字符串讲解:
定义:双引号或者单引号中的数据,就是字符串
如name = 'abcdef',则有6个字符,下标name[0]='a',name[5]='f'
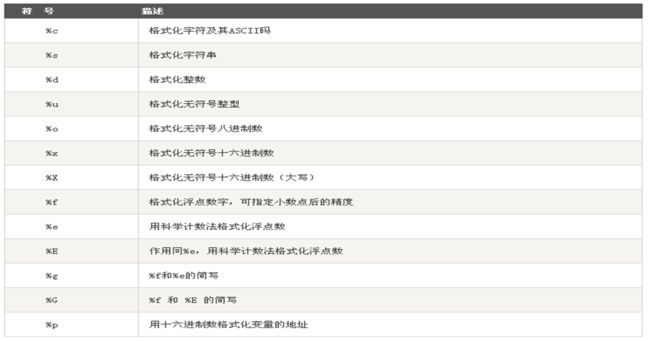
Paste_Image.png
转义字符:在需要在字符中使用特殊字符时,python用反斜杠()转义字符。
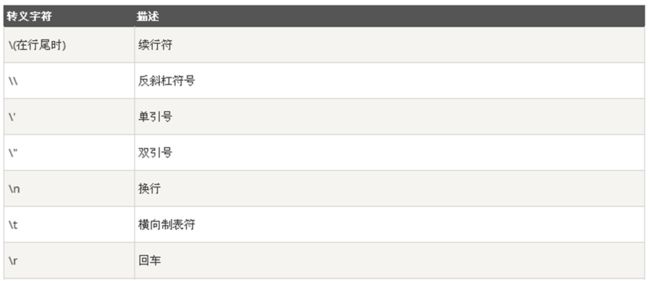
Paste_Image.png
运算符:
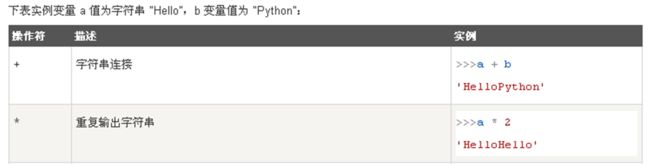
Paste_Image.png
字符串的查找:
1、string.find(str, beg=0, end=len(string))
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,
则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
2、string.rfind(str, beg=0, end=len(string))
类似于 find()函数,不过是从右边开始查找.
3、string.index(str, beg=0, end=len(string))
类似于 find()函数,但是找不到报异常.
4、string.rindex(str, beg=0, end=len(string))
类似于 rfind()函数,但是找不到报异常.
统计:
1、string.count(str, beg=0, end=len(string))
检测 str 是否包含在 string 中出现的次数,
如果 beg 和 end 指定范围,则检查是否包含在指定范围内
分隔:
1、string.split(str="", num=string.count(str))
以 str 为分隔符切片 string,如果 num有指定值,
则仅分隔 num 个子字符串
2、string.splitlines([keepends])
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,
如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
3、string.partition(str)
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,
把 字 符 串 string 分 成 一 个 3 元 素 的 元 组
(string_pre_str,str,string_post_str),如果 string 中不包含str
则 string_pre_str == string.
4、string.rpartition(str) 类似于 partition()函数,不过是从右边开始.
判断:
1、string.startswith(obj, beg=0,end=len(string))
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。
如果beg 和 end 指定值,则在指定范围内检查.
2、string.endswith(obj, beg=0,end=len(string))
检查字符串是否是以 obj 结尾,是则返回 True,否则返回 False。
如果beg 和 end 指定值,则在指定范围内检查.
3、string.isalnum() 所有字符都是字母或数字则返回 True,否则返回 False
4、string.isalpha() 所有字符都是字母则返回 True,否则返回 False
5、string.isdigit() 所有字符都是数字则返回 True,否则返回 False
6、string.isupper() 所有字符都是大写则返回 True,否则返回 False
7、string.islower() 所有字符都是小写则返回 True,否则返回 False
8、string.isspace() 只包含空格则返回 True,否则返回 False
大小写:
1、string.capitalize() 把字符串的第一个字符大写
2、string.upper() 转换 string 中的小写字母为大写
3、string.lower() 转换 string 中的大写字母为小写
对齐:
1、string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
2、string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
3、string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
裁剪:
1、string.strip([obj]) 删除 string 字符串前后的的obj,如果不传参数,删除前后空格
2、string.lstrip([obj]) 删除 string 字符串左面的obj,如果不传参数,删除左面空格
3、string.rstrip([obj]) 删除 string 字符串右面的obj,如果不传参数,删除右面空格
合并:
1、string.join(seq)
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)
合并为一个新的字符串
编码解码:
1、string.encode(encoding='UTF-8', errors='strict')
以 encoding 指定的编码格式编码 string,
如果出错默认报一个ValueError的异常,除非 errors 指定的是 'ignore' 或 者'replace'
2、bytes.decode(encoding='UTF-8', errors='strict')
以 encoding 指定的编码格式解码 string,
如果出错默认报一个ValueError的异常,除非 errors 指定的是 'ignore' 或 者'replace'
s = '哈哈'
#以什么编码,以什么解码,否则:乱码
#编码
b1 = s.encode('utf-8')
print(b1)
b2 = s.encode('gbk')
print(b2)
#解码
s1 = b1.decode('utf-8')
print(s1)
s2 = b2.decode('gbk')
print(s1)
运行结果:
b'\xe5\x93\x88\xe5\x93\x88'
b'\xb9\xfe\xb9\xfe'
哈哈
哈哈
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(65)
'A'
>>> chr(20013)
'A''
字符串的切片:
s = 'abcdefghijklmnopqrstuvwzxy'
print(len(s))
print(s[0])
print(s[-1])
print(s[-2])
print(s[0:7:2])
ls = list(s)
print(ls[0:7:2])
s1=''.join(ls[0:7:2])
print(s1)
运行结果:
26
a
y
x
aceg
['a', 'c', 'e', 'g']
aceg