本章包含内容:
- 前言
- mongodb环境配置
- 爬取数据的代码分析
一、前言
在更新完上一篇python文章时,就一直想爬取一个10万量级的数据。在解了mongodb的基本用法和环境配置后,第一次测试的是安居客的二手房,遇到了很多小问题,最终没能继续下去。今天这次测试的是赶集网的跳蚤市场商品,在经过几次调试,最终程序得以正常运行。可惜的是赶集网跳蚤市场数据总数也才4万多条,没有达到目标的10万条数据。但麻雀虽小,五脏俱全,虽然数据量没有达到,但最终爬取的原理却是一样的,下面将一一分析本次爬取的代码。
二、mongodb环境配置

1

2

3
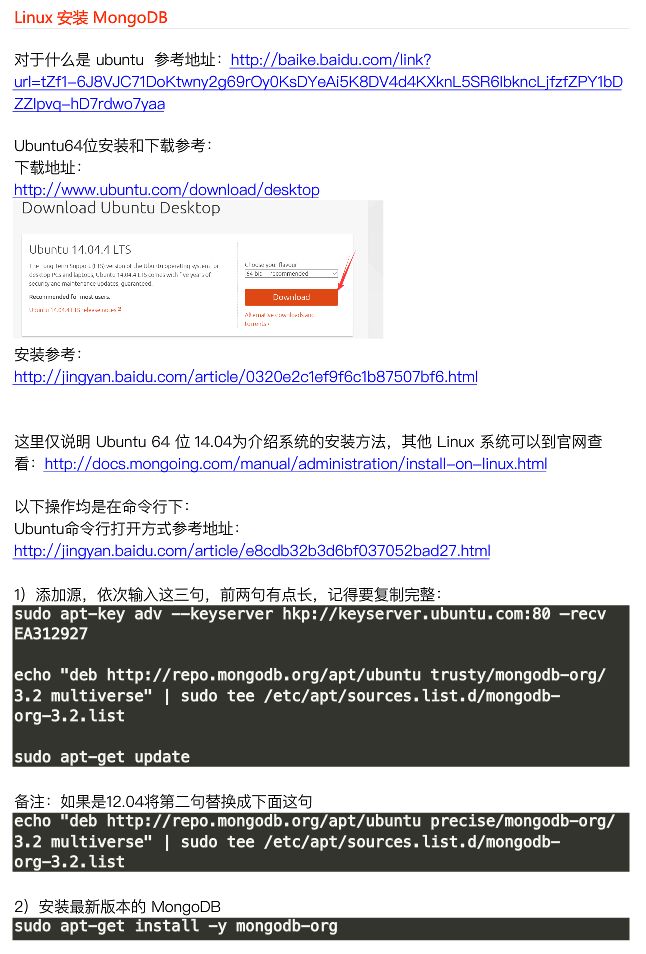
4
5

6

7

8

9

10

11
12

13

14
三、爬取数据的代码分析
1.首先爬取跳蚤市场各个分类的入口链接
from bs4 import BeautifulSoup
import requests
url = 'http://bj.ganji.com/wu/'
url_host = 'http://bj.ganji.com'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
mainUrlStrs = soup.select('.fenlei > dt > a')
for mainUrlStr in mainUrlStrs:
#拼接
print(url_host + mainUrlStr.get('href'))
#输出:
http://bj.ganji.com/jiaju/
http://bj.ganji.com/rirongbaihuo/
http://bj.ganji.com/shouji/
http://bj.ganji.com/shoujihaoma/
http://bj.ganji.com/bangong/
http://bj.ganji.com/nongyongpin/
http://bj.ganji.com/jiadian/
http://bj.ganji.com/ershoubijibendiannao/
http://bj.ganji.com/ruanjiantushu/
http://bj.ganji.com/yingyouyunfu/
http://bj.ganji.com/diannao/
http://bj.ganji.com/xianzhilipin/
http://bj.ganji.com/fushixiaobaxuemao/
http://bj.ganji.com/meironghuazhuang/
http://bj.ganji.com/shuma/
http://bj.ganji.com/laonianyongpin/
http://bj.ganji.com/xuniwupin/
http://bj.ganji.com/qitawupin/
http://bj.ganji.com/ershoufree/
http://bj.ganji.com/wupinjiaohuan/
在经过筛选,剔除不符合需求的入口链接,比如手机号码之类的入口,这就是我们需要的入口:
http://bj.ganji.com/jiaju/
http://bj.ganji.com/rirongbaihuo/
http://bj.ganji.com/shouji/
http://bj.ganji.com/bangong/
http://bj.ganji.com/nongyongpin/
http://bj.ganji.com/jiadian/
http://bj.ganji.com/ershoubijibendiannao/
http://bj.ganji.com/ruanjiantushu/
http://bj.ganji.com/yingyouyunfu/
http://bj.ganji.com/diannao/
http://bj.ganji.com/xianzhilipin/
http://bj.ganji.com/fushixiaobaxuemao/
http://bj.ganji.com/meironghuazhuang/
http://bj.ganji.com/shuma/
http://bj.ganji.com/laonianyongpin/
http://bj.ganji.com/xuniwupin/
2.根据入口链接爬取商品信息,同时写入数据库(核心代码)
from bs4 import BeautifulSoup
import requests
import random
import pymongo
#连接mongoDB数据库
#参数localhost:表示在本地数据库
#参数27017:端口,表示指向哪
client = pymongo.MongoClient('localhost',27017)
#创建数据库名称
ganjiwang = client['ganjiwang']
#创建数据表
list_info = ganjiwang['list_info']
#赶集网headers信息
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Connection':'keep-alive'
}
#随机IP,因为同一个IP频繁请求,服务器将会视其为黑客攻击,所有我们会随机分配IP来请求
proxy_list = [
'http://125.88.74.122:85',
'http://125.88.74.122:83',
'http://171.8.79.143:8080',
'http://14.152.93.79:8080',
]
proxy_ip = random.choice(proxy_list) # 随机获取代理ip
proxies = {'http': proxy_ip}
#爬取网页信息的核心代码,该函数可以写的有点笨,可再次做优化,这里只为实现需求,不再优化
def get_list_info(url,data=None):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
# print(soup)
#当是该类商品最后一页是,即没有更多商品时,我们pass掉
if soup.find('div','no-search') or soup.find('div','noinfo'):
print('已经到最后一页')
pass
elif url.find('http://bj.ganji.com/bangong/') == 0:
#二手设备
print('二手设备')
titles = soup.select('.js-item > a')
imgs = soup.select('.list-bigpic > dt > a > img')
prices = soup.select('.pt-price > span')
locations = soup.select('.feature > span')
for title,img,price,location in zip(titles,imgs,prices,locations):
print(title.text)
print(title.get('href'))
print(img.get('data-original')) if img.get('data-original') else print(img.get('src'))
print(price.text)
print(location.text) if len(location.text) != 0 else print('无')
infoTitle = title.text
infoDetailUrl = title.get('href')
infoImgUrl = img.get('data-original') if img.get('data-original') else img.get('src')
infoPrice = price.text
infoDetailText = '无'
infoLocation = location.text if len(location.text) != 0 else '无'
#写入数据库
list_info.insert_one({'title':infoTitle,
'detailUrl':infoDetailUrl,
'img':infoImgUrl,
'price':infoPrice,
'detailText':infoDetailText,
'location':infoLocation})
elif url.find('http://bj.ganji.com/nongyongpin/') == 0:
#二手农用品
# print('二手农用品')
titles = soup.select('.js-item > a')
imgs = soup.select('.list-bigpic > dt > a > img')
prices = soup.select('.pt-price > span')
locations = soup.select('.list-word > a')
for title,img,price,location in zip(titles,imgs,prices,locations):
print(title.text)
print(title.get('href'))
print(img.get('data-original')) if img.get('data-original') else print(img.get('src'))
print(price.text)
print(location.text) if len(location.text) != 0 else print('无')
infoTitle = title.text
infoDetailUrl = title.get('href')
infoImgUrl = img.get('data-original') if img.get('data-original') else img.get('src')
infoPrice = price.text
infoDetailText = '无'
infoLocation = location.text if len(location.text) != 0 else '无'
list_info.insert_one({'title':infoTitle,
'detailUrl':infoDetailUrl,
'img':infoImgUrl,
'price':infoPrice,
'detailText':infoDetailText,
'location':infoLocation})
elif url.find('http://bj.ganji.com/xianzhilipin/') == 0:
#二手闲置礼品
print('二手闲置礼品')
titles = soup.select('.js-item > a')
imgs = soup.select('.list-bigpic > dt > a > img')
prices = soup.select('.pt-price > span')
details = soup.select('.feature > p')
locations = soup.select('.list-word > a')
for title,img,price,detail,location in zip(titles,imgs,prices,details,locations):
print(title.text)
print(title.get('href'))
print(img.get('data-original')) if img.get('data-original') else print(img.get('src'))
print(price.text)
print(detail.text)
print(location.text)
infoTitle = title.text
infoDetailUrl = title.get('href')
infoImgUrl = img.get('data-original') if img.get('data-original') else img.get('src')
infoPrice = price.text
infoDetailText = detail.text
infoLocation = location.text if len(location.text) != 0 else '无'
list_info.insert_one({'title':infoTitle,
'detailUrl':infoDetailUrl,
'img':infoImgUrl,
'price':infoPrice,
'detailText':infoDetailText,
'location':infoLocation})
elif url.find('http://bj.ganji.com/xuniwupin/') == 0:
#二手虚拟物品
print('二手虚拟物品')
titles = soup.select('.js-item > a')
imgs = soup.select('.list-bigpic > dt > a > img')
prices = soup.select('.pt-price > span')
details = soup.select('.feature > p')
locations = soup.select('.list-word > a')
for title,img,price,detail,location in zip(titles,imgs,prices,details,locations):
print(title.text)
print(title.get('href'))
print(img.get('data-original')) if img.get('data-original') else print(img.get('src'))
print(price.text)
print(detail.text)
print(location.text)
infoTitle = title.text
infoDetailUrl = title.get('href')
infoImgUrl = img.get('data-original') if img.get('data-original') else img.get('src')
infoPrice = price.text
infoDetailText = detail.text
infoLocation = location.text if len(location.text) != 0 else '无'
list_info.insert_one({'title':infoTitle,
'detailUrl':infoDetailUrl,
'img':infoImgUrl,
'price':infoPrice,
'detailText':infoDetailText,
'location':infoLocation})
else:
#非二手设备、二手农用品
titles = soup.select('.t > a')
imgs = soup.select('.js-lazy-load')
prices = soup.select('.pricebiao > span')
details = soup.select('.desc')
locations = soup.select('#infolist > div.infocon > table > tbody > tr > td.t > span.fl')
for title,img,price,detail,location in zip(titles,imgs,prices,details,locations):
print(title.text)
print(title.get('href'))
print(img.get('data-original')) if img.get('data-original') else print(img.get('src'))
print(price.text)
print(detail.text)
print(location.text) if len(location.text) != 0 else print('无')
infoTitle = title.text
infoDetailUrl = title.get('href')
infoImgUrl = img.get('data-original') if img.get('data-original') else img.get('src')
infoPrice = price.text
infoDetailText = detail.text
infoLocation = location.text if len(location.text) != 0 else '无'
list_info.insert_one({'title':infoTitle,
'detailUrl':infoDetailUrl,
'img':infoImgUrl,
'price':infoPrice,
'detailText':infoDetailText,
'location':infoLocation})
3.因每个链接入口都有不止一页,所以我们还需根据页数来爬去每一页的数据,另外就是利用CPU的多线程能力执行爬去代码,这样能高效的爬去数据
from multiprocessing import Pool
from pageList import get_list_info
from mainUrl import urlStr
#因为在观察赶集网的链接是我们发现o1..o2..是对应页面的页码,所有这里拼接每个页面的链接,这里以最多100页为测试
def get_all_list_info(url):
for p in range(1,100):
get_list_info(url + 'o' + str(p))
if __name__ == '__main__':#需加上这句代码,这时是一种固定的写法,作用是这句代码会把他上下分开两部分,避免我们改变地址时的名字混乱
# 创建一个进程池,所有我们设计的爬虫,都会被放到进程池内,然后自动分配系统资源来执行
# pool()有一个参数,processes,表示有多少个进程,比如processes=2
pool = Pool()
# 从所有频道列表中得到链接,
# map()函数:会把后面的集合一个一个的放到第一个函数中执行
# 参数1:一个函数
# 参数2:一个集合
pool.map(get_all_list_info,urlStr.split())
pool.close()
pool.join()
4.最后,我们实现一个每10秒查询一下数据库数据条数的程序,实时观看爬取进度
from pageList import list_info
import time
#每10秒查询一次数据库数据总数
while True:
print('数据库已写入--{}--条数据'.format(list_info.find().count()))
time.sleep(10)
至此,我们的爬虫程序已经完成了,上述每句关键代码都给出了详细的注释,应该不难理解。下面是执行程序的效果:
10W.gif
程序结束时:
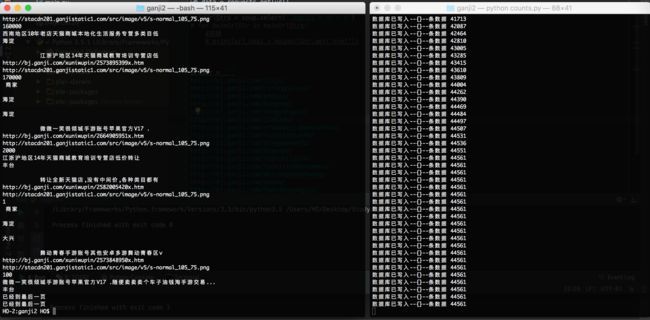
end.png