2.5 Ajax是什么? 有什么作用?
Ajax这个东西,很多童鞋在学习的时候都很茫然,听起来很高大上的赶脚,而且也看不懂的样子。其实则不然,Ajax很简单,AJAX 就是一个与服务器交换数据并更新部分网页的技术,并且是在不重新加载整个页面的情况下。如果您学过计算机网络基础的话,或者学过TCP/IP协议的话,网络通讯对于你来说轻而易举,分分钟搞定(因为http协议就是在TCP的基础上写的应用级协议)。
先将Ajax原生代码贴出来,使用了的XMLHttpRequest接口(目前应该都使用了xmlhttprequest level 2的接口了吧)
window.onload = function() {
function myajax (method, url, st, success, fail) {
// 1.创建一个Ajax的对象
var ajax = new XMLHttpRequest();
// 2.链接服务器
ajax.open(method, url, st);
// 3.发送请求
ajax.send();
// 4. 请求回调函数(当服务器给出响应时执行)
ajax.onreadystatechange = function() {
if(ajax.readyState == 4) {
if(ajax.status == 200) {
success(ajax.responseText);
}else if(ajax.status == 404) {
fail("请求文件不存在");
}
}
}
}
myajax('GET', 'a.txt', true, function(str) {
console.log(eval(str));
},function(str) {
});
}
这个就是原生js的Ajax的请求,这里要说明一下的是Ajax的请求的方式有很多,目前只学习POST和GET这两种方式来完成。至于两者区别,你们自行研究(So easy),下面咱们来说一下HTTP的返回状态码的总结。
2.6 HTTP返回状态码总结
状态码 | 描述
------------- | -------------
1xx | 请求收到,继续处理
2xx | 操作成功收到,分析、接受
3xx | 完成此请求必须进一步处理
4xx | 请求包含一个错误语法或不能完成
5xx | 服务器执行一个完全有效请求失败
1xx的状态码
状态码 | 描述
------------- | -------------
100(继续) | 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101(切换协议)| 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx的状态码
状态码 | 描述
------------- | -------------
200(成功) | 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
201(已创建) | 请求成功并且服务器创建了新的资源。
202(已接受) | 服务器已接受请求,但尚未处理。
203(非授权信息)| 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204(无内容) | 服务器成功处理了请求,但没有返回任何内容。
205(重置内容) | 服务器成功处理了请求,但没有返回任何内容。 与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容) | 服务器成功处理了部分 GET 请求。
3xx的状态码
状态码 | 描述
------------- | -------------
300(多种选择) | 针对请求,服务器可执行多种操作。 服务器可根据请求者(用户代理)选择一项操作,或提供操作列表供请求者选择。
301(永久移动) | 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 您应使用此代码告诉 Googlebot 某个网页或网站已永久移动到新位置。
302(暂时移动) | 服 务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 此代码与响应 GET 或 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个网页或网站已经移动,因为 Googlebot 会继续抓取原有位置并编入索引。
303(查看其他位置) | 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改) | 自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。如果网页自请求者上次请求后再也没有更改 过,您应当将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。 由于服务器可以告诉 Googlebot 自从上次抓取后网页没有更改过,因此可节省带宽和开销。
