本篇文章将从头开始介绍Hadoop大数据平台的一系列搭建工作,主要是搭建的具体操作步骤,思想方面涉及甚少,可以自行补充
虚拟机下载安装
我使用的是VMware station12,下载地址为链接:http://pan.baidu.com/s/1geX11pL 密码:uylp
本软件为注册软件现提供一个注册码AV5R2-8LW53-484RP-H5YQZ-XU8RF,大家也可以自行百度。
centos下载
因为工作中常用的为不带可视化界面的版本,现提供一个centos6.8_64下载,地址点我
centos安装
打开安装好的VMware station,右键选择新建虚拟机,选择典型安装。
选择稍后安装操作系统,点击下一步

选择linux操作系统,版本为CentOS64位
输入计算机名称以及你想要安装的位置

指定磁盘容量,这里要说明的是你选择的20G并不会一下占用你20G的硬盘空间,而是跟随你虚拟机大小进行变化的

点击完成即可
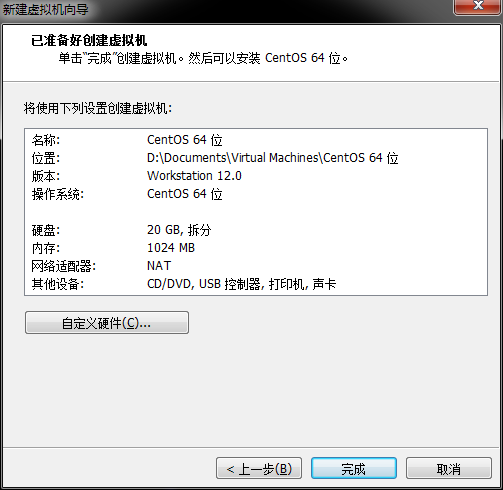
此时你会发现在你VMwarestation左面有了安装的虚拟机,现在需要做两件事。
- 设定虚拟机镜像位置
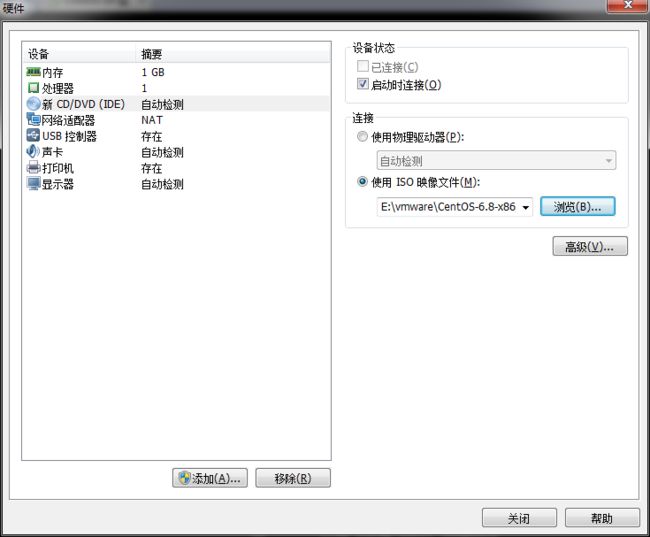
-
更改电脑虚拟化设置。有的电脑并没有开启Intel虚拟化,因此不能安装64位虚拟机。检测的方法是点击开启此虚拟机,如果进入安装界面则证明你的虚拟化是打开的,否则会报错,这时你需要开机进入BIOS,Advanced-CPU Setup将Intel Virtualization Technology和VT-d打开

