github源码:https://github.com/dongniu0927/algorithm-hub/blob/master/%E4%BC%98%E5%8C%96%E7%AE%97%E6%B3%95/som.ipynb
概述
自组织映射网络(Self-organizing Mapping)是一种常用的聚类方法。
网络结构
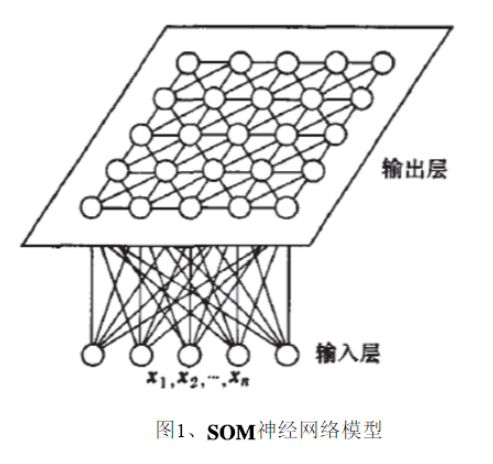
som_structure.png
它常分为输入层与竞争层(输出层)。
- 输入层:假设一个输入样本为X=[x1,x2,x3,…,xn],是一个n维向量,则输入层神经元个数为n个。
- 竞争层:通常输出层的神经元以矩阵方式排列在二维空间中,每个神经元都有一个权值向量,权值向量维度与输入层样本维度相同。假设输出层有m个神经元,则有m个权值向量。
注意上图中的$x_i$为第i个样本
算法步骤
- 初始化:初始化竞争层m的数目与m个元素的权值向量
- 输入比较:样本输入网络,通过比较样本与m个权值向量的相似性,记相似性最大的竞争层节点为获胜者
- 调整权值:更新获胜者节点的权值
- 循环迭代:重复2,3
初始化
每个竞争层节点的权值可以初始化为(0, 1)之间的随机数。
import random
def initOutputLayer(m, n): # m为竞争层节点数目;n为每一个节点的维度
layers = []
random.seed()
for i in range(m):
unit = [] # 每一个节点
for j in range(n):
unit.append(round(random.random(),2))
layers.append(unit)
return layers
m = 5
n = 2
layers = initOutputLayer(m, n)
print("Output layers:", layers)
Output layers: [[0.33, 0.71], [0.34, 0.84], [0.58, 0.68], [0.78, 0.67], [0.03, 0.05]]
输入比较
做比较之间可以先对所有的竞争层节点权值向量与输入向量归一化,然后再使用如欧式距离比较相似度。
竞争层第j个节点的权值归一化计算方式:$W_j=\dfrac{W_j}{||W_j||}$
输入向量归一化计算方式:$X=\dfrac{X}{||X||}$
两个维度都为n的向量之间的欧式距离计算方式:
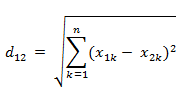
som_udistance.png
这里$X$与$W_j$都是n维向量
||X||为二范数,其代表该向量的长度,是一个标量
相似度比较函数可参考:https://www.cnblogs.com/liujinhong/p/6001997.html
import numpy.linalg as LA # 计算范数
import math
def normalization(v): # v为向量
norm = LA.norm(v, 2) # 计算2范数
v_new = []
for i in range(len(v)):
v_new.append(round(v[i]/norm,2)) # 保留2位小数
return v_new
def normalizationVList(X):
X_new = []
for x in X:
X_new.append(normalization(x))
return X_new
def calSimilarity(x, y): # 计算x,y两个向量的相似度
if len(x)!=len(y):
raise "维度不一致!"