305(使用代理) | 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307(暂时重定向) | 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 此代码与响应 GET 和 HEAD 请求的 301 代码类似,会自动将请求者转到不同的位置,但您不应使用此代码来告诉 Googlebot 某个页面或网站已经移动,因为 Googlebot 会继续抓取原有位置并编入索引。
4xx状态码
状态码 | 描述
------------- | -------------
400(错误请求) | 服务器不理解请求的语法。
401(未授权) | 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403(禁止) | 服务器拒绝请求。 如果您看到 Googlebot 在尝试抓取您网站上的有效网页时收到此状态代码(可以在 Google 网站管理员工具诊 断 下的网络抓取 页面上看到此信息),可能是您的服务器或主机拒绝 Googlebot 访问。
404(未找到) | 服务器找不到请求的网页。 例如,如果请求服务器上不存在的网页,服务器通常会返回此代码。
405(禁用的方法) | 禁用请求中指定的方法。
406(不可接受) | 无法使用请求的内容特性响应请求的网页。
407(需要代理授权) | 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 如果服务器返回此响应,还会指明请求者应当使用的代理。
408(请求超时) | 服务器等候请求时发生超时。
409(冲突) | 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 服务器在响应与前一个请求相冲突的 PUT 请求时可能会返回此代码,同时会附上两个请求的差异列表。
410(已删除) | 如果请求的资源已永久删除,服务器就会返回此响应。 该代码与 404(未找到)代码相似,但在资源以前存在而现在不存在的情况下,有时会用来替代 404 代码。 如果资源已永久删除,您应当使用 301 指定资源的新位置。
411(需要有效长度) | 服务器不接受不含有效内容长度标头字段的请求。
412(未满足前提条件)| 服务器未满足请求者在请求中设置的其中一个前提条件。
413(请求实体过大) | 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414(请求的 URI 过长) | 请求的 URI(通常为网址)过长,服务器无法处理。
415(不支持的媒体类型) | 请求的格式不受请求页面的支持。
416(请求范围不符合要求) | 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417(未满足期望要求) | 服务器未满足”期望”请求标头字段的要求。
5xx状态码
状态码 | 描述
------------- | -------------
500(服务器内部错误) | 服务器遇到错误,无法完成请求。
501(尚未实施) | 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502(错误网关) | 服务器充当网关或代理,从上游服务器收到无效响应。
503(服务不可用) | 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
505(HTTP 版本不受支持) | 服务器不支持请求中所用的 HTTP 协议版本。
2.7 this指向问题?
this指向的这个问题网上很多文章说了一大堆,说到了重点,但是有点啰嗦。自认为只要一句话就行了。
this永远指向的是最后调用它的对象,也就是看它执行的时候是谁调用的
但是要注意的一点是:
this在严格模式下,默认的指向不是window而是undefined;
在真正开发中经常会使用var that = this, 来保存第一次执行环境下的this。(在ES6中箭头函数的this指向问题,箭头函数里的this是定义时所在的作用域,而不是运行时所在的作用域)
2.8 说一下作用域链是什么?
最近好几天要不在老家要不在学校,没有时间去更新, 今天有点时间,下面就谈谈作用域链。(网上的案例很多,我拿过来分析,并且将闭包放到这里来说明)
在JavaScript中,变量的作用域有全局作用域和局部作用域两种。
☆ 作用域链
在JavaScript中,函数也是对象,实际上,JavaScript里一切都是对象。函数对象和其它对象一样,拥有可以通过代码访问的属性和一系列仅供JavaScript引擎访问的内部属性。其中一个内部属性是[[Scope]],由ECMA-262标准第三版定义,该内部属性包含了函数被创建的作用域中对象的集合,这个集合被称为函数的作用域链,它决定了哪些数据能被函数访问。