设置完成后选择开启此虚拟机,进入系统安装界面。这里需要注意的就是skip测试你的安装媒体。剩下的都是可视化的安装,自己选择就可以。

Linux环境配置
可选
1.通过useradd添加用户(创建新用户hadoop):useradd -m hadoop -s /bin/bash
2.为新用户设置密码passwd hadoop
3.给Hadoop用户添加管理员权限 visudo,100行附近root ALL=(ALL)ALL下添加hadoop ALL=(ALL)ALL
- 修改Linux的主机名
-- centos6
输入hostname可以查看现在的主机名称
进入vi /etc/sysconfig/network,修改内容
NETWORKING=yes
HOSTNAME=node-1
进入vi /etc/hosts,修改内容原主机名为node-1
-- centos7
输入hostname可以查看现在的主机名称
进入vi /etc/hostname,直接修改主机名
进入vi /etc/sysconfig/network,修改内容(可以省略)
NETWORKING=yes
HOSTNAME=node-1
进入vi /etc/hosts,修改内容原主机名为node-1
- 修改IP地址
如果你此时执行ifconfig命令你会发现并没有常见的etho网卡,这时因为系统默认没有启动。需要将配置文件改成如下内容。首先进入配置文件vi /etc/sysconfig/network-scripts/ifcfg-eth0(centos7可能不是eth0,可能为ens33,可使用ip addr查看)
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=static
TYPE=Ethernet
IPADDR=192.168.213.100
NETMASK=255.255.255.0
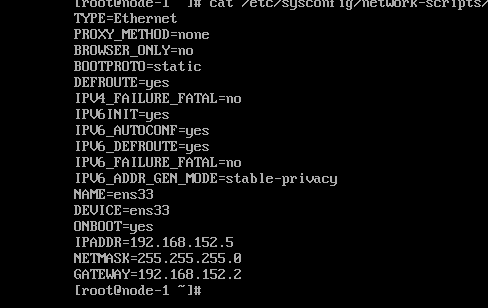
这里需要注意的是ip地址的设置,首先你需要查看你的网络连接方式,我采用默认的NAT模式,从下图可以看到子网地址为192.168.213.0,因此我设置的为192.168.213.100。另外如果你想让虚拟机联网需要设置gateway和dns。
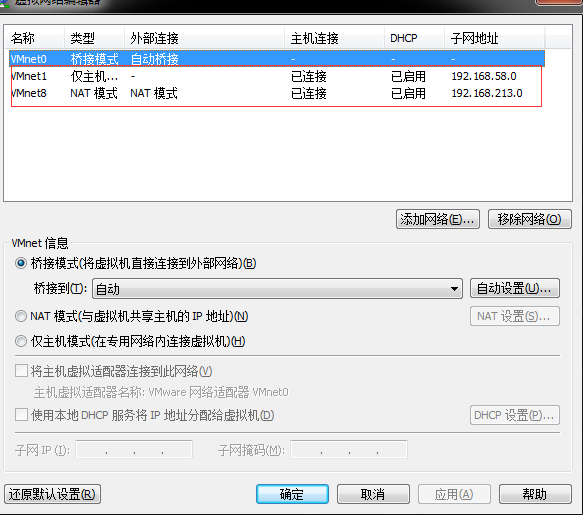
联网配置:选择NAT模式,将网络设置为如下格式,然后再NAT中记录网关地址,填入上面所说的文件中,重启网络服务即可。
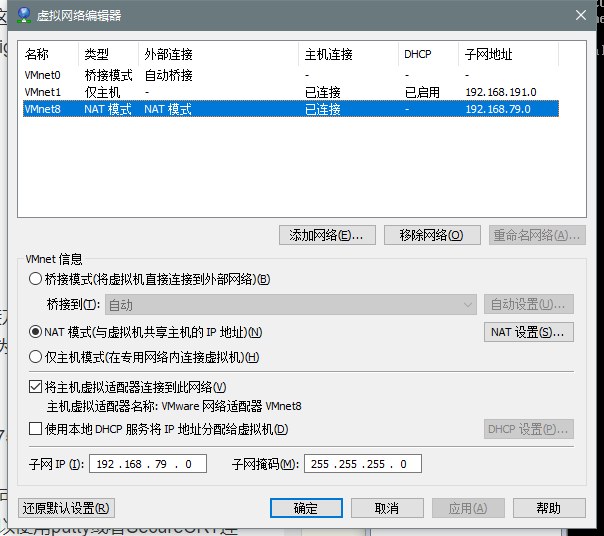
配置好后用
service network restart(centos7为 systemctl restart network.service)重启网络服务,用
ifconfig可以查看是否配置成功。然后可以在Windows上ping该ip查看是否可以ping通。ping通后就可以使用putty或者SecureCRT连接虚拟机了。
- 配置主机名和IP地址的映射关系
vi /etc/hosts打开hosts文件,新增一行192.168.213.100 node-1 - 关闭防火墙
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
设置防火墙开机不启动
chkconfig iptables off
//centos7 临时关闭
systemctl stop firewalld
//centos7 禁止开机启动
systemctl disable firewalld

