如何让计算机理解人类的喜怒哀乐,根据大数据来定性定量分析人类情感,是大数据智能的重要体现。情感分析有着广泛的应用,如:舆情监控、客服监控、电商评价等。
1 情感分析研究什么问题
广义的情感分析又叫情感分析与观点挖掘,分为2个部分,即情感分析(狭义)和观点挖掘(又叫意见挖掘)。情感分析指通过分析文本来理解喜怒哀乐这些情感,观点挖掘偏重于理解用户表达的观点和意见,即判断一个句子有没有表达情感或观点。比如:
1)今天讲的是情感分析技术。
2)这本书写得很好。
3)我想看完这本书再去吃饭。
第1句是客观句,第2,3句是主观句,第2句又表达了褒义的情感色彩,第3句却没有褒贬色彩。
也就是说,情感分析是一个多步二分类问题,
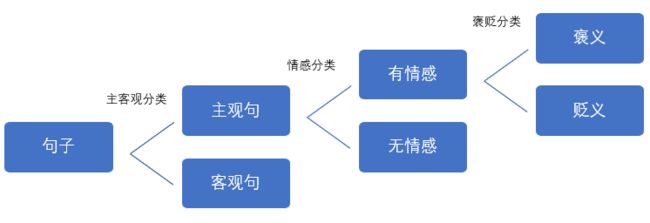
当然,有人说仅用褒贬2极来分类情感还不够,要用“喜怒哀乐”等情感词进行细分,无论怎样细分,归根结底,情感分析还是一个分类问题,这是情感分析要研究的第1个问题。
只是情感分类,对于某些场景显然不够用,比如:
4) 这部手机分辨率很高。
5)这部手机价格很高。
6) 这部手机续航时间不算差。
上面3句都表达褒义的情感,但作用对象并非人,而是某物(手机)的某个属性(分辨率、价格、续航时间),这里,表达的是人的观点,对观点表达的深入挖掘就是观点挖掘,这是情感分析的第2个问题。
在情感、观点分析的基础上,又衍生出一些新的情感分析问题,如:
l 舆情分析
针对公众舆论进行分析来判断公众情感倾向。
l 情感摘要
提取长文本的主要观点,以形成较短篇幅的摘要。
l 垃圾观点识别
互联网上的数据有很多虚假的数据,如雇佣水军写的垃圾数据。对这些垃圾观点进行识别并过滤,以获取更可信的数据。
2、情感分析研究问题的方法
2.1 情感分类问题研究方法
针对第1个问题,如何对一个句子进行情感分类呢?如果判断情感表达是褒义还是贬义呢?从上面的例句可以看出,情感词是表达情感的元素,如:“很好”、“很高”、“差”。因此,如果有一个收录各类情感词的情感词典,记录情感词、情感倾向甚至情感程度,那么,就可以按图索骥。从句子中找出所有情感词,按情感程度对情感倾向进行加权累计,就可以计算出整句话的情感倾向了。
关于情感词典,众多专家学者进行了研究。
l 美国的罗伯特教授提出了“情绪轮”模型
该模型包含8种基本情绪:生气、厌恶、恐惧、悲伤、期待、快乐、惊讶、信任

l 情绪的层次模型
l 我国的张伟编著了《学生褒贬义词典》
l 知网“情感分析用词语集”
l 清华大学构建的情感词词典
2.2 观点问题研究方法
情感词典法用于情感分类研究可行,但对于观点挖掘就不可行了。比如:“高”是褒义词,“分辨率很高”是褒义,但“价格很高”却是贬义。因此,情感词的感情倾向并不是始终如一的,要结合具体属性才能确定,这就形成了“特征-观点对”,识别“特征-观点对”是观点检索的一项基础工作。
到这时,观点的组成要素就若隐若现了,“观点”是多个要素组成的多元组:
l 观点持有者(holder)
即表达观点的主体
l 观点客体/对象
观点针对的对象,也是被评价的对象
l 对象的属性、特征
即对象的某个属性,用来显现某种观点
l 表达观点的极性
指观点是褒义或贬义,及情感程度。
观点问题研究比情感分类问题要复杂得多,不仅要知道观点的褒贬,还要知道观点的对象和属性。
观点挖掘通常包括包含几步,第一步叫观点抽取,从原始文本中识别和抽取对象的属性,并判断其极性,形成“属性-观点对”。第二步是情感资源构建将抽取的观点进行适当组织,形成结构良好的便于应用的知识,作为情感资源。最后一步就是观点检索 用户查询到某一种观点的相关信息(如:情感极性)。
2.3 情感分析方法
构建情感词典、属性-观点对这些情感资源,就是为了对文本进行情感分析,即识别文本表达了褒义、贬义还是中性,情感的强烈程度几何。
作为文本分类任务,情感分析方法又分为无监督学习和有监督学习。
1无监督学习
无监督学习就是无需训练语料,需要人工构建情感词典和属性-观点对库。然后对文本中的情感词、属性-观点对与已知库进行匹配,将匹配到的情感倾向得分累加,得出整个句子的总体情感倾向。如:
这部手机很靓,分辨率很高、续航时间也不算差、但是价格很高。
这句话的情感词有:靓,分辨率-高,续航时间-差(否定副词“不算”),价格-高。如果我们在情感库里设置好情感分数分别为0.6,0.4,-0.6, -0.8,因为续航时间-差有否定副词“不“(反转-1)和较弱程度副词 ”算”(除以弱化系数2),这里是较弱情感反转,情感得分:(-1)X (1/2)X (-0.6) = 0.3。同时,但是价格很高,有程度加强副词“但是”(乘以弱化系数2)。因而,整句情感倾向= 0.6 + 0.4 + 0.3 -0.8X2 = -0.3,表达了贬义情感。
2有监督学习
有监督学习的第一步就是找到训练数据,即已经标注出答案的语料。通过训练,模型就可以建立起特征与结果类别之间的分布关系,对未知答案的数据也能给出估计。
情感分析训练数据通常从互联网采集,如一些评论打分类网站,评价打分就相当于答案标注。对于一些内部系统,训练数据通常是满意度调查或人工复查、已评价的数据。
有监督学习的第二步是从文本中获取特征,将每个文本映射到一个向量。已有众多研究者对文本特征进行了研究,如:
l 词性特征
l 副词类特征
l 句法特征
l …
最后就是选取学习模型做分类器,情感分析常见的分类器有(这些技术我也不懂,先记上:) ):
l 朴素贝叶斯
l K近邻
l 支持向量机
l 最大熵模型