c = 0
for i in range(len(x)):
c += pow((x[i] - y[i]), 2)
return math.sqrt(c)
def getWinner(x, layers): # 找到layers里面与x最相似的节点
# x = normalization(x)
# layers = normalizationVList(layers)
min_value = 100000 # 存储最短距离
min_index = -1 # 存储跟x最相似节点的竞争层节点index
for i in range(len(layers)):
v = calSimilarity(x, layers[i])
if v < min_value:
min_value = v
min_index = i
return min_index # 返回获胜节点index
# 输入数据处理
X = [[1, 2], [3, 4], [5, 6], [7, 8], [2, 3]] # 输入列表
X_norm = normalizationVList(X)
print("Inputs normalization:", X_norm) # 输入数据归一化
# 权值处理
layers_norm = normalizationVList(layers)
print("Weights normalization:", layers_norm) # 权值归一化
# 计算某一个x输入的竞争层胜利节点
winner_index = getWinner(X_norm[0], layers_norm)
print("Winner index:", winner_index)
Inputs normalization: [[0.45, 0.89], [0.6, 0.8], [0.64, 0.77], [0.66, 0.75], [0.55, 0.83]]
Weights normalization: [[0.42, 0.91], [0.38, 0.93], [0.65, 0.76], [0.76, 0.65], [0.51, 0.86]]
Winner index: 0
调整权值
竞争胜利的单元可以调整自己的权值,调整方式可以采用如下方式:
$w(t+1) = w(t) + \alpha(x-w(t))$
其中$\alpha$为学习率,它可以通过如下式子计算:
$\alpha=f(t)e^{-n}$ (其中f(t)为迭代次数的倒数)
def adjustWeight(w, x, alpha): # w为要调整的权值向量;x为输入向量;alpha为学习率
if len(w)!=len(x):
raise "w,x维度应该相等!"
w_new = []
for i in range(len(w)):
w_new.append(w[i] + alpha*(x[i] - w[i]))
return w_new
alpha = 0.5 # 学习参数
print("After Adjust:", adjustWeight(layers[winner_index], X[0], alpha))
After Adjust: [0.665, 1.355]
循环迭代
重复输入比较与调整权值,可以选择在以下条件成立时结束迭代:
- 学习率小于某个阈值
- 达到预设的迭代次数
整体代码
完整代码如下所示。
import random
import matplotlib.pyplot as plt
def createData(num, dim): # 数据组数与数据维度
data = []
for i in range(num):
pair = []
for j in range(dim):
pair.append(random.random())
data.append(pair)
return data
# 参数设置
train_times = 10 # 训练次数
data_dim = 2 # 数据维度
train_num = 160
test_num = 40
learn_rate = 0.5 # 学习参数
# 生成数据
random.seed()
# 生成训练数据
train_X = createData(train_num, data_dim)
# 生成测试数据
test_X = createData(test_num, data_dim)
# print(test_X)
# 初始化m个类
m = 3 # m个类别
layers = initOutputLayer(m, data_dim)
print("Original layers:", layers)
# 开始迭代训练
while train_times > 0:
for i in range(train_num):
# 权值归一化
layers_norm = normalizationVList(layers)
# 计算某一个x输入的竞争层胜利节点
winner_index = getWinner(train_X[i], layers_norm)
# 修正权值
layers[winner_index] = adjustWeight(layers[winner_index], train_X[i], learn_rate)
train_times -= 1
print("After train layers:", layers)
# 测试
for i in range(test_num):
# 权值归一化
layers_norm = normalizationVList(layers)
# 计算某一个x输入的竞争层胜利节点
winner_index = getWinner(test_X[i], layers_norm)
# 画图
color = "ro"
if winner_index == 0:
color = "ro"
elif winner_index == 1:
color = "bo"
elif winner_index == 2:
color = "yo"
plt.plot(test_X[i][0], test_X[i][1], color)
plt.legend()
plt.show()
No handles with labels found to put in legend.
Original layers: [[0.02, 0.89], [0.89, 0.51], [0.04, 0.37]]
After train layers: [[0.12821613475868407, 0.5612749329020781], [0.6869243400110778, 0.22710030600196837], [0.30010162064831547, 0.4166712478690186]]
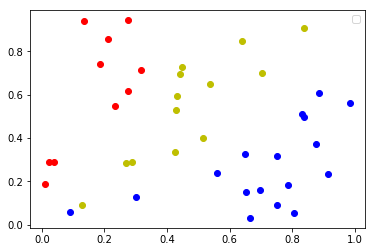
output_10_2.png