1. 当一个函数创建后,它的作用域链会被创建此函数的作用域中可访问的数据对象填充。例如定义下面这样一个函数:
function add(num1, num2) {
var sum = num1 + num2;
return sum;
}
在函数add创建时,它的作用域链中会填入一个全局对象,该全局对象包含了所有全局变量(不要问我哪里产生了[[scope]],因为是自己生成的。),如下图所示(注意:图片只例举了全部变量中的一部分):
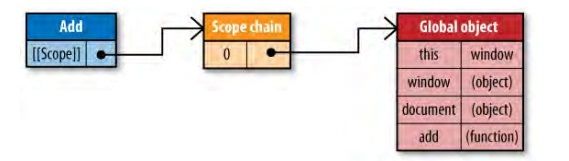
2. 当函数执行时,作用域链会发生变化的。
比如执行下列代码:
var total = add(5, 10);
执行此函数时会创建一个称为“运行期上下文(execution context)”的内部对象,运行期上下文定义了函数执行时的环境。每个运行期上下文都有自己的作用域链,用于标识符解析,当运行期上下文被创建时,而它的作用域链初始化为当前运行函数的[[Scope]]所包含的对象。
这些值按照它们出现在函数中的顺序被复制到运行期上下文的作用域链中。它们共同组成了一个新的对象,叫“活动对象(activation object)”,该对象包含了函数的所有局部变量、命名参数、参数集合以及this,然后此对象会被推入作用域链的前端,当运行期上下文被销毁,活动对象也随之销毁。新的作用域链如下图所示:

这里说明一下scope对象中的0的指向变成了活动对象,1的指向变成了全局对象。
3. 使用with和catch可以改变执行时期的作用域链
如果使用如下代码:
function initUI(){
with(document){
var bd=body,
links=getElementsByTagName("a"),
i=0,
len=links.length;
while(i < len){
update(links[i++]);
}
getElementById("btnInit").onclick=function(){
doSomething();
};
}
}
这里使用width语句来避免多次书写document,看上去更高效,实际上产生了性能问题。
当代码运行到with语句时,运行期上下文的作用域链临时被改变了。一个新的可变对象被创建,它包含了参数指定的对象的所有属性。这个对象将被推入作用域链的头部,这意味着函数的所有局部变量现在处于第二个作用域链对象中,因此访问代价更高了。如下图所示:

☆ 谈一下闭包(结合作用域链)
闭包其实就是一个函数在运行期间创建了另外一个函数。如下代码:
function outside() {
var a = 1;
function inside() {
console.log(a);
}
}

来说一下形成闭包的过程。当执行outside函数时, js引擎会创建outside函数的上下文的作用域链这个作用链包含了outside的执行时的活动对象和全局对象。当定义inside的时候,inside函数上的作用域链包含了两大块:outside函数的活动对象、全局对象。(当inside执行时,会在作用域链上增加一个新的对象,也就是它自身的活动对象。)
2.9 怎么阻止冒泡事件?
既然说到冒泡事件,那么就清晰去解析一下冒泡事件和捕获事件。(IE8及其IE8以下版本是不支持捕获事件的。)DOM的发展经历了DOM0、DOM2、DOM3三个版本。目前各个浏览器基本上支持DOM2的标准,所以咱们从DOM2的事件流来说起。
一般来说,事件流分为三个阶段: 捕获阶段、目标阶段.
、冒泡阶段。

1. 捕获阶段
事件的第一个阶段就是捕获阶段。事件从文档的根节点也就是window对象开始流向目标对象节点。(W3C规范是从Document出发,但是浏览器厂商都是从Window对象)途中经过各个层次的DOM节点,并在各个节点上触发捕获事件,直到到达事件的目标节点。捕获阶段的主要任务就是建立传播途径,在冒泡阶段,事件通过这个路径进行回溯到文档根节点。捕获事件就是在捕获阶段触发的事件,并执行相应的处理函数。
2.目标阶段
事件对象到达其事件目标。 这个阶段被我们称为目标阶段。一旦事件对象到达事件目标,该阶段的事件监听器就要对它进行处理。如果一个事件对象类型被标志为不能冒泡。那么对应的事件对象在到达此阶段时就会终止传播。
3.冒泡阶段
事件对象以一个与捕获阶段相反的方向从事件目标传播经过其祖先节点传播到window。这个阶段被称之为冒泡阶段。在此阶段注册的事件监听器会对相应的冒泡事件进行处理。
4. 实例验证事件流
Document
执行结果如下:
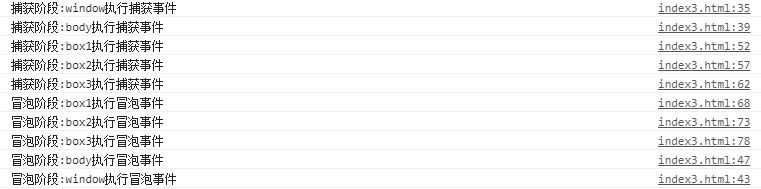 执行结果
执行结果
这里说明一下当执行到达目标阶段时,可能出现冒泡事件比捕获事件先执行,这种情况是因为冒泡事件比捕获事件先 注册。