本文主要讨论的是预训练InceptionV3如何定义不同的输入以及输出,并展示了提取不同inception模型节点的迁移学习效果
网上很容易找到关于InceptionV3模型迁移学习的文章
但是这些文章都是一致的读取JPG作为二进制输入,选择BOTTLENECK作为输出,但是我的输入是一个图片矩阵,不想那么笨的将一个个图片矩阵写成JPG图片,就对InceptionV3
的结构进行了一下探索
1.常规的加载模型的PB文件,定义各tensor

主要问题是假如我的输入是矩阵,不能直接用参考文章中的JPEG_INPUT作为输入。那么要怎么找到这个矩阵tensor的定义呢?
我的想法是,既然加载了模型到计算图中,利用tensorboard强大的功能,可以显示计算图的结构,那么从这个结构中就知道怎么定义不同格式的输入了
2.得到计算图
只需要定义与加载好InceptionV3的模型后,利用常规的tensorboard的写入图函数就能得到计算图
然后打开tensorboard就能得到图结构
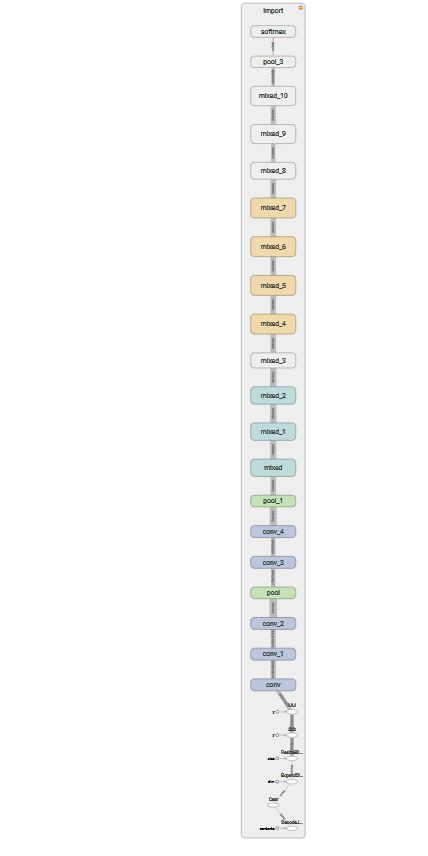
然后我们仔细看stem的输入部分
可以看到假如我们直接读取JPG文件,输入到计算图中的是一个标量
DecodeJpeg/contents:0
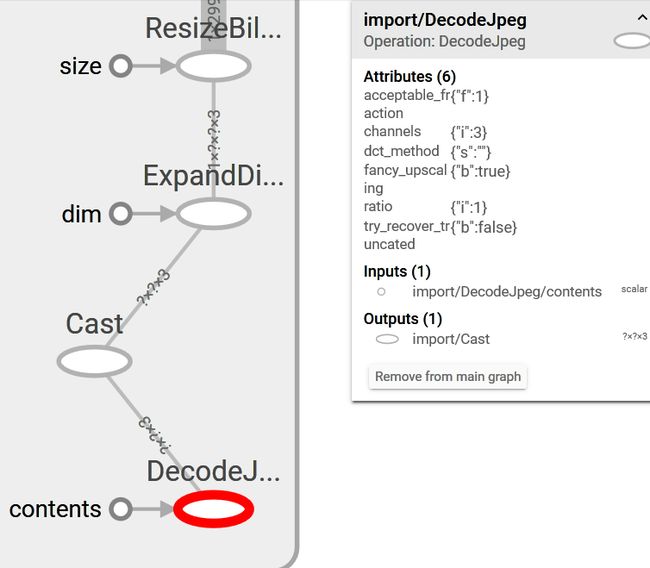
因为我的输入就是 一 N*229*229*3的图片矩阵,我想要直接将这个矩阵输入到计算图中,仔细看图的结构
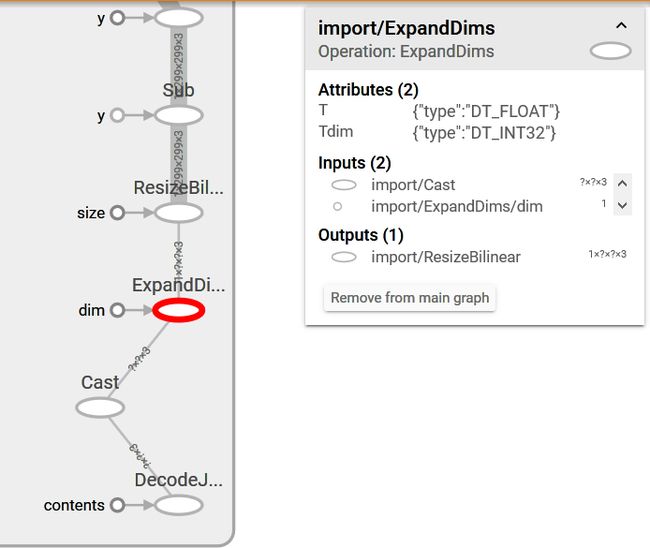
会看到Cast节点可以接受任意尺寸的矩阵输入,然后再扩展维度为 (1,?,?,3)的图片矩阵,最后统一resize为(1,229,229,3)的图片矩阵
