1.ElasticSearch基本使用
2.ES单机安装:
3.ES索引基本操作
4.ES集群环境搭建
5.cerebro状态检查
6.集群节点
7.ES集群状态检查
ELK基础架构
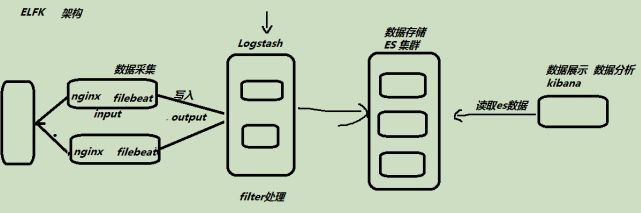
elk架构.png
E: elastcisearch 数据搜索 数据存储 java
L: Logstash 数据收集 ( 数据解析数据转换 ) 数据输出 java
F: Filebeat 数据采集 (简单的数据处理 ) <--go
K:Kibana 数据分析 数据展示

elk日志.png
1.ElasticSearch基本使用

基本使用.png
准备节点
ES7
10.0.0.7 172.16.1.7 nginx+filebeat
10.0.0.8 172.16.1.8 nginx+filebeat
10.0.0.141 172.16.1.141 kafka
10.0.0.141 172.16.1.141 kafka
10.0.0.141 172.16.1.141 kafka
10.0.0.151 172.16.1.151 Logstash
10.0.0.152 172.16.1.152 Logstash
10.0.0.161 172.16.1.161 es-node1 ES Kibana
10.0.0.162 172.16.1.162 es-node2
10.0.0.163 172.16.1.163 es-node3
2.ES单机安装:
[root@es-node1 ~]# yum install java -y
[root@es-node1 ~]# rpm -ivh elasticsearch-7.4.0-x86_64.rpm kibana-7.4.0-x86_64.rpm
[root@es-node1 ~]# vim /etc/elasticsearch/jvm.options-Xms512m
实验环境 生产环境最少内存一半以上 官方建议 最高
32Gb
-Xmx512m
[root@es-node1 ~]# systemctl enable elasticsearch.service
[root@es-node1 ~]# systemctl start elasticsearch.service
测试es是否启动
[root@es-node1 ~]# curl 127.0.0.1:9200
{
"name" : "es-node1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "l8qVNdklSvSqjUJSvUh4dw",
"version" : {
"number" : "7.4.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" :
"22e1767283e61a198cb4db791ea66e3f11ab9910",
"build_date" : "2019-09-27T08:36:48.569419Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-
beta1"
},
"tagline" : "You Know, for Search"
}
修改kibana的配置
[root@es-node1 ~]# vim /etc/kibana/kibana.yml
server.host: "0.0.0.0"
i18n.locale: "zh-CN"
启动kibana
[root@es-node1 ~]# systemctl enable kibana
[root@es-node1 ~]# systemctl start kibana
访问kibana
3.ES索引基本操作
创建一个索引
PUT /oldxu_es
查看所有的索引
GET _cat/indices
删除索引
DELETE /oldxu_es
给oldxu_es索引录入一个文档
POST /tt/_doc/1
{
"name": "oldxu",
"age": 18,
"salary": 1000000000
17 }
18
19 POST /oldxu_es/_doc/2
{
"name": "oldguo",
"age": 35,
"salary": 100
}
获取指定的id数据
GET /oldxu_es/_doc/1
获取所有的文档 默认前10个
GET /oldxu_es/_search
模糊查询
GET /oldxu_es/_search
{
"query": {
"term": {
"name": "oldxu"
}
}
}
删除指定id的文档
DELETE /oldxu_es/_doc/1
POST _bulk
{"index":{"_index":"tt","_id":"1"}}
{"name":"oldxu","age":"18"}
{"create":{"_index":"tt","_id":"2"}}
{"name":"oldqiang","age":"30"}
{"delete":{"_index":"tt","_id":"2"}}
{"update":{"_id":"1","_index":"tt"}}
{"doc":{"age":"20"}}
一次查询多个文档
GET _mget
{
"docs": [
{
"_index": "tt",
"_id": "1"
},
{
"_index": "tt",
"_id": "2"
}
]
}
4.ES集群环境搭建
1.配置集群
删除所有的es相关的数据 (集群无法组件的情况)
[root@es-node1 ~]# rm -rf /var/lib/elasticsearch/*
[root@es-node1 ~]# systemctl stop elasticsearch.service
[root@es-node1 ~]# systemctl stop kibana
配置node1
[root@es-node1 ~]# grep '^[a-Z]' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-oldxu
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.161", "10.0.0.162","10.0.0.163"]
cluster.initial_master_nodes: ["10.0.0.161","10.0.0.162", "10.0.0.163"]
scp -rp /etc/elasticsearch/elasticsearch.yml [email protected]:/etc/elasticsearch/elasticsearch.yml
scp -rp /etc/elasticsearch/elasticsearch.yml [email protected]:/etc/elasticsearch/elasticsearch.yml
scp /etc/elasticsearch/jvm.options [email protected]:/etc/elasticsearch/jvm.options
scp /etc/elasticsearch/jvm.options [email protected]:/etc/elasticsearch/jvm.options
配置node2
[root@es-node2 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-oldxu
node.name: node2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.161", "10.0.0.162", "10.0.0.163"]
cluster.initial_master_nodes: ["10.0.0.161", "10.0.0.162", "10.0.0.163"]
配置node3
[root@es-node3 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-oldxu
node.name: node3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.161", "10.0.0.162", "10.0.0.163"]
cluster.initial_master_nodes: ["10.0.0.161", "10.0.0.162", "10.0.0.163"]
启动所有节点
systemctl start elasticsearch
通过 curl 检查集群环境是否正常
curl http://10.0.0.163:9200/_cluster/health?pretty
kibana
GET /_cluster_health
5.cerebro状态检查
cerebro插件来检查整个集群的环境 默认监听9000端口
[root@es-node1 ~]# rpm -ivh cerebro-0.8.5-1.noarch.rpm
[root@es-node1 ~]# vim /etc/cerebro/application.conf
data.path = "/tmp/cerebro.db"
[root@es-node1 ~]# systemctl enable cerebro
访问:10.0.0.161:9000
登陆:http://10.0.0.161:9200
6.集群节点
master角色: 负责控制整个集群的操作, 通过cluter_status状态维护集群.
选举: cluster.initial_master_nodes master-eligible
可以不参与选举: node.master: false cluster_state: 节点信息 索引信息
data角色: 存储数据 (默认都是data节点) 关闭data: node.data: false
coordinating角色 : 负责路由 不能取消
7.ES集群状态检查

健康检查.png
shard = hash(routing) % number_of_primary_shards
hash 算法保证将数据均匀分散在分片中
routing 是一个关键参数,默认是文档id,也可以自定义。
number_of_primary_shards 主分片数
注意:该算法与主分片数相关,一但确定后便不能更改主分片。
因为一旦修改主分片修改后,Share的计算就完全不一样了。