件夹下,然后执行node代码就会得到一个可以读懂的.svg文件,类似以下文件,可以清楚地看到它包含了三个字形glyph以及每个字形对应的unicode代码,而长串的数字就是svg图形数据。(你也可以从iconfont购物车直接下载得到这个文件)
- 修改unicode改变字符和字形的对应关系,你可以使用任意语言直接修改这个类似html格式的svg文件。
- 把svg字体文件转为ttf。Nodejs可以使用svg2ttf模块,把第一步生成的svg文件转为ttf字体文件。
- 使用base64解码读取ttf。在macOS下可以直接使用终端命令
base64 a.svg > a.txt获得base64编码,或者使用Python或其他语音进行base64编码。以下是txt文件的样子。
AAEAAAALAIAAAwAwR1N........YW4IaWNvbmZvbnQNaWNvbmZvbnRfaW5mbwAAAAAA
- 将上面的base64代码嵌入到html页面。参照以下index.html代码(可直接单独使用):
图标字体:鑶
页面效果如下:

其他资源
字体松鼠fontsquirrel,可以自定义字形包,直接下载得到base64数据,注意要选择expert才能看到base64选项。
fontello,同样可以上传自己的svg或者点击网站现有的图标(一定要点),点了之后就可以Customize Codes自定义修改了,58房产就是用的这个网站的API。
百度字体编辑器,功能相似,可以打开现有ttf,也可以深度编辑字形和字符,然后下载ttf或其他字体格式。
阿里iconfont图标库,可以下载数十万各种图标素材,记得一定要加入购物车,然后从购物车下载,可以直接得到svg字体文件。
结语,使用这种字体加密反爬其实没有太多意义,网站既然是公开的,又为什么害怕别人知道你的公开数据呢?但这种加密方法是很强悍的,如果动态扰乱字形名那就真的无解了,如果有的话就只能靠字符图像识别技术了。动态扰乱字形名和字形之间的关系,可以在需要极端保密的场景下真正实现每个页面显示的信息动态加密,当然字形太多的话base64字符数据也会很多,下载很慢。
点击这里进入人工智能DBD嘚吧嘚目录,观看全部文章
每个人的智能新时代
如果您发现文章错误,请不吝留言指正;
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~
END