datax是什么
- 阿里开源的ETL工具(github地址:https://github.com/alibaba/DataX
),ETL是描述从数据源读取数据,经过转换,再加载到目的数据源的过程,而datax是对这一过程的实现,采用framework+plugin框架模式。
 image.png
image.png
| 比对 | ETL | datax | 功能 |
|---|---|---|---|
| 数据抽取 | Extract | Reader-plugin | 从数据源读取数据,传输到framework |
| 转换 | transport | Framework | 对数据进行转换、清洗、并发、流量控制 |
| 数据写入 | load | Writer-Plugin | 从framework读取数据,写入目标数据源 |
为什么选择datax
- 可靠稳定,性能强,市场广泛使用,经得起时间和市场的考验
- 活跃的社区,完善的使用文档
- 上手容易,配置简单,学习成本低
- 插件支持的数据源覆盖范围广
- 提供自定义插件扩展功能,可根据需求自主开发插件
- 完善的运行日志打印与监控,能够迅速通过日志分析、定位问题,例如总体的运行情况日志如下
任务启动时刻 : 2019-09-17 10:44:56
任务结束时刻 : 2019-09-17 10:45:18
任务总计耗时 : 22s
任务平均流量 : 492.72KB/s
记录写入速度 : 8594rec/s
读出记录总数 : 171895
读写失败总数 : 0
datax的运行机制
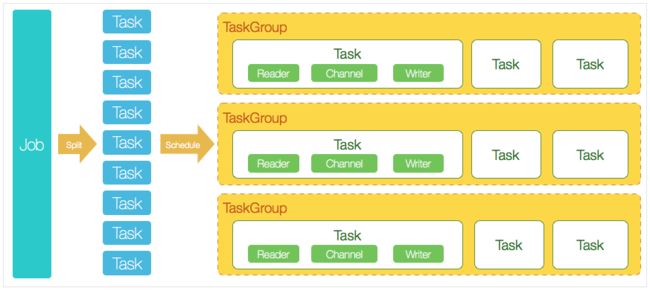
image.png
- job :数据同步的作业,是datax运行最小业务单元
- task:任务,job拆分出来的最小执行单元
- taskGroup:任务组,管理一组task的集合
- jobContainer:任务容器,用于任务拆分、调度,日志打印等工作
- taskGroupContainer:任务执行的容器
如何使用datax
$ python datax.py {YOUR_JOB.json}
- datax.py是datax工具提供的python脚本,目录{datax目录/bin}
- {YOUR_JOB.json} 是datax作业(job)的配置文件,示例如下
{
#全局配置
"core":{
"transport":{
"channel":{
"speed":{
"channel": 2, #job任务通道数,控制并发的线程数
"record":-1, #限制数据传输的记录数
"byte":-1, #限制数据传输的流量大小
"batchSize":2048 #限制批量读取的size
}
}
}
},
#任务配置
"job": {
"content": [
{
"reader": {
"name": "",#插件名称
"parameter": {
"connection": [#连接信息
{
"jdbcUrl": [""],
"querySql": [
""
],
"table": [""]
}
],
"column": [],
"splitPk":"",#分片键,
"where":"",#查询限制条件
"password": "",
"username": "",
}
},
"writer": {
"name": "",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": [""]
}
],
"password": "",
"username": ""
}
}
}
],
"setting": {
"speed": {
"channel":5,
"record":1000,
},
"errorLimit": {#脏数据阈值配置
"record":2,
"percentage": 0.02
}
}
}
}
datax的性能调优
datax性能影响因素
服务器性能:内存、存储,IO
网络环境:宽带大小、网络稳定性
-
配置文件参数的优化
- datax脚本运行时的内存大小配置
python datax.py --jvm '-Xms1G -Xmx1G' {YOUR_JOB.json} - 调整job任务的限速、限流及并发线程数
"speed":{ "channel": 2, #job任务通道数,控制并发的线程数 "record":-1, #限制数据传输的记录数 "byte":-1, #限制数据传输的流量大小 "batchSize":2048 #限制批量读取的size } 注: channel:并发数,默认为5,即5个并发,每次可执行task数为5 例:channel配置为20个并发,就需要4个taskGroup,如果作业有100个 task,那么每个group管理25个task。 byte:限流,在带宽允许条件下合理配置,-1为不限制,往往会出现带宽占用 过高的问题。 - datax脚本运行时的内存大小配置
案例分析
问题:数据库A的t_a表数据(275w数据量)同步到数据库B的t_b表,迁移逻辑:

image.png
表结构如下:
CREATE TABLE `t_a` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`phone` varchar(11) NOT NULL,
`nick_name` varchar(45) DEFAULT NULL,
`user_name` varchar(45) DEFAULT NULL,
`sex` tinyint(2) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`created_user` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`created_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`modified_user` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`modified_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `t_b` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`mobile` varchar(11) NOT NULL,
`nick_name` varchar(45) DEFAULT NULL,
`user_name` varchar(45) DEFAULT NULL,
`sex` tinyint(2) DEFAULT NULL,
`age` int(4) DEFAULT NULL,
`created_user` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`created_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`modified_user` varchar(45) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`modified_date` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
实现方案
- 基础datax脚本:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["A"],
"querySql": [
"SELECT id,phone,nick_name,user_name,sex,age,created_user,created_date,modified_user,modified_date from t_a"
]
}
],
"password": "",
"username": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","mobile","nick_name","user_name","sex","age","created_user","created_date","modified_user","modified_date"],
"connection": [
{
"jdbcUrl": "B",
"table": ["t_b"]
}
],
"password": "",
"username": ""
}
}
}
]
}
}
- 执行结果总体情况:
任务启动时刻 : 2019-09-18 14:38:12
任务结束时刻 : 2019-09-18 14:41:53
任务总计耗时 : 221s
任务平均流量 : 251.45KB/s
记录写入速度 : 12501rec/s
读出记录总数 : 2750323
读写失败总数 : 0
- 对datax进行优化,开启多线程模式,channel配置必须与splitPk结合使用才能生效
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","mobile","nickname","username","gender","20 as age"],
"connection": [
{
"jdbcUrl": [""],
"table": ["tmp_member_all"]
}
],
"splitPk":"id",
"password": "",
"username": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["id","phone","nick_name","user_name","sex","age"],
"connection": [
{
"jdbcUrl": "A",
"table": ["t_b"]
}
],
"password": "",
"username": ""
}
}
}
],
"setting": {
"speed": {
"channel":5
}
}
}
}
任务执行的总体情况
任务启动时刻 : 2019-09-18 15:02:58
任务结束时刻 : 2019-09-18 15:03:59
任务总计耗时 : 61s
任务平均流量 : 921.97KB/s
记录写入速度 : 45838rec/s
读出记录总数 : 2750323
读写失败总数 : 0