所以也就是说这个模型时不支持batch输入的,必须要一张一张或者是一个一个图片矩阵输入才可以。
因为我的输入就是 229*229*3的矩阵,那么直接定义想要用的节点
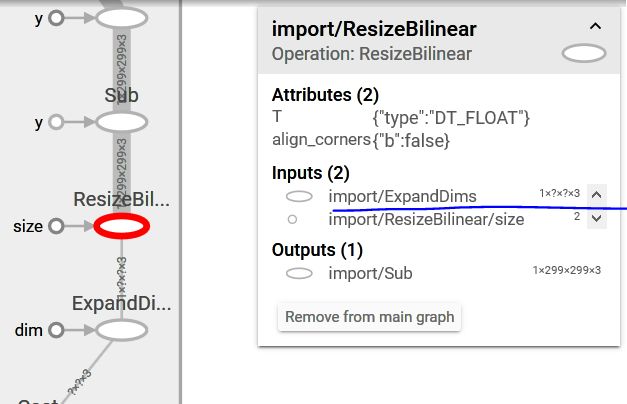
ExpandDims:0
作为输入就可以,输入可以是任意的H,W,只需要保证输入格式是(1,H,W,3)就可以了
同理,可以修改想要的输出节点
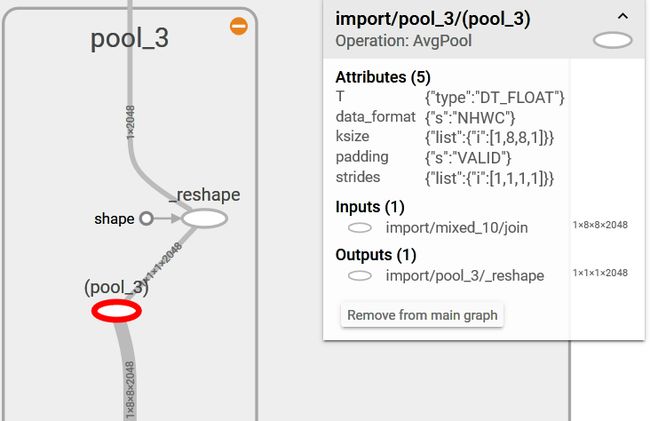
文章后面尝试了pool_3的输入节点作为特征,并比较了效果
效果
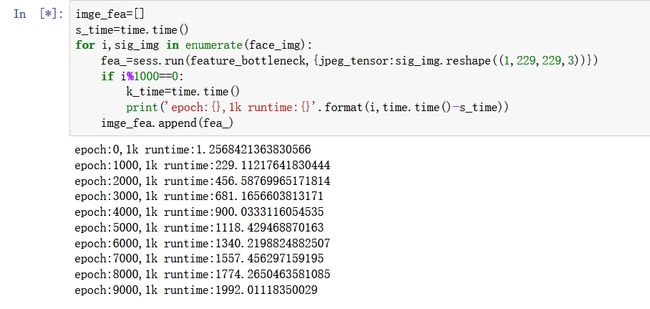
我的face_img是一个(10000,229,229,3)的大矩阵,需要一个个的输入这个图片矩阵
大概转换一个图片矩阵为特征的话需要0.2秒的时间
实验:
inception 不同节点的迁移学习
1.只提取BottleNeck的输出,也就是图片提取的特征为(1,2048)
当前我的项目上刚好需要对一个新的数据集进行分类,我的数据集大概有 50000张图片,分类有16种
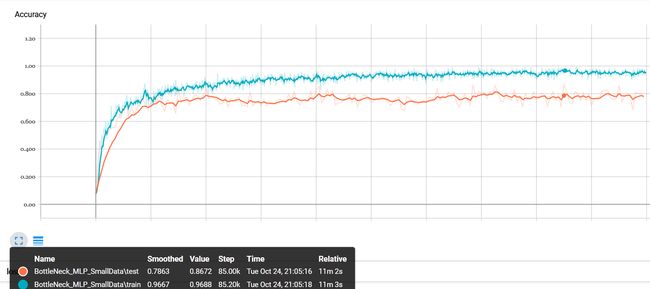
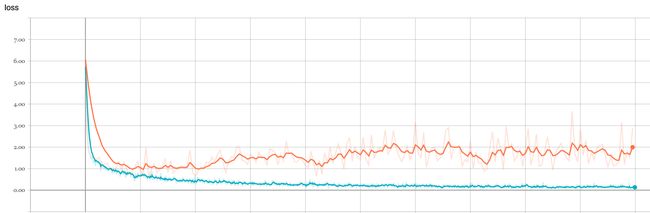
(1)将所有图片输入到inception模型中,输出为bottleneck节点,然后再建立3层的全连接神经网络对这些特征进行分类,实验结果还是效果不错,以及比自己重新建立一个CNN网络的表现要好了,在经过比较短的时间训练后在验证集上的到了80%左右的准确率。
由于训练的是全连接神经网络,增加训练时间很可能会使得网络过拟合,所以这个方法的准确率大概为80%,效果已经很好了