最后reboot或者通过hostname node-1以及exit,使我们配置的主机名生效 - centos7 yum源设置
yum install wget
cd /etc/yum.repos.d/
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
- 删除Mac地址与网卡映射文件(centos7可省略)
我们想将这个虚拟机作为模板机,为了避免以后Mac地址冲突,因此要删除Mac地址与网卡映射文件,以后启动机器的时候会自动生成。
rm -rf /etc/udev/rules.d/70-persistent-net.rules
然后用halt关机
创建克隆机
做大数据肯定不可能只有一个虚拟机,我们现在用配置好的这台机器,克隆出几台虚拟机出来。
- 选择模板机,然后点击右键 –> 选择Manage –> clone ->创建一个完整的克隆 –>
->配置机器的名字和存放位置 - 开启虚拟机之前一定要生成一个新的mac地址(centos7可省略)
- 开启虚拟机,修改其主机名和ip地址
如果在执行service network restart命令时出现以下错误,则可能是没有删除模板机Mac地址与网卡映射文件,注意这个文件每次启动都会自动生成的。解决方法是rm -rf /etc/udev/rules.d/70-persistent-net.rules删除该文件然后重启
都修改完成后可以用一台虚拟机依次ping其它虚拟机,可以ping通即可
修改hosts文件
在101机器上修改hosts文件,完成主机名和ip地址映射

ssh免密码登录
- 在第一台机器上生成一对钥匙,一个公钥,一个私钥
ssh-keygen –t rsa执行上面的命令后,输入四个回车 - 将公钥拷贝到希望名登录的机器
ssh-copy-id 192.168.213.102执行上面的命令第一次要输入第二台机器的密码 - 然后执行scp操作就不需要输入密码了
scp /etc/hosts [email protected]:/etc,现在可以将修改好的hosts文件发送到其他具有公钥的机器。
注意这种免密码登录是单向的,如果想相互免密码登录则需要在每一台机器上都生成一个公钥和一个私钥。
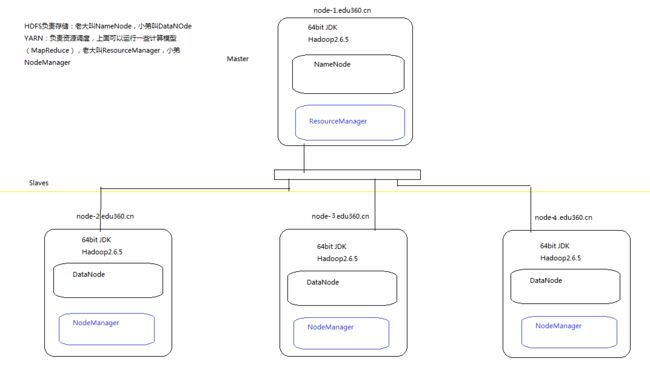
Hadoop集群规划
现在我们有四台机器,分别为node-1,node-2,node-3,node-4,我们要做成下图形式的架构。第一台作为主节点,其他三台作为从节点
Java安装
将安装包上传到虚拟机上
- 安装Java
- 创建文件夹
mkdir /usr/java - 解压
tar -zxvf jdk.tar.gz -C /usr/java - 添加环境变量
进入文件vi /etc/profile,按G到文件末尾,按o插入一行,加入下面语句
export JAVA_HOME=/usr/java/jdk1.8.0_111
export PATH=$PATH:$JAVA_HOME/bin
执行source /etc/profile重新加载环境变量 - 若需要传到其他虚拟机上则
scp –r /usr/java/ node-2:/usr
scp /etc/profile node-2:/etc
- 创建文件夹
Hadoop安装
解压Hadoop
mkdir /bigdata
tar -zxvf hadoop-2.6.5.tar.gz -C /bigdata/在Hadoop安装包目录下有几个比较重要的目录
sbin : 启动或停止Hadoop相关服务的脚本
bin :对Hadoop相关服务(HDFS,YARN)进行操作的脚本
etc : Hadoop的配置文件目录
share :Hadoop的依赖jar包和文档,文档可以被删掉
lib :Hadoop的本地库(对数据进行压缩解压缩功能的)修改配置文件
进入到Hadoop的etc目录下
cd /bigdata/hadoop-2.6.5/etc/hadoop
修改第1个配置文
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
修改第2个配置文件
vi core-site.xml
fs.defaultFS
hdfs://node-1:9000
hadoop.tmp.dir
/bigdata/hadoop-2.6.5/tmp
修改第3个配置文件
vi hdfs-site.xml
dfs.replication
3
修改第4个配置文件
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
修改第5个配置文件
vi yarn-site.xml
yarn.resourcemanager.hostname
node-1
yarn.nodemanager.aux-services
mapreduce_shuffle
第6个配置文件slaves
vi slaves
原来的localhost要删掉
node-2
node-3
node-4
将配置好的Hadoop安装包拷贝到其他服务上
scp -r /bigdata node-2:/
scp -r /bigdata node-3:/
scp -r /bigdata node-4:/
在第一台机器(NameNode所在的机器)上对hdfs进行初始化(格式化HDFS)
cd /bigdata/hadoop-2.6.5/bin/
./hdfs namenode -format
配置自己到自己的免密码登录,输入当前机器的密码
ssh-copy-id node-1
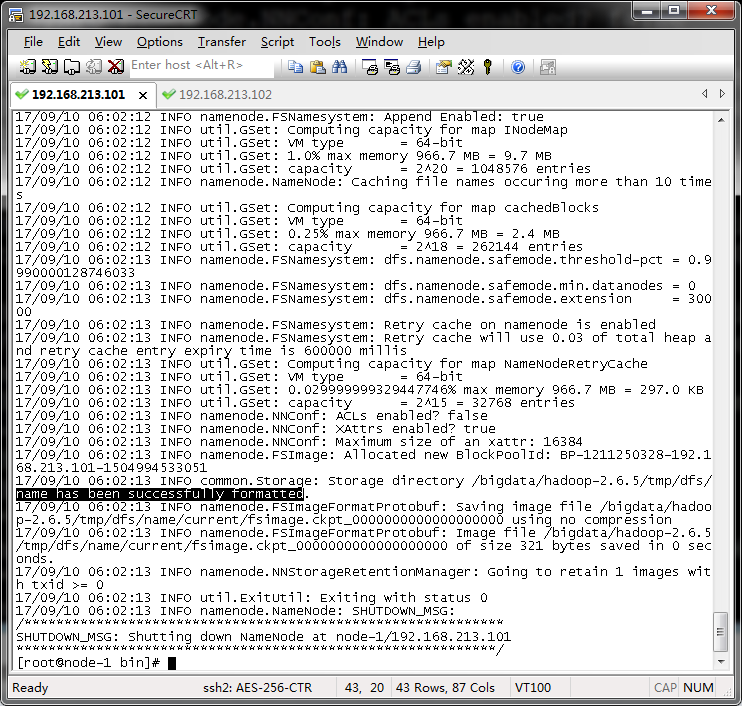
在第一台机器(NameNode所在的机器)上对hdfs进行初始化(格式化HDFS)
cd /bigdata/hadoop-2.6.5/bin/
./hdfs namenode -format
格式化成功的标志是出现以下提示
配置自己到自己的免密码登录,输入当前机器的密码
ssh-copy-id node-1
启动并测试Hadoop
cd /bigdata/hadoop-2.6.5/sbin/
./start-dfs.sh
./start-yarn.sh
可以使用jps检查进程是否存在


也可以访问网页测试
访问hdfs的管理界面
192.168.213.101:50070
访问yarn的管理界面
192.168.213.101:8088

关闭hdfs/yarn服务
./stop-dfs.sh
./stop-yarn.sh
上传文件到HDFS上
上传文件
/bigdata/hadoop-2.6.5/bin/hdfs dfs -put /root/install.log hdfs://node-1:9000/
查看文件信息
/bigdata/hadoop-2.6.5/bin/hdfs dfs -ls hdfs://node-1:9000/

HDFS动态扩容
查看现在DataNode情况可以在Hadoop的bin目录下执行./hdfs dfsadmin -report,可以看到存活的DataNode。现在为3个。
下面为扩容的具体步骤:
- 准备一台新的服务器(最好是跟原集群的机器相同配置)
- 为新的服务器准备系统环境(主机名、IP地址、防火墙、JDK环境、hosts文件)
- 将新的服务器连入原集群网络(测试是否可以ping通)
- 从原集群中拷贝一个hadoop的安装目录到新节点上,并且删除原datanode的工作目录(这里配置的为tmp目录)
- 修改/bigdata/hadoop-2.6.5/etc/hadoop/slaves 文件,加入新节点的主机名
- 在新节点上用命令:hadoop-daemon.sh start datanode 启动datanode,就会自动加入集群
- 重启start-dfs,start-yarn
hadoop集群恢复终极解决方案
- 在每一台机器上用命令杀掉所有java进程: killall java
- 在每一台机器上删掉hadoop安装目录中的tmp文件夹
- 在node-1上格式化namenode: hadoop namenode -format
- 在node-1上执行脚本来启动整个集群: start-dfs.sh
注意用这种方案会重新格式化hdsf,意味着原来上传的文件会全部丢失!!!
补充:关闭HDFS集群的命令:在node-1上: stop-dfs.sh
关闭YARN集群的命令:在node-1上: stop-yarn.sh