

The stochastic process to be controlled is described by the state transition probability density function f.




Once the first transition onto a next state has been made, π governs the rest of the action selection. The relationship between these two definitions for the value function is given by

With some manipulation, (2) and (3) can be put into a recursive form [18]. For the state value function, this is


These recursive relationships are called Bellman equations [7].

B. Average Reward


The Bellman equations for the average reward—in this case also called the Poisson equations [20]—are


Note that (8) and (9) both require the value J(π), which isunknown and hence needs to be estimated in some way. The Bellman optimality equations, describing an optimum for the average reward case, are

III. ACTOR-CRITIC IN THE CONTEXT OF REINFORCEMENT LEARNING



A prerequisite for this is that the critic is able to accurately evaluate a given policy. In other words, the goal of the critic is to find an approximate solution to the Bellman equation for that policy. The difference between the right-hand and left-hand sides of the Bellman equation, whether it is the one for the discounted reward setting (4) or the average reward setting (8), is called the TD error and is used to update the critic. Using the function approximation for the critic and a transition sample (xk ,uk ,rk+1 ,xk+1 ), the TD error is estimated as
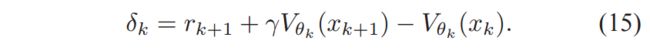








This clearly shows the relationship between the policy gradient ∇ϑJ and the critic function Qπ(x, u) and ties together the update equations of the actor and critic in the templates (19) and (20).











The product δkza,k in Equation (29e) can then be interpreted as the gradient of the performance with respect to the policy parameter.
Although no use was made of advanced function approximation techniques, good results were obtained. A mere division of the state space into boxes meant that there was no generalization among the states, indicating that learning speeds could definitely be improved upon. Nevertheless, the actor-critic structure itself remained and later work largely focused on better representations for the actor and the calculation of the critic。


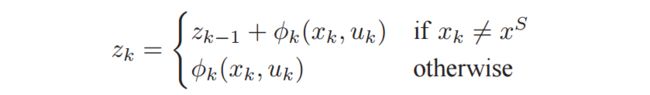

The update of the actor in Equation (31d) uses the policy gradient estimate from Theorem 2.
The update equations for the average cost and the critic are the same as Equations (31a) and (31c), but the actor update is slightly changed into
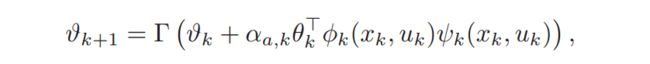

V. NATURAL GRADIENT ACTOR-CRITIC ALGORITHMS

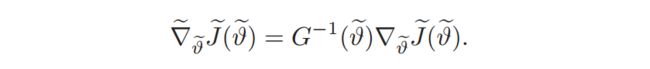
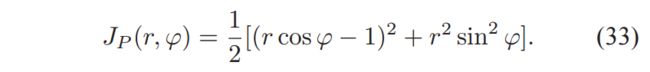

The natural gradient clearly performs better as it always finds the optimal point, whereas the standard gradient generates paths that are leading to points in the space which are not even feasible, because of the radius which needs to be positive.













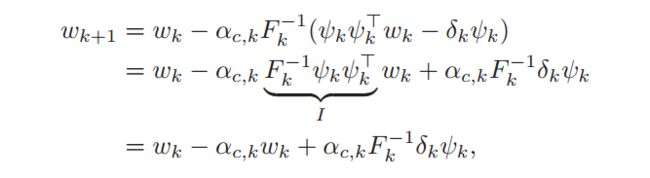


As shown above, the crucial property of the natural gradient is that it takes into account the structure of the manifold over which the cost function is defined, locally characterized by the Riemannian metric tensor.
To apply this insight in the context of gradient methods, the main question is then what is an appropriate manifold, and once that is known, what is its Riemannian metric tensor。For a manifold of distributions, the Riemannian tensor is the socalled Fisher information matrix (FIM) [75], which for the policy above is