2.提取更靠前节点的输出
按照inceptionv3的计算图结构,可以看到bottleneck前面接的是一个pool层,pool层前面是一个inception block,我选择提取池化前的特征,特征维度为 (1,8,8,2048)
按照前面所说的方法,找点这个节点的名称,就能够提取到这部分的特征


将所有图片输入网络,提取出这个节点的特征后保存
提取的特征维度为 : (50000,8,8,2048)且每个数为32位浮点数,假如一次加载到内存中大概需要25GB的内存,所以我选择将这些特征数据分成10小份,每份大小为2.5G左右
然后训练一个卷积网络对这些特征进行分类,我选择的网络结构为:
conv1: 2048@3*3/1 (N,8,8,2048) -> (N,6,6,2048)
conv2: 2048@3*3/1 (N,6,6,2048) -> (N,4,4,2048)
conv3: 2048@3*3/1 (N,4,4,2048) -> (N,2,2,2048)
FC4: 2048 (N,2*2*2048) -> (N,2048)
FC5: 1024 (N,2048) -> (N,1024)
FC6: 16 (N,1024) -> (N,16)
最后输出为 FC6层
在经过5小时的训练后,网络在验证集上的准确率大概收敛在93%左右。这还只是粗略的训练,没有对网络进行调参
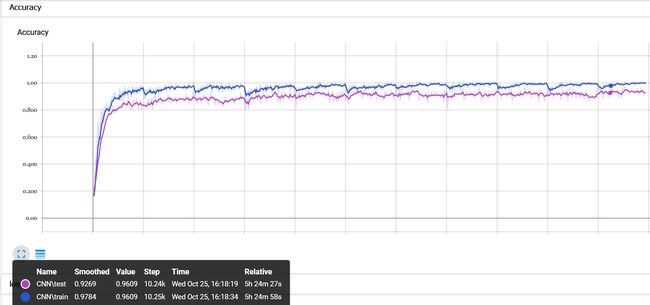

结论:
假如你在自己的项目上有比较小的数据集,而又想利用深度学习方案解决这个问题,这时候利用迁移学习得到的结果肯定是比重新训练一个新的CNN网络要好很多。假如只利用BOTTLENECK的输入分类得到的效果不好,可以尝试提取更加高维度的特征,这样得到的结果会